一种基于非易失内存的时序数据库日志存储方法及系统
本发明属于时序数据库日志存储,更具体地,涉及一种基于非易失内存的时序数据库日志存储方法及系统。
背景技术:
1、随着信息技术和物联网技术的发展,社交数据、交通流量、电商销售和服务器监控等时序数据呈现爆炸式增长。为了满足时序数据实时处理需求,时序数据库大多采用基于日志结构合并树(log-structured merge tree, lsm-tree)的存储结构,在内存(dynamicrandom accessmemory, dram)中将时序数据的随机写转化为顺序写,以提升i/o性能和数据库吞吐量。然而,由于dram的断电易失特性,一旦系统发生故障,dram中存储的数据将全部丢失。为了实现数据的持久化存储,时序数据库通常采用写前日志(write-ahead log,wal),在事务提交之前,首先生成对应的日志,在事务的日志持久化存储后,再完成事务提交。当系统发生故障时,时序数据库可以通过wal来对数据进行恢复,从而避免数据丢失。从事务的执行过程可以看出,日志的写入性能直接影响了数据库的吞吐量,如何通过优化日志性能来提升时序数据库的吞吐量,是设计时序数据库日志系统及持久化方法时需要考虑的。
2、传统的关系型数据库为了保证事务的原子性、一致性、隔离性和持久性(atomicity, consistency, isolation, and durability, acid),需要记录事务识别号(transactionidentity document, tid)和每条日志的编号(log sequence number,lsn),以确保wal持久化存储的顺序与事务执行顺序保持一致,从而在故障恢复时,能够按照lsn顺序执行故障恢复,将数据库恢复一致性状态。时序数据库为了保证时序数据的写入性能,通常不支持acid,但仍然需要保证wal记录的顺序与事务逻辑上的执行顺序保持一致,比如influxdb2.x版本不支持对数据直接进行更新,只能通过先删除数据,再重新写入,来变相实现数据更新,如果日志不能反映数据删除和插入的顺序,则无法使用wal将时序数据库恢复一致性状态。
3、现有数据库大多采用中心化的日志结构,很大程度上制约了数据库的性能和扩展能力。有文献研究指出,在shore数据库存储引擎上,日志和缓存管理至少产生了50%的开销。为了提升wal的性能,大量研究基于固态硬盘(solid state disk, ssd)和机械硬盘(hard disk drive, hdd)等块存储介质,设计了去中心化的日志结构,来提升wal性能和数据库扩展能力。然而,受限于ssd/hdd的i/o性能,wal仍然是影响数据库吞吐量的重要原因之一。
4、近年来,有研究基于非易失内存(non-volatile memory, nvm)来提升wal的i/o性能,这些研究主要分为两类:一类采用dram+nvm+ssd/hdd的三层架构,将wal存储在nvm上,从而提升数据库的吞吐量;比如,有研究在在nvm上使用硬件日志来提升事务持久化存储的可靠性,然而,这将产生额外的开销。另一类设计了dram+nvm的两层架构,将整个数据库存储系统放在nvm上,dram作为缓存;比如,有研究基于dram+nvm两层架构设计了无wal的存储引擎,然而,nvm的随机写性能与顺序写性能相差2至7倍,这种方法无法发挥nvm的最大性能;并且也有研究证明如果不重新设计软件的i/o接口,直接使用nvm替代ssd/hdd,将导致更大的系统开销。
5、并且,现有的基于非易失内存nvm来提升wal的方法都需要大量使用内存屏障来保证日志写入nvm的正确性,并且都是针对关系型数据库的wal进行优化,未考虑时序数据的特征,无法直接应用于时序数据库;事实上,时序数据事务与传统关系型数据库的在线事务处理(online transaction processing, oltp)有很大不同,在现实场景中,大部分时序数据库事务是数据写入事务,并且数据更新事务之间的依赖关系很少,这些特征是设计时序数据库日志系统时不可忽略的因素。虽然现有的时序数据库对wal进行了一定的优化,但是这些优化都是针对ssd/hdd等块存储介质,并未利用nvm的特点及性能。
技术实现思路
1、针对现有技术的缺陷和改进需求,本发明提供了一种基于非易失内存的时序数据库日志存储方法及系统,其目的在于实现时序数据库日志在非易失内存上的持久化存储,并提升时序数据库的性能。
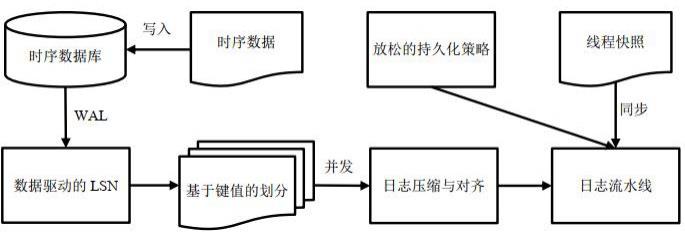
