一种基于案例推理的机器人智能体技能学习与泛化方法
本发明涉及机器人智能体技能学习领域,具体涉及一种基于案例推理的机器人智能体技能学习与泛化方法。
背景技术:
1、机器人智能体技能的学习是当下一个很热门的话题,而强化学习及其衍生方法是机器人操作技能学习的一种主要手段。
2、但强化学习也有固有的缺陷,这在机器人智能体技能的学习过程中表现的尤为明显,其中难以在相似的任务场景之间迁移是其关键的缺陷之一。
3、基于此,一些提高算法对任务的适应性的技巧应运而生,如域随机化、域适应化、元学习等方法,这些方法都取得了一定的效果,但是这些方法都是基于场景的实际数据或者场景模型信息进行训练的,想要达到较好的效果需要大量的数据和计算资源,这导致它们训练效率较低;由于训练过程往往依赖深度神经网络的拟合,对于训练后的算法能否适应新的任务场景缺乏可信的解释,即由于新老场景的环境状态不同,无法判定在老场景下训练的动作策略能否以达到人们要求的情况下完成新场景的任务,导致训练结果缺乏可解释性。
4、因此,需要提供一种基于案例推理的机器人智能体技能学习与泛化方法以解决上述问题。
技术实现思路
1、本发明提供一种基于案例推理的机器人智能体技能学习与泛化方法,然后通过映射关系克服新老任务场景中状态、动作维数不对等的问题;然后,结合目标案例的动作与人类专家提供初始动作策略的方式实现新任务场景下的动作策略的适应,并使用基于参数探索的策略梯度(pgpe)方法实现动作策略的优化,以解决现有的由于新老场景的环境状态不同,无法判定在老场景下训练的动作策略能否以达到人们要求的情况下完成新场景的任务,导致训练结果缺乏可解释性问题。
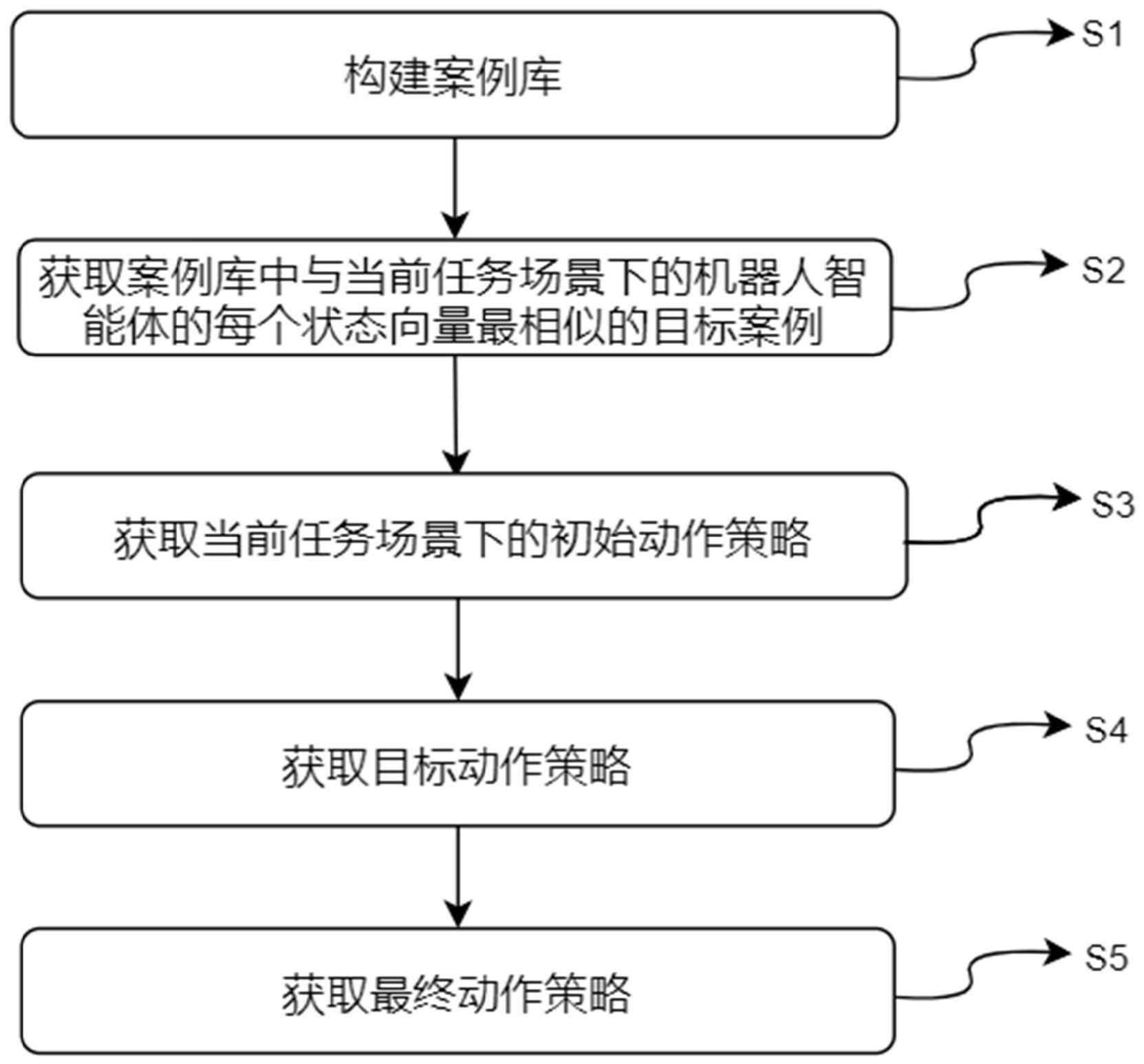
2、本发明的一种基于案例推理的机器人智能体技能学习与泛化方法采用如下技术方案:包括:
3、将机器人智能体在已知任务场景下的动作策略中,每个时间步的机器人智能体的状态-动作对作为一个案例,并构建案例库;
4、获取当前任务场景与已知任务场景的状态向量之间的对应关系,以及动作向量之间的对应关系;根据所述状态向量之间的对应关系,获取案例库中与当前任务场景下的机器人智能体的每个状态向量最相似的一个目标案例;
5、根据当前任务场景下每个动作向量和状态向量,以及每个状态向量与对应的目标案例中的状态向量之间的对应关系,获取当前任务场景下的初始动作策略;
