针对终端训练模型的内存优化方法、系统、设备及介质与流程
本技术实施例涉及数据处理,具体而言,涉及一种针对终端训练模型的内存优化方法、系统、设备及介质。
背景技术:
1、深度神经网络已经成为了移动设备上面智能应用的主要构件,现在有非常多的由深度学习赋能的应用,比如说语音助手、增强现实等。现在移动设备上面的芯片的计算能力日益增强,同时学术领域也涌现了一大批深度神经网路的优化算法,这些技术和硬件的发展使得深度神经网络的推理预测过程越来越多地在移动设备上面进行,避免了高额的分载开销。
2、更进一步的,终端学习技术逐渐成为了一种新的学习模式,这种技术直接使用移动设备进行模型训练,实现了非常好的模型个性化以及很好地保护了隐私数据。同时现有的一些深度学习的方法,比如联邦学习、分割学习等,这些技术使用终端学习技术作为关键构件,利用终端设备训练本地数据。但是终端设备上面的资源是非常有限的,比如算力、内存等,无法满足深度神经网络训练的资源需求。
3、针对模型训练过程中内存受限的问题,现有的一些研究工作都是针对服务器和图形处理器(gpu)的,缺乏针对终端设备和中央处理器(cpu)的。现有的技术中主要是面向gpu,包含模型压缩、重计算、数据交换等,但是其中一些技术对终端设备并不适用。首先是数据交换,现有的技术主要是在gpu和cpu之间进行数据交换,即现存和主存储器之间的数据交换,这样的数据交换主要通过高速的pcie接口或者nvlink接口实现,通过这些接口,数据传输的效率可以达到每秒数十兆字节,但是在终端设备上面缺乏这类高速读写硬件、数据的交换只能通过硬盘实现,数据的读写速度受限,无法满足模型训练的需求。此外是模型压缩,这种技术通常使用低精度的模型表示,但是这种方法通常是以模型性能的损耗作为代价的,并且通过实验我们发现在联邦学习的场景下面模型压缩带来的性能损耗非常明显。
技术实现思路
1、本技术实施例提供一种针对终端训练模型的内存优化方法、系统、设备及介质,旨在训练模型的过程中减少训练所占据的内存。
2、第一方面,本技术实施例提供一种针对终端训练模型的内存优化方法,所述方法包括:
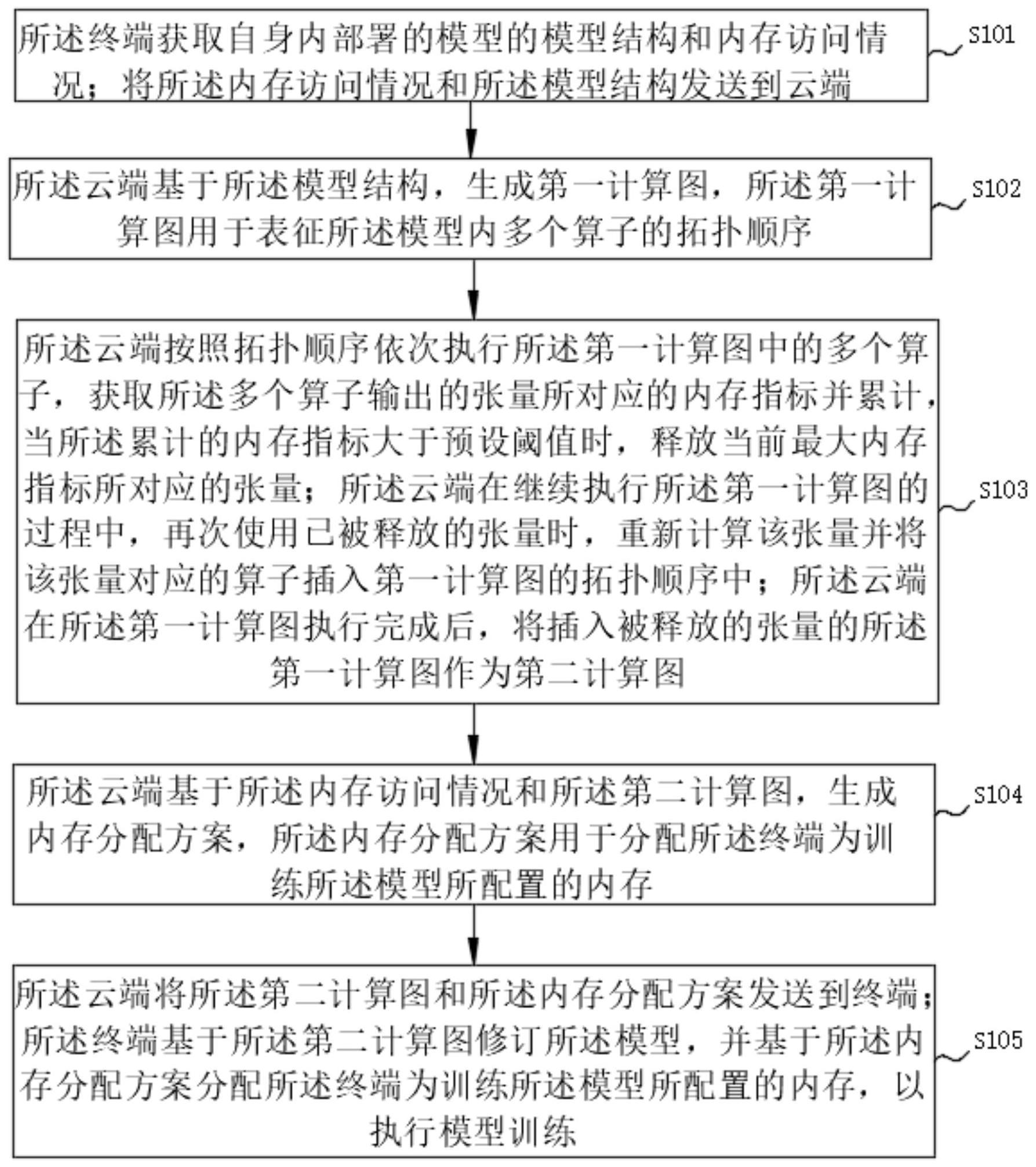
3、所述终端获取自身内部署的模型的模型结构和内存访问情况;
4、将所述内存访问情况和所述模型结构发送到云端;
5、所述云端基于所述模型结构,生成第一计算图,所述第一计算图用于表征所述模型内多个算子的拓扑顺序;
6、所述云端按照拓扑顺序依次执行所述第一计算图中的多个算子,获取所述多个算子输出的张量所对应的内存指标并累计,当所述累计的内存指标大于预设阈值时,释放当前最大内存指标所对应的张量;
