基于循环转换器和历史感知的视觉对话方法、装置及设备
本发明涉及人工智能神经网络模型领域,尤其是一种基于循环转换器和历史感知的视觉对话方法、装置及设备。
背景技术:
1、视觉对话任务要求对话代理回答一系列以图像为基础的问题,视觉对话不仅需要根据文本理解图像语义,还需要通过对话历史进行推理。现有技术大多集中在开发各种注意力机制,以建立包括图像、标题、问题和对话历史等实体之间的互动模型。为了获取预训练的视觉语言转换器的强大表示能力,现有的视觉对话模型,如visdial-bert、vd-bert、icmu和utc,适应各种预训练的视觉语言模型以实现新的性能记录。visdial-bert是一个基于bert的模型,在视觉语言数据集上进行预训练,然后在visdial数据集上进行微调。vd-bert使用一个单流的转换器编码器捕捉图像和多轮对话之间的所有互动关系。utc提出了一个基于对比学习的框架,用一个单一的模型来统一和促进视觉对话中的判别和生成任务。icmu通过四向对比学习加强了跨模态的理解。alignvd通过无监督和伪监督的视觉-语言对齐损失来预训练视觉和对话编码器。
2、受bert等大规模预训练语言模型在各种下游自然语言处理任务中的成功启发,目前有许多关于扩展bert的研究,通过对大规模图像-文本对进行预训练模型来提高下游视觉-语言任务的性能,如vilbert、vl-bert以及blip等。然而,这些方法大多使用从网络上抓取的一般大规模图像和文本对,缺乏图像和对话历史之间的对齐能力。此外,这些方法并不是为视觉对话而设计的,所以将它们应用到视觉对话任务中来捕捉时间上的依赖性是不理想的。以前的方法(如blip)对整个对话的学习是粗略的,只将对话历史中的所有话语串联起来作为对话历史,并通过交叉注意或多模态转换器直接与视觉信息互动。这意味着这些作品希望只通过一次性的多模态交互来提取足够的信息来回答当前的问题。但是现有技术忽略了多轮对话系统的顺序性和对话历史中固有的时间依赖性,这是多轮对话的一个明显特征,对代理人学习多模态信息的时间依赖性以准确预测反应至关重要。因此现有技术很容易忽视对话历史中的详细信息,不能给出准确的答案。
3、现有预训练的视觉对话模型在视觉对话任务中存在以下问题:视觉对话的时间依赖性较低;不同模态的特定特征之间协调语义存在困难,导致视觉对话难以满足多模态的互动和理解。
技术实现思路
1、有鉴于此,本发明实施例提供一种基于循环转换器和历史感知的视觉对话方法、装置及设备,以提高视觉对话的时间依赖性和准确性。
2、本发明实施例的一方面提供了一种基于循环转换器和历史感知的视觉对话方法,包括:
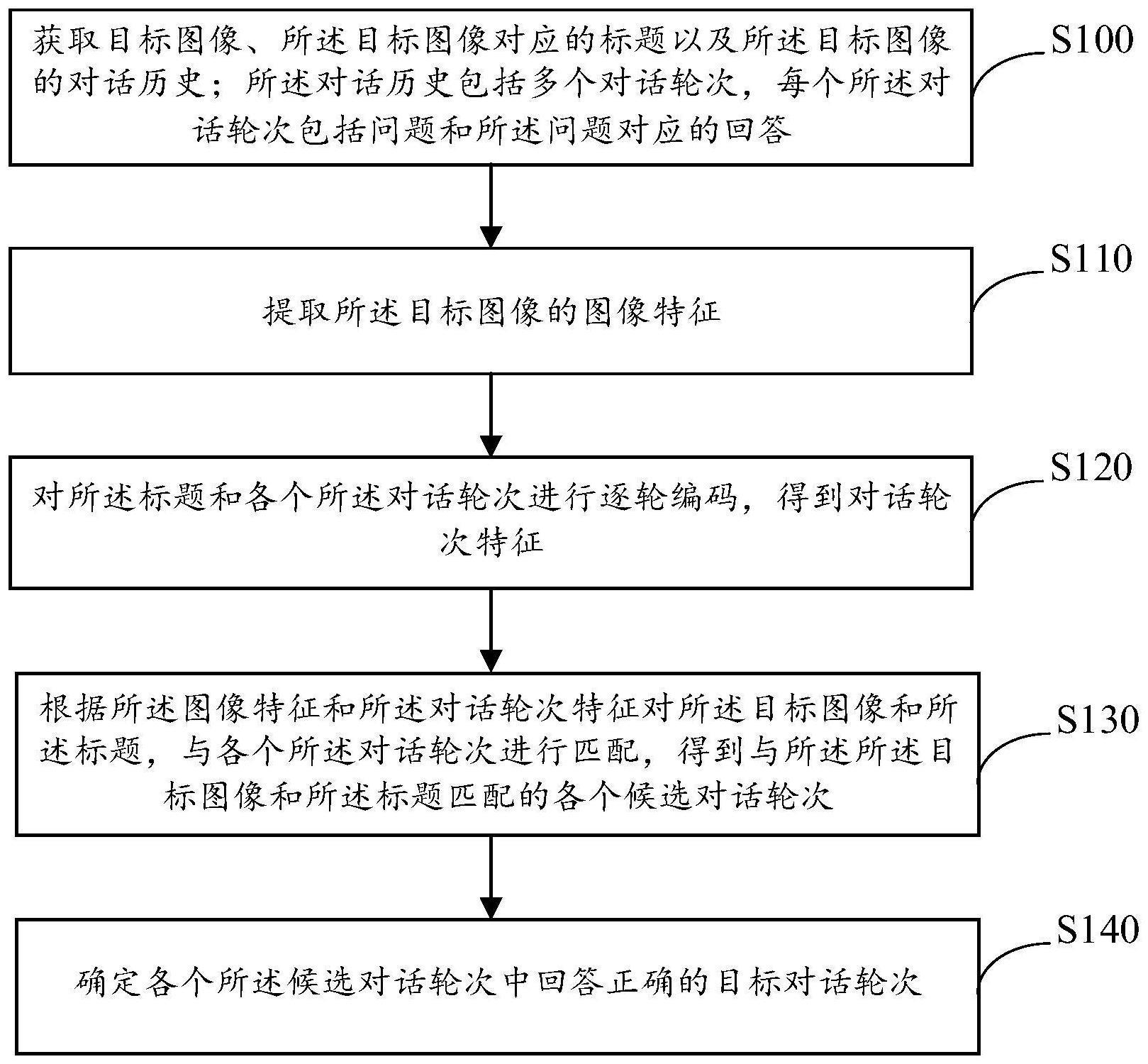
