一种模型训练方法、故障预测方法、系统、设备以及介质与流程
本发明涉及存储领域,具体涉及一种模型训练方法、故障预测方法、系统、设备以及介质。
背景技术:
1、数据的存储需求与日倍增,大规模海量数据存储中心是必不可少的基础性设施。大型数据中心采用传统的机械硬盘作为存储介质,在服务器硬件故障中,硬盘故障占比达到48%+,是影响服务器运行可靠性的重要因素。因此,业界期望使用机器学习技术来构建硬盘故障预测的模型,更准确地提前感知硬盘故障,降低运维成本,提升业务体验。
2、而通过机器学习对模型进行训练需要大量的数据,并且在构建训练集的每一个样本时,均需要对样本设置标签,现有的标签设置方法只是简单根据硬盘是否故障来区分正负样本,这样构建得到的训练集不够精准,训练得到的模型也不够准确。
技术实现思路
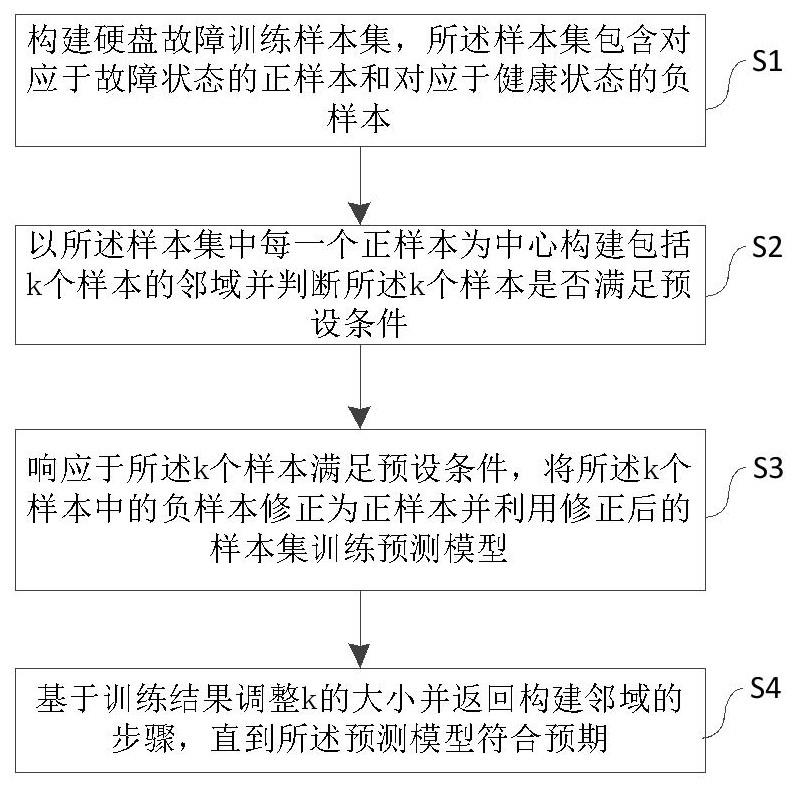
1、有鉴于此,为了克服上述问题的至少一个方面,本发明实施例提出一种硬盘故障预测模型训练方法,包括以下步骤:
2、构建硬盘故障训练样本集,所述样本集包含对应于故障状态的正样本和对应于健康状态的负样本;
3、以所述样本集中每一个正样本为中心构建包括k个样本的邻域并判断所述k个样本是否满足预设条件;
4、响应于所述k个样本满足预设条件,将所述k个样本中的负样本修正为正样本并利用修正后的样本集训练预测模型;
5、基于训练结果调整k的大小并返回构建邻域的步骤,直到所述预测模型符合预期。
6、在一些实施例中,所述构建硬盘故障训练样本集的步骤,进一步包括:
7、统计出现所述故障状态的硬盘在故障前预设时间段内每一个特征的值的第一概率分布以及统计对应于所述健康状态的硬盘在预设时间段内每一个特征的值的第二概率分布;
8、计算每一个特征对应的所述第一概率分布和第二概率分布之间的散度;
9、根据所述散度的大小确定构建样本的若干个特征。
10、在一些实施例中,所述根据所述散度的大小确定构建样本的若干个特征的步骤,进一步包括:
11、根据所述散度从大到小对每一个特征进行排序;
12、选择前m个特征作为构建样本的若干个特征。
13、在一些实施例中,还包括:
14、将硬盘在出现所述故障状态时采集到的若干个特征的值作为一个正样本,未出现所述故障状态时每次采集到的若干个特征的值作为一个负样本。
15、在一些实施例中,还包括:
16、将对应于所述健康状态的硬盘每次采集到的若干个特征的值作为一个负样本。
17、在一些实施例中,所述构建硬盘故障训练样本集的步骤,进一步包括:
18、统计若干个出现所述故障状态的硬盘在故障前预设时间段内每一个特征的值的第三概率分布以及统计若干个对应于所述健康状态的硬盘在预设时间段内每一个特征的值的第四概率分布;
19、计算每一个特征对应的第三概率分布与第四概率分布之间的散度以得到每一个特征对应的多个散度;
20、将每一个特征对应的多个散度进行加权计算得到最终的散度;
21、根据所述最终的散度的大小确定构建样本的若干个特征。
22、在一些实施例中,所述将每一个特征对应的多个散度进行加权计算得到最终的散度的步骤,进一步包括:
23、计算每一个特征对应的多个散度的平均值并将所述平均值作为最终的散度。
24、在一些实施例中,所述根据所述最终的散度的大小确定构建样本的若干个特征的步骤,进一步包括:
25、根据所述最终的散度从大到小对每一个特征进行排序;
26、选择前m个特征作为构建样本的若干个特征。
27、在一些实施例中,所述以所述样本集中每一个正样本为中心构建包括k个样本的邻域的步骤,进一步包括:
28、分别计算每一个所述正样本与剩余所有样本之间的欧式距离并基于所述欧式距离从小到大排序所述剩余所有样本以确定前k个样本。