7、所述云端在继续执行所述第一计算图的过程中,再次使用已被释放的张量时,重新计算该张量并将该张量对应的算子插入第一计算图的拓扑顺序中;
8、所述云端在所述第一计算图执行完成后,将插入被释放的张量的所述第一计算图作为第二计算图;
9、所述云端基于所述内存访问情况和所述第二计算图,生成内存分配方案,所述内存分配方案用于分配所述终端为训练所述模型所配置的内存;
10、所述云端将所述第二计算图和所述内存分配方案发送到终端;
11、所述终端基于所述第二计算图修订所述模型,并基于所述内存分配方案分配所述终端为训练所述模型所配置的内存,以执行模型训练。
12、可选地,所述获取所述终端内模型的模型结构和内存访问情况,包括:
13、所述终端统计所述模型的算子种类、算子数量和算子中张量的输入输出;
14、所述终端统计所述模型训练过程中内存的访问和释放时间及访问内存的大小。
15、可选地,所述获取所述多个算子输出的张量所对应的内存指标,包括:
16、获取所述张量的节约内存和重获时间;
17、所述张量的节约内存与所述重获时间之商即所述张量的内存指标。
18、可选地,所述云端基于所述内存访问情况和所述第二计算图,生成内存分配方案,包括:
19、在计算所述第二计算图时,每存在二个算子计算产生张量,即获取所述张量的内存占用量;
20、每多获取一个所述第一计算图中算子计算产生的张量,均与已经获取的张量的内存占用量进行对比并按照从大到小的顺序排序;
21、基于所述多个张量的内存占用量排列顺序,将所述云端上的模拟内存按二维装箱方法分配给所述张量,所述模拟内存与所述终端中为训练所述模型所配置的内存大小相同;
22、基于所述云端上模拟内存的分配情况,生成所述内存分配方案。
23、可选地,所述基于所述多个张量的内存占用量排列顺序,将所述云端上的模拟内存按二维装箱方法分配给所述张量,包括:
24、在为所述多个张量分配模拟内存时,优先将所述模拟内存中内存地址最小的内存分配给多个张量中内存占用量最大的张量。
25、可选地,所述终端基于所述第二计算图修订所述模型,并基于所述内存分配方案分配所述终端为训练所述模型所配置的内存,包括:
26、所述终端基于所述第二计算图,重新排布所述模型内的多个算子的拓扑顺序;
27、获取所述终端为训练所述模型所配置的内存,并基于所述内存分配方案,为所述第二计算图计算生成的每个张量所占用的内存设置内存地址偏移量。
28、第二方面,本技术实施例提供一种针对终端训练模型的内存优化系统,所述系统包括统计模块、第一计算图生成模块、第二计算图生成模块、内存分配方案生成模块和执行模块;
