基于图神经网络与元学习的用户多行为推荐方法
本发明涉及用户多行为分析的,具体涉及一种基于图神经网络与元学习的用户多行为推荐方法。
背景技术:
1、推荐系统(recommendation system,rs)自问世以来一直扮演着重要角色,一个优秀的推荐系统可以给服务提供者带来很多利益,例如提高经济效益,以及为产品提升竞争力。另一方面,越来越多的手机应用程序被发明和普及,其中网络购物软件和网络社交平台受到许多用户的喜爱。这些应用程序一直收集用户数据,并希望从这些数据中获利,种种行为使得大数据的增长率达到了前所未有的新高度。在大数据时代,谁能更好地利用大数据谁就可以带来更多意想不到的收货,这也是商品推荐系统之所以受到高度关注的重要原因之一。
2、推荐系统主要用于处理信息过载、挖掘长尾和改善用户体验。以电商平台为例,传统的推荐系统通常使用协同过滤(collaborative filtering,cf)来预测用户的购买行为,从而推荐最可能的商品给用户购买。协同过滤通常分析用户的历史数据,并通过将这些历史数据与具有相似历史数据的其他用户进行比较,为该用户提供推荐。然而,对于没有历史记录的新用户,协同过滤很难做出准确的预测,这种现象被称为冷启动。
3、最近,随着深度学习技术的进步,协同过滤中难以处理的许多问题得到了进一步优化。深度学习为推荐系统提供了许多新思路,它们不仅提高了推荐的精准度,而且减少了推荐过程中的资源耗费。例如,深度神经网络通过堆叠多个自编码器网络,将高维稀疏用户行为数据矩阵映射到低维密集表示。例如,神经网络协同过滤(neural collaborativefiltering,ncf)使用多层感知机来配对数据,极大地提高了协同过滤对没有或少量历史记录的新用户的预测准确性。此外,在图神经网络(graph neural networks,gnn)领域,用户-物品交互关系可以用图来表示,这使得数据处理和特征提取更加多样化。而卷积神经网络(convolutional neural network,gcn)通过参数共享和稀疏连接减少了网络模型的复杂性,使得推荐系统能够有效地从大量样本中提取特定的特征,从而避免了复杂的特征提取过程。
4、然而,所有上述推荐系统都有一个共同且不可避免的缺陷:它们迄今为止都关注于用户偏好表示,大多数研究人员仅专注于如何构建和优化网络的结构,以至于只有一种类型的用户到物品行为可以被输入到网络中以描述用户特征,这通常远离了现实生活中的推荐场景。实际上,用户和商品之间的交互是多重的,具有自然的关系多样性。以电子商务平台为例,在天猫app中,一些用户喜欢直接点击一次并购买商品,而另一些则喜欢在购买之前将商品加入购物车或加入收藏夹。此时,“点击”、“添加到收藏夹”和“添加到购物车”这三种行为都表明了用户的购买意向,实际上这些互动是相互依赖的,例如,“添加到购物车”比“添加到收藏夹”行为更加表明了用户的“购买”倾向,而“点击”和“添加到收藏夹”也可以为“购买”行为的决策提供有用的信号。因此,设计一个合理的结构来处理数据并从上述三种行为中捕捉潜在的信息可能成为优化推荐系统的突破口。因此,本发明专利更深入地探索了这种多重用户-物品交互的潜在关系。