29、在一些实施例中,所述响应于所述k个样本满足预设条件,将所述k个样本中的负样本修正为正样本的步骤,进一步包括:
30、确定每一个所述正样本对应的前k个样本中正样本的占比;
31、若正样本的占比大于阈值,则将所述前k个样本中的负样本修正为正样本。
32、在一些实施例中,所述利用修正后的样本训练预测模型的步骤,进一步包括:
33、基于同一个硬盘的对应的多个样本构建矩阵,其中,矩阵的列为同一个特征在不同时间采集得到的值,每一个行构成一个样本;
34、对每一列分别进行窗口权重平滑取值并将得到的值依次作为新的列加入矩阵的最后一列之后以得到第二矩阵;
35、将所述第二矩阵的每一行重新构成一个样本,重新构成的样本的标记与原始样本的标记相同;
36、利用重新构成的样本训练预测模型。
37、在一些实施例中,所述对每一列分别进行窗口权重平滑取值并将得到的值依次作为新的列加入矩阵的最后一列之后以得到第二矩阵的步骤,进一步包括:
38、根据公式对每一列分别进行窗口权重平滑取值;
39、其中, i取值为0到(n-2),n为窗口大小,m为行编号, w为权重。
40、在一些实施例中,所述对每一列分别进行窗口权重平滑取值并将得到的值依次作为新的列加入矩阵的最后一列之后以得到第二矩阵的步骤,进一步包括:
41、将所述第二矩阵的前(n-1)行删除。
42、在一些实施例中,所述基于训练结果调整k的大小并返回构建邻域的步骤,直到所述预测模型符合预期的步骤,进一步包括:
43、基于训练结果调整k、n和w取值并返回构建邻域的步骤,直到所述预测模型符合预期。
44、在一些实施例中,所述基于训练结果调整k、n和w取值并返回构建邻域的步骤,直到所述预测模型符合预期的步骤,进一步包括:
45、每次调整k、n和w取值时,分别固定任意两个参数,调整另一个参数。
46、在一些实施例中,所述利用修正后的样本训练预测模型的步骤,进一步包括:
47、构建测试集;
48、直接利用所述测试集中的每一个样本对训练后的所述预测模型进行测试以确定所述预测模型是否符合预期。
49、在一些实施例中,还包括:
50、判断所述预测模型的准确率和误报率是否满足阈值;
51、响应于满足阈值,则确定所述预测模型符合预期。
52、基于同一发明构思,根据本发明的另一个方面,本发明的实施例还提供了一种硬盘故障预测方法,包括:
53、基于如上所述的任一种所述硬盘故障预测模型训练方法训练预测模型;
54、利用训练后的所述预测模型对硬盘进行故障预测。
55、基于同一发明构思,根据本发明的另一个方面,本发明的实施例还提供了一种硬盘故障预测系统,包括:
56、训练模块,配置为基于如上所述的任一种所述硬盘故障预测模型训练方法训练预测模型;
57、预测模块,配置为利用训练后的所述预测模型对硬盘进行故障预测。
58、基于同一发明构思,根据本发明的另一个方面,本发明的实施例还提供了一种计算机设备,包括:
59、至少一个处理器;以及
60、存储器,所述存储器存储有可在所述处理器上运行的计算机程序,所述处理器执行所述程序时执行如上所述的任一种硬盘故障预测模型训练方法的步骤。
61、基于同一发明构思,根据本发明的另一个方面,本发明的实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时执行如上所述的任一种硬盘故障预测模型训练方法的步骤。
62、本发明具有以下有益技术效果之一:本发明提出的方案以每一个正样本构建邻域,从而对数据集中的样本的标签进行修正,并利用修正后的样本集训练模型,提升了模型的准确度。
- 还没有人留言评论。精彩留言会获得点赞!