29、统计模块,用于所述终端获取自身内部署的模型的模型结构和内存访问情况;并将所述内存访问情况和所述模型结构发送到云端;
30、第一计算图生成模块,用于所述云端基于所述模型结构,生成第一计算图,所述第一计算图用于表征所述模型内多个算子的拓扑顺序;
31、第二计算图生成模块,用于所述云端按照拓扑顺序依次执行所述第一计算图中的多个算子,获取所述多个算子输出的张量所对应的内存指标并累计,当所述累计的内存指标大于预设阈值时,释放当前最大内存指标所对应的张量;所述云端在继续执行第一计算图的过程中,再次使用已被释放的张量时,重新计算该张量并将该张量对应的算子插入第一计算图的拓扑顺序中;所述云端第一计算图执行完成后,将插入被释放的张量的第一计算图作为第二计算图;
32、内存分配方案生成模块,用于所述云端基于所述内存访问情况和所述第二计算图,生成内存分配方案,所述内存分配方案用于分配所述终端为训练所述模型所配置的内存;
33、执行模块,用于所述云端将所述第二计算图和所述内存分配方案发送到终端;所述终端基于所述第二计算图修订所述模型,并基于所述内存分配方案分配所述终端为训练所述模型所配置的内存,以执行模型训练。
34、第三方面,本技术实施例提供一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行如实施例第一方面所述的一种针对终端训练模型的内存优化方法。
35、第四方面,本技术实施例提供一种计算机可读存储介质,所述计算机可读存储介质上存储计算机程序,所述计算机程序被处理器执行时实现如实施例第一方面所述的一种针对终端训练模型的内存优化方法。
36、有益效果:在训练模型时,云端能够通过模型结构和内存访问情况生成第一计算图,并通过对第一计算图进行计算,得到模型训练过程中产生的多个张量,多个产生的张量是模型训练过程中占据内存较大的原因,所以本技术通过设置预设阈值,当云端对第一计算图中多个算子进行计算时,若是当前已产生的张量所占据的内存超出预设阈值,就暂时先将内存指标最大的张量释放,从而减少内存指标最大的张量占据的内存;在需要再次使用到该张量时,又重新计算该张量对应的算子并将该张量对应的算子插入到第一计算图中形成第二计算图,则终端在训练模型时,在第二计算图中多个张量超出预设阈值时便释放内存指标最大的张量与重新计算该张量的过程中,减少内存指标最大张量所占据的内存;且通过内存访问情况和第二计算图生成的内存分配方案能够为多个训练过程中产生的张量分配内存,从而达到减少模型训练过程中模型占据内存的效果。
- 还没有人留言评论。精彩留言会获得点赞!