5、虽然利用多重交互行为建立效率更高的推荐模型在理论上是可取的,但实际上对这一系列的协作关系编码是非常困难的,其中这两个关键问题急需被解决:首先,不同类型的用户-物品交互关系可能是变化莫测的,因为任何两种或三种行为类型都可能在许多方面相互关联,并且这种联系是随着不同的用户偏好而改变的,这给用户行为异构性建模带来了困难。其次,当建模不同类型用户行为之间的关系时,捕捉每种类型的用户行为的语义信息是错综复杂但非常重要的。例如,用户的点击行为比购买更频繁,同时“添加到收藏夹”的可能性比“添加到购物车”更高,但可能会推迟购买。因此,每种用户行为以一种难以捉摸的方式交织在一起。受上述问题的启发,本发明专利提出了一个基于用户多行为的图神经网络推荐(multi-behavior based graph neural network recommender,mbgr)。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题,特别创新地提出了一种基于图神经网络与元学习的用户多行为推荐方法。
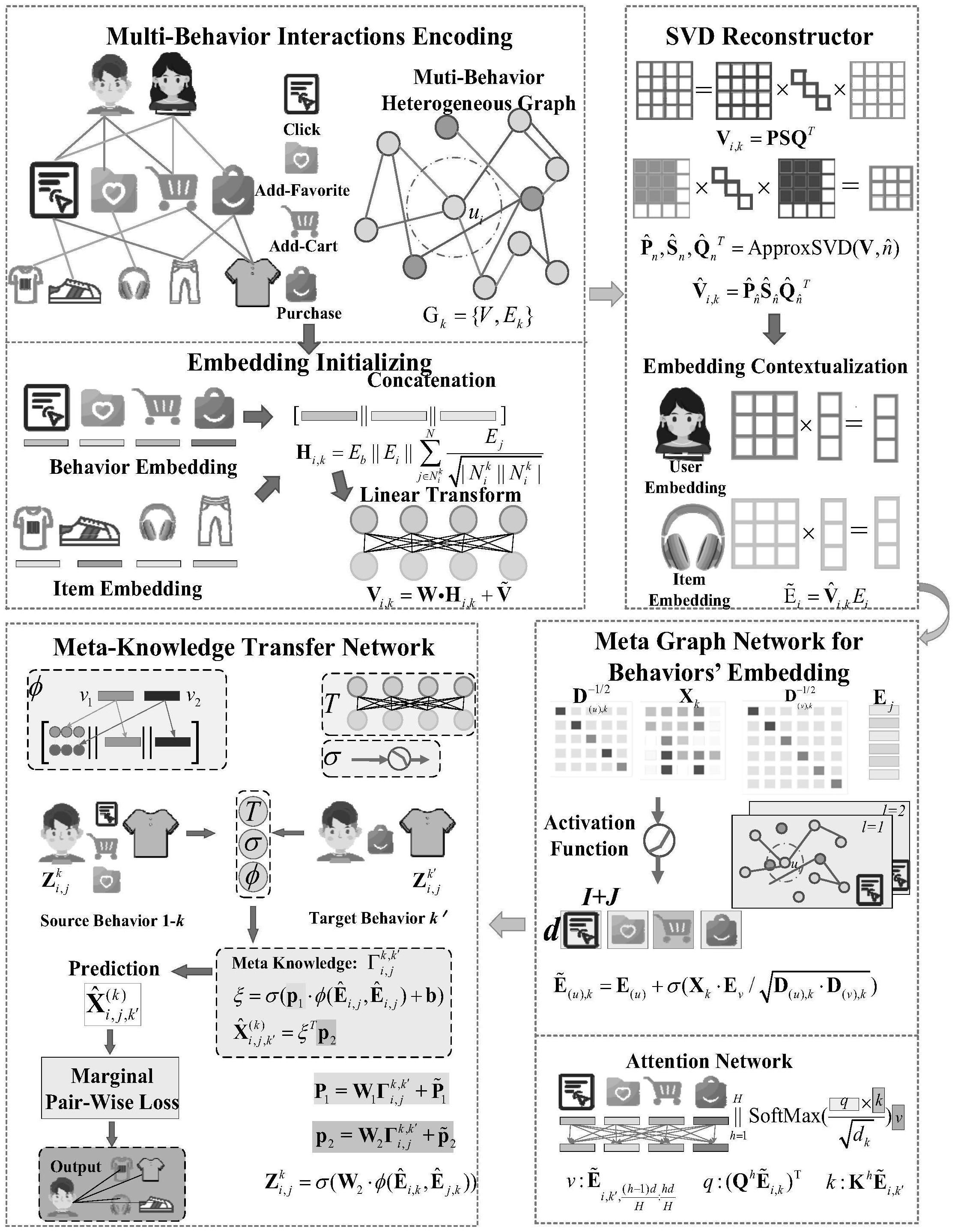
2、为了实现本发明的上述目的,本发明提供了一种基于图神经网络与元学习的用户多行为推荐系统,所述推荐系统包括元知识编码网络模块、用户行为交互关系学习网络模块、元知识迁移网络模块、训练推荐模块和评价模块;
3、元知识编码网络模块的数据输出端与用户行为交互关系学习网络模块的数据输入端相连,用户行为交互关系学习网络模块的数据输出端与元知识迁移网络模块的数据输入端相连,元知识迁移网络模块的数据输出端与模型训练推荐模块的数据输入端相连,模型训练推荐模块的数据输出端与评价模块的数据输入端相连;
4、元知识编码网络模块用于从初始的数据中提取元知识,并利用这些元知识初始化embedding;
5、用户行为交互关系学习网络模块用于基于元学习的处理信息传播和汇总用户和物品之间相关性的图神经网络,并且能够表征同一用户的多种行为之间的相关性对于不同物品的影响;
6、元知识迁移网络模块用于信息传播和元知识迁移的元学习,并依此生成辅助预测任务的权重数据;
7、模型训练推荐模块用于对大量的样本数据进行训练和优化并预测推荐;
8、评价模块用于对训练后的模型利用评价指标进行评价。
9、在本发明的一种优选实施方式中,在元知识编码网络模块中包括:
10、
11、其中,vi,k是元学习器训练得到的参数矩阵;
12、w表示元学习器的第一参数;
13、hi,k为包含上下文信息感知的embedding;
14、为元学习器的第二参数;
15、
16、其中,hi,k为包含上下文信息感知的embedding;
17、eb表示所有行为的初始化嵌入向量;
18、||表示将向量合并成矩阵的并置运算;
19、ei表示用户i的初始化的嵌入向量;
20、ej表示物品j的初始化的嵌入向量;
21、k表示第k种用户-物品交互行为;
22、表示用户i在第k种行为下产生交互的所有物品;
23、表示物品j在第k种行为下与之产生交互的所有用户;
24、表示用户或物品的embedding聚合的标准化项。
25、在本发明的一种优选实施方式中,在元知识编码网络模块中还包括数据重构,数据重构包括:
26、
27、
28、
29、其中,表示包含上下文的协同信息的用户embedding;
30、表示重构后的邻接矩阵;