2、为实现上述目的,按照本发明的第一方面,提供了一种基于非易失内存的时序数据库日志存储方法,包括:
3、s1、根据时序数据库中事务访问的数据计算当前事务日志的lsn;
4、s2、按照日志中记录的数据键值将当前日志划分到对应的线程,并引入线程快照根据计算得到的日志lsn进行线程同步;
5、s3、将当前日志压缩后按照非易失内存nvm最小写入单元对齐;
6、s4、针对每个线程,以流水线形式将日志并发写入nvm;
7、其中,s1包括:
8、 s11、对事务访问数据中的时间戳字段进行扩展,得到扩展时间戳,所述扩展时间戳从高位到低位包括:数据锁、墓碑标记及数据修改时间戳uts,数据锁用于实现事务的并发控制,墓碑标记用于记录本条数据是否被删除;
9、s12、用所述uts设计lsn计算协议:
10、每条新插入数据的uts初始化为0;
11、写入事务日志的lsn为0;
12、更新事务日志的;表示当前事务访问数据集合中uts的最大值;表示中任一数据点的uts;
13、事务提交前,将所有被修改数据的uts原子更新为当前事务日志的lsn。
14、进一步地,s1中,采用所述lsn计算协议计算更新事务日志的lsn,包括:
15、第一步,读取当前事务需要访问数据的扩展时间戳,若访问的当前数据的数据锁为1,则等待;否则,计算需要访问数据中所有扩展时间戳的最大值,并计算当前事务的lsn,;
16、第二步,再次读取需要访问数据的数据锁,若数据锁为0,则将数据锁置1;否则,终止当前事务,重新开始执行当前事务,直至此时的数据锁为0,并将锁位置1;
17、第三步,比较需要访问数据此时的uts是否与第一步读取的对应数据的uts相同,若不同,终止当前事务,重新开始执行当前事务,直至数据此时的uts与第一步读取的对应数据的uts相同,将需要访问数据的uts修改为当前事务的lsn,并将数据锁置0;针对删除操作,将墓碑标记置1。
18、进一步地,s4包括:
19、s41、针对每个线程,维护n个日志队列,逻辑上构成循环链表,初始化所有日志队列为空;
20、s42、事务提交时,若事务日志的lsn=0,则将事务日志直接写入当前队列的缓冲区,继续处理后续事务日志;否则,将事务日志写入当前队列后,关闭当前队列,使后续事务日志写入下一个日志队列;
21、s43、事务日志按照s42中原则循环写入队列,当队列关闭时,将后续事务日志写入队列;
22、s44、将写入队列的日志以流水线形式写入nvm。
23、进一步地,所述s44包括:
24、日志线程从队列至依次处理日志,采用clwb指令将当前队列中的写入事务日志写入nvm;
25、若当前队列中存在更新事务日志,则先进行线程同步,再对所述更新事务日志使用内存屏障;在当前队列中内存屏障执行的同时,日志线程将下一队列中的写入事务日志并发写入nvm;
26、若下一队列中存在更新事务日志,先进行线程同步,再对所述更新事务日志使用内存屏障,并且使当前队列中的更新事务日志和下一队列中的更新事务日志按先后顺序写入nvm。
27、进一步地,s2中,引入线程快照根据计算得到的日志lsn进行线程同步,包括:
28、s21、构建线程快照的数据结构,所述数据结构包括m×n的日志数量数组和lsn数组;其中,m表示日志线程数,n表示每个日志线程维护的队列数;数组用于记录每个队列写入的更新事务日志数量,数组用于记录每个线程中队列当前处理日志的最大lsn;对于队列,当其中的日志lsn大于0时,,且日志写入nvm后,将增加1,并将置为0;
29、s22、进行日志线程同步:对于当前的更新事务,通过数组获取当前各日志队列的最大lsn,若数组中的lsn都为0或者都大于等于当前更新事务的lsn,则将当前更新事务日志写入nvm;否则,当前更新事务日志循环等待,直到数组中的lsn都大于等于当前更新事务日志的lsn为止。
30、进一步地,s3中,将当前日志压缩,包括:
31、s31、以时序数据库中时间序列的键值为键值,以对应日志的字符编码、整型字段、差值、浮点字段、浮点数编码以及日志元信息为value,构建哈希表;
32、s32、对于每条日志,使用1位的压缩标志用于记录日志是否被压缩,在当前日志写入nvm之前,查看当前日志中数据的键值是否包含在所述哈希表中,若是,则读取所述哈希表的原始数据对当前日志进行压缩,并将当前日志的压缩标志位置1;否则,将当前日志中的数据写入所述哈希表中,并将当前日志的压缩标志位置0。
33、进一步地,s32中,针对当前日志中的时间序列键值,采用字典编码进行压缩;
34、针对当前日志中的时间戳,采用delta-of-delta编码进行压缩;