3、获取目标图像、所述目标图像对应的标题以及所述目标图像的对话历史;所述对话历史包括多个对话轮次,每个所述对话轮次包括问题和所述问题对应的回答;
4、提取所述目标图像的图像特征;
5、对所述标题和各个所述对话轮次进行逐轮编码,得到对话轮次特征;
6、根据所述图像特征和所述对话轮次特征对所述目标图像和所述标题,与各个所述对话轮次进行匹配,得到与所述目标图像和所述标题匹配的各个候选对话轮次;
7、确定各个所述候选对话轮次中回答正确的目标对话轮次。
8、可选地,所述提取所述目标图像的图像特征,包括:
9、调整所述目标图像的尺寸并将调整尺寸后的所述目标图像划分为多个令牌;
10、将多个所述令牌输入预先设置的图像编码器,得到所述图像特征。
11、可选地,所述对所述标题和各个所述对话轮次进行逐轮编码,得到对话轮次特征,包括:
12、对所述标题中所有的词,以及每个所述对话轮次中所有的词进行标记,得到标记序列;
13、在所述标记序列的开头添加表示开始编码的代号,在所述标记序列的结尾添加表示结束编码的代号;
14、对所述标记序列进行逐轮编码,得到所述对话轮次特征。
15、可选地,所述对所述标记序列进行逐轮编码,得到所述对话轮次特征,包括:
16、将所述标记序列输入预先配置的循环对话编码器,得到所述对话轮次特征;
17、所述循环对话编码器的表达式为:
18、
19、其中,ht表示所述对话轮次特征,是所述循环对话编码器的输入,是所述循环对话编码器中交叉注意模块的输入,其中fi是所述图像特征,是第0回合到第t-1回合的对话历史特征。
20、可选地,所述根据所述图像特征和所述对话轮次特征对所述目标图像和所述标题,与各个所述对话轮次进行匹配,得到与所述目标图像和所述标题匹配的各个候选对话轮次,包括:
21、确定每个所述对话轮次特征到所述图像特征的第一相似度,确定所述图像特征到每个所述对话轮次特征的第二相似度;
22、对所述第一相似度和所述第二相似度进行加权求和,得到对比损失相似度;
23、根据所述对比损失相似度对所述目标图像和所述标题,与各个所述对话轮次进行匹配,得到与所述目标图像和所述标题匹配的各个候选对话轮次。
24、可选地,所述确定每个所述对话轮次特征到所述图像特征的第一相似度,确定所述图像特征到每个所述对话轮次特征的第二相似度,包括:
25、根据第一表达式确定每个所述对话轮次特征到所述图像特征的第一相似度;
26、所述第一表达式为:
27、
28、其中,h表示单个所述对话轮次特征中的首个标记的特征,i表示所述图像特征中的首个标记的特征,τ是温度参数,是一组与h不匹配的图像特征;
29、根据第二表达式确定所述图像特征到每个所述对话轮次特征的第二相似度;