6、利用参数探索的策略梯度算法对初始动作策略进行优化,得到优化后的动作策略;利用随机探索方式对优化后的动作策略中的特征参数进行扩展,得到目标特征参数;
7、根据目标特征参数和初始动作策略获取目标动作策略;
8、利用参数探索的策略梯度算法对目标动作策略进行优化得到最终动作策略。
9、优选的,其中,状态-动作对为每个时间步对应的动作向量和时间向量。
10、优选的,获取当前任务场景与已知任务场景的状态向量之间的对应关系,以及动作向量之间的对应关系的步骤包括:
11、将当前任务场景与已知任务场景中物理属性相同的状态向量对应;
12、将当前任务场景与已知任务场景中效果相同的动作向量对应;
13、则得到当前任务场景与已知任务场景之间状态向量的对应关系及动作向量的对应关系。
14、优选的,获取已知任务场景的案例库中与当前任务场景下的机器人智能体的状态最相似的一个目标案例的步骤包括:
15、根据已知任务场景和当前任务场景的两个状态向量之间的距离范数,构建已知任务场景和当前任务场景的相似性函数;
16、根据已知任务场景和当前任务场景的相似性函数,获取已知任务场景的案例库中与当前任务场景下的机器人智能体的状态最相似的一个目标案例。
17、优选的,获取优化后的动作策略的步骤包括:
18、利用高斯分布对初始动作策略的特征参数取多个向量值;
19、根据每个向量值下特征参数对初始动作策略更新得到更新后的动作策略,机器人智能体执行每个更新后的动作策略,得到每个更新后的动作策略对应的轨迹;
20、根据每个更新后的动作策略对应的轨迹预设对应的奖励值,并根据每个奖励值获取每个更新后的动作策略的特征参数均值;
21、直至特征参数均值收敛,将此时的特征参数均值作为优化后的动作策略的特征参数,并得到优化后的动作策略。
22、优选的,获取目标特征参数的步骤包括:
23、机器人智能体执行优化后的动作策略;
24、直至机器人智能体的状态向量第一次到达预设的状态向量变化范围时,随机选取所述状态向量变化范围内的状态向量,作为机器人智能体此时的状态向量;
25、根据此时的状态向量使用机器人智能体执行任务,并获取每次执行任务后的任务完成的奖励值;
26、将所有奖励值中的最大奖励值的轨迹对应的目标状态向量;
27、将目标状态向量的向量大小作为目标特征参数。
28、优选的,所述目标动作策略的表达式为:
29、
30、式中,θ表示优化后的动作策略的特征参数,特征参数即为动作策略的特征参数;
31、θnew表示目标特征参数;
32、scurrent表示机器人智能体在当前时刻的状态向量;