35、针对当前日志中的浮点型数据,采用异或编码进行压缩。
36、进一步地,还包括:当s1中计算得到的lsn溢出时,执行检查点操作,包括:将脏数据落盘、删除旧日志、记录检查点日志以及重置所有数据点的扩展时间戳为0;
37、所述检查点日志包括:检查点执行的时间段和lsn更新时间,检查点执行时间段内的日志以及哈希表。
38、进一步地,还包括:当数据库出现故障时,按照lsn的大小顺序重做日志,以进行故障恢复,包括:
39、读取nvm中存储的日志并解析:若无检查点日志,则读取当前哈希表对日志解压;若包含检查点日志,则读取检查点起始时间、及lsn更新时间,并分别读取检查点哈希表和当前哈希表,从所述检查点日志中记录的日志起始地址开始,依次读取日志记录,数据时间戳在以前的日志使用检查点哈希表解压,数据时间戳在以后的日志使用当前哈希表解压;
40、对记录在检查点日志中之前的日志和之后的日志分别进行分类:在内存中建立个缓冲区,为扩展时间戳中uts所能表示的最大lsn;若解析后的日志lsn为0,直接恢复至内存;否则,当时,将日志写入第个缓冲区;
41、恢复更新事务日志:若无检查点日志,将所有日志按照lsn由小到大的顺序执行redo操作;否则,则先后对以前的日志和以后的日志,按照lsn编号由小到大的顺序,依次对缓冲区中的日志执行redo;redo操作后将内存中恢复的数据写入硬盘。
42、按照本发明的第二方面,提供了一种基于非易失内存的时序数据库日志存储系统,包括计算机可读存储介质和处理器;
43、所述计算机可读存储介质用于存储可执行指令;
44、所述处理器用于读取所述计算机可读存储介质中存储的可执行指令执行第一方面任一项所述的方法。
45、总体而言,通过本发明所构思的以上技术方案,能够取得以下有益效果:
46、(1)本发明的基于非易失内存的时序数据库日志存储方法,对于时序数据库的每个事务,首先通过事务访问的数据计算当前事务日志的lsn,然后按照事务日志的键值将当前日志划分到日志线程,每个日志线程通过压缩算法对日志进行压缩并进行日志对齐,最后以流水线方式将日志写入非易失内存nvm。本发明首次实现了在nvm中持久化存储时序数据库日志,充分利用nvm本身的性能,提高了时序数据库的吞吐量,缩短了故障恢复时间,提升了时序数据库性能。
47、针对时序数据写多、更新少的特点,对每条数据中自带的时间戳进行设计得到扩展时间戳数据结构及lsn计算协议,针对时序数据库中较多的写入事务,直接设计其日志的lsn为0,使得写入事务可以直接并发写入,提升写入效率,其日志存储顺序和故障恢复顺序不影响数据库一致性;针对更新事务,根据设计的扩展时间戳计算lsn,并保证了事务的冲突可串行化,同时,规定了数据扩展时间戳的初始值与时序数据的原始时间戳一致,不需要额外的操作对其扩展时间戳进行修改;本发明的这种通过事务访问的数据来计算日志的lsn,基于此来捕获事务之间的依赖关系和确定日志顺序,避免了中心化的日志lsn计算方法导致的事务并发争用开销,提升了时序数据库的性能。
48、(2)进一步地,本发明的流水线部分针对每个线程构建n个日志队列,以异步方式处理事务日志。针对写入事务,直接将其并发写入当前队列,无需内存屏障,而针对更新事务,将其写入当前队列后,关闭当前队列,使后续事务日志写入下一个队列,可以保证在同一时间内,至少有一个日志队列处于工作状态,减小非必要的内存屏障;本发明的这种通过日志流水线将日志并发写入nvm,与传统基于nvm的日志系统相比,避免了非必要的内存屏障,提升日志持久化存储性能。
49、(3)进一步地,本发明所采用的多线程日志方法,根据日志中数据的键值将日志划分到不同的日志线程,通过日志线程快照对多线程日志进行同步,减小了同步开销。
50、(4)进一步地,本发明根据时序数据采集周期相对稳定、相同键值的时序数据波动范围较小的特点,通过哈希表对日志的不同字段进行分类压缩,将日志按照nvm最小写入单元对齐后再写入nvm,然后再将日志对应的事务批量提交,减小了日志的空间开销和写放大对nvm写入性能的影响。
51、总而言之,本发明的方法考虑到在现实场景中,大部分时序数据库事务是数据写入事务,并且数据更新事务之间的依赖关系很少,基于这些特征设计时序数据库日志存储系统,克服了现有基于nvm的数据库日志系统未考虑时序数据特征且大量依赖内存屏障的缺陷,能够改进时序数据库日志性能,从而提升时序数据库吞吐量,缩短故障恢复时间,本发明的方法可用作各类时序数据库通用的日志系统。
- 还没有人留言评论。精彩留言会获得点赞!