30、所述第二表达式为:
31、
32、其中,是一组与i不匹配的对话轮次特征。
33、可选地,所述确定各个所述候选对话轮次中回答正确的目标对话轮次,包括:
34、将预设的损失函数与所述对比损失相似度相加,得到总损失函数;
35、根据所述总损失函数确定各个所述候选对话轮次中回答正确的目标对话轮次;
36、所述预设的损失函数的表达式为:
37、
38、其中,表示样本i中第t轮对话问答的标签,若回答正确则所述标签的值1,否则为0,所述样本i包括视觉对话的地面真实问答对以及随机采样的负类问答对;表示所述样本i中第t轮对话问答预测为正确答案的概率,n表示所述样本i总的数量。
39、本发明实施例的另一方面还提供了一种基于循环转换器和历史感知的视觉对话装置,包括:
40、第一单元,用于获取目标图像、所述目标图像对应的标题以及所述目标图像的对话历史;所述对话历史包括多个对话轮次,每个所述对话轮次包括问题和所述问题对应的回答;
41、第二单元,用于提取所述目标图像的图像特征;
42、第三单元,用于对所述标题和各个所述对话轮次进行逐轮编码,得到对话轮次特征;
43、第四单元,用于根据所述图像特征和所述对话轮次特征对所述目标图像和所述标题,与各个所述对话轮次进行匹配,得到与所述目标图像和所述标题匹配的各个候选对话轮次;
44、第五单元,用于确定各个所述候选对话轮次中回答正确的目标对话轮次。
45、本发明实施例的另一方面还提供了一种电子设备,包括处理器以及存储器;
46、所述存储器用于存储程序;
47、所述处理器执行所述程序实现所述的一种基于循环转换器和历史感知的视觉对话方法。
48、本发明实施例的另一方面还提供了一种计算机可读存储介质,所述存储介质存储有程序,所述程序被处理器执行实现所述的一种基于循环转换器和历史感知的视觉对话方法。
49、本发明实施例还公开了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。电子设备的处理器可以从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该电子设备执行前面的方法。
50、本发明提取目标图像的图像特征,进而对标题和各个对话轮次进行逐轮编码,得到对话轮次特征;然后根据图像特征和对话轮次特征匹配得出与目标图像和所述标题匹配的各个候选对话轮次,再从中确定回答正确的目标对话轮次;通过对对话历史,即标题和各个对话轮次进行逐次编码来更好地捕捉时间上的依赖性,然后在视觉对话的微调阶段对不同的模态进行对齐,即匹配出候选对话轮次,进而可以提高视觉对话的准确性。
- 还没有人留言评论。精彩留言会获得点赞!