33、ta(aold)表示机器人智能体在当前任务场景的当前时刻的动作向量,与已知任务场景的当前时刻的动作向量之间的对应关系。
34、优选的,在利用参数探索的策略梯度算法对目标动作策略进行优化得到最终动作策略之前,还包括:
35、使用机器学习中的监督模式识别方法对所述案例库中的案例进行分类;
36、其中,分类结果通过:“如果状态(满足条件),那么执行(某种)动作”的规则式语言的描述形式表达;
37、根据规则式语言的形式更新目标动作策略得到更新后的目标动作策略。
38、优选的,根据规则式语言的形式更新目标动作策略得到更新后的目标动作策略的步骤包括:
39、设规则式语言的描述形式的表达式为aold=f(sold),即表示已知任务场景中状态向量向动作向量的映射,则得到更新后的目标动作策略的表达式为:
40、
41、式中,θ表示初始动作策略的特征参数;
42、θnew表示目标特征参数;
43、scurrent表示机器人智能体在当前任务场景下的每个前时刻的状态向量;
44、f(sref)表示使用完备的规则式语言描述的已知任务场景下的动作向量;
45、ta(f(sref))表示机器人智能体在当前任务场景的每个时刻的动作向量,与已知任务场景的每个对应的时刻的动作向量之间的对应关系;
46、其中,状态向量sref通过状态向量的对应关系为sref=ts(scurrent),从案例库中获取。
47、优选的,使用机器学习中的监督模式识别方法对所述案例库中的案例进行分类的步骤包括:
48、每个案例作为一个样本,案例的状态向量作为样本输入的特征向量,案例的动作策略作为训练样本输出类别,通过监督模式识别方法识别每个案例的类别。
49、本发明的有益效果是:
50、1、通过构建了基于任务场景状态的相似度函数,然后比较当前任务场景下机器人智能体的状态与案例库中案例的状态,选择最相似案例作为目标案例,通过映射关系克服新老任务场景中状态、动作维数不对等的问题,并结合目标案例的动作与人类专家提供初始动作策略的方式实现新任务场景下的动作策略的适应,并使用基于参数探索的策略梯度(pgpe)方法实现动作策略的优化,克服了使用深度神经网络拟合动作策略带来的动作策略可解释性低的问题。
51、2、本发明通过对案例库中离散的动作策略进行监督模式识别,从而使用完备的规则式语言对其进行表述,并代替案例库,克服了使用案例库进行动作选择需要对案例库进行遍历查找所带来的任务效率低的问题。
- 还没有人留言评论。精彩留言会获得点赞!