31、ei表示用户i的初始化的嵌入向量;
32、表示重构后的第一正交矩阵;
33、表示重构后的奇异值矩阵;
34、表示重构后的第二正交矩阵;
35、approxsvd()表示奇异值分解;
36、v表示邻接矩阵;
37、表示最大奇异值的个数。
38、在本发明的一种优选实施方式中,在用户行为交互关系学习网络模块中包括:
39、
40、
41、其中,表示用户i的包含用户行为信息的嵌入向量;
42、表示物品j的包含用户行为信息的嵌入向量;
43、ei表示用户i的初始化的嵌入向量;
44、ej表示物品j的初始化的嵌入向量;
45、σ()表示第一激活函数;
46、表示数据标准化;
47、表示用户i在第k种行为下产生交互的所有物品;
48、表示物品j在第k种行为下与之产生交互的所有用户。
49、在本发明的一种优选实施方式中,在用户行为交互关系学习网络模块中还包括基于多头注意机制的用户行为关系学习,基于多头注意机制的用户行为关系学习的方法为:
50、
51、其中,表示第二中间变量;
52、qh表示注意力机制中的变量query;
53、表示用户i包含用户源行为信息的嵌入向量;
54、表示用户i包含目标行为信息的嵌入向量;
55、kh表示注意力机制中的变量key;
56、d/h表示注意力机制中的步长;
57、
58、其中,表示输入值分配权重;
59、softmax()是第二激活函数;
60、表示第三中间变量;
61、
62、其中,表示将1~h向量拼接;
63、hi,k表示每一个行为在所有行为中的特征表示;
64、h表示注意力头的数量;
65、表示源行为k对目标行为的第h个权重的表示;
66、vh表示注意力机制中的变量value;
67、表示注意力机制中每个步长下的用户行为向量的嵌入式表示;
68、表示向量的第h个切片,:表示从前项到后项过程中产生得到变量;
69、
70、其中,表示输出结果;
71、hi,k表示每一个行为在所有行为中类中的特征表示;
72、k表示用户-物品行为种数。
73、在本发明的一种优选实施方式中,在用户行为交互关系学习网络模块中还包括信息聚合,信息聚合的方法为:
74、
75、其中,表示聚合目标行为和源行为的中间向量;
76、grap-conv()表示行为语义编码建模;
77、mh-att()表示行为依赖关系建模;
78、表示行为语义编码层中的输入向量,它包含了k种源行为的嵌入式表示;
79、注意力层的输入向量,它包含了k种源行为的嵌入式表示和一个额外的代表各种源行为的权重向量;
80、l表示图编码器堆叠的层数;
81、k表示用户-物品行为种数;
82、
83、其中,表示聚合后的最终向量;
84、表示将k+1个中间向量累积求和。
85、在本发明的一种优选实施方式中,在元知识迁移网络模块中包括:
86、
87、其中,表示用户-物品对(ui,vj)包含目标行为k′和源行为k的元知识;
88、σ()表示第一激活函数;
89、φ()是计算两个embedding之间相互依赖关系的编码函数;
90、w1表示第一参数矩阵;
91、的目标行为k′和源行为k关系的映射表示;
92、
93、其中,表示(ui,vj)的源行为k关系的映射表示;
94、σ()表示第一激活函数;
95、φ()是计算两个embedding之间相互依赖关系的编码函数;
96、w2表示第二参数矩阵;
97、表示用户的全局嵌入向量;
98、表示物品的全局嵌入向量;
99、
100、φ()是计算两个embedding之间相互依赖关系的编码函数;
101、v1,v2表示第四中间变量和第五中间变量;
102、表示哈达玛积;
103、||表示向量合并成矩阵的并置运算。
104、在本发明的一种优选实施方式中,在训练推荐模块中包括:
105、
106、
107、p1,p2是为(ui,vj),源行为k和目标行为k′赋予权重的两个学习参数;
108、w1表示第一参数矩阵,w2表示第二参数矩阵,和分别表示这一层元网络的参数和偏差;
109、表示用户-物品对(ui,vj)包含目标行为k′和源行为k的元知识。
110、在本发明的一种优选实施方式中,在训练推荐模块中物品预测推荐的方法为:
111、
112、
113、则是mbgr的最终预测结果;
114、ξt表示中间变量的表示向量的转置;
115、p2表示第二参数;
116、ξ表示中间变量的表示向量;
117、σ()表示第一激活函数;
118、p1表示第一参数;
119、φ()是计算两个embedding之间相互依赖关系的编码函数;
120、表示用户的全局嵌入向量;
121、表示物品的全局嵌入向量;
122、b表示训练过程中的偏差。
123、在本发明的一种优选实施方式中,在训练推荐模块中优化训练的方法为:
124、
125、loss表示损失函数;
126、n表示用户数量;
127、k表示用户-物品行为的种数;
128、s表示样本数量;
129、max()表示取最大值函数;
130、表示正样本预测值,表示负样本预测值,ps和ns分别代表第s个正样本和负样本;
131、表示正则化项,其中θ表示可学习的参数。
132、或/和在评价模块中,评价指标包括命中率或/和归一化折损累积增益;
133、命中率的计算方法为:
134、
135、hr@k表示命中率;
136、numberofhits@k表示预测正确的次数;
137、gt表示预测次数总合;
138、归一化折损累积增益的计算方法为:
139、
140、ndcg@k表示归一化折损累积增益;
141、∑u∈undcgu@k表示累积增益;
142、idcgu表示理想情况下累积增益最大的值。
143、综上所述,由于采用了上述技术方案,本发明的有益效果是:
144、(1)将用户多行为依赖关系的编码作为一种embedding集成到神经网络推荐系统中,利用用户-商品交互信息设计了一种多行为分析模型来增强适用于电商推荐系统的数据特征提取。
145、(2)设计了一个元学习器。对用户多行为异构模式进行学习,以提取用户行为之间依赖关系的元知识。将这种元知识应用于配置图神经网络结构框架。
146、(3)提出了一种基于用户多行为的图神经网络推荐方法。结合了元学习模型和图神经网络框架,将用户多行为关系的元知识迁移到了图神经网络结构中,以实现用户目标行为的预测任务。
147、(4)在tmall、ml10m和yelp三个真实数据集上进行了对比实验,结果显示mbgr总体比来自不同研究领域的7个基线模型表现得更突出,这验证了mbgr模型的有效性。本发明专利还对提出的mbgr模型进行了消融实验、抗稀疏性和流行偏差指数实验与超参数分析,全方位地对mbgr的鲁棒性能进行了分析。
- 还没有人留言评论。精彩留言会获得点赞!