一种基于Spark的支持差分隐私的聚类方法
本发明涉及数据挖掘、差分隐私和分布式计算等领域,具体涉及一种基于spark的支持差分隐私的聚类方法。
背景技术:
1、近年来,由于大数据的快速发展,聚类算法作为一种典型的无监督算法受到越来越多的关注。然而,数据聚类分析的结果在提供有价值信息的同时也存在着一些隐私安全性的问题。为保护隐私而探索的许多现有解决方案要么承受计算开销,要么对涉及的各方有严格的假设,例如安全多方计算方案或同态加密方案,这与大多数现实的场景不符。因此支持差分隐私保护的聚类方法应运而生。
2、k-means算法作为最常用的聚类算法,其原理简单易懂,易于实现,广泛应用于数据挖掘和模式识别等领域。但是由于k-means算法通常需要将所有数据点都传输至服务器进行计算,因此很容易导致用户数据的泄露。特别是当用户数据包含敏感信息时,一旦泄露会给用户带来严重的隐私风险。为了解决k-means算法的隐私泄露问题,研究者们提出了许多改进算法。其中最常用的方法是差分隐私技术。dwork等人在论文《a firm foundationfor priv-ate data analysis》中详细分析了差分隐私k-means算法,并给出了设置隐私保护预算ε的方法。
3、另一方面,针对海量数据聚类的效率问题也是当前需要解决的重要难题。由于海量数据的规模庞大,传统的聚类方法往往无法胜任,导致计算速度缓慢、内存使用过高等问题。为了应对这一挑战,李洪成等人在论文《differe-ntial privacy-preserving k-meansclustering method in the mapreduce framework》中基于mapreduce框架实现了分布式环境下支持差分隐私保护的k-means聚类方法,利用mapreduce计算框架提高聚类分析的效率,并通过添加噪声使聚类的输出满足差分隐私,给出了具体的计算流程。
4、但是mapreduce是一个基于磁盘的批处理框架,在每次计算期间存在shuffle操作需要重复磁盘存储、读取和其他操作。因此mapreduce操作在处理海量数据的过程中会消耗大量时间,且不适合迭代计算。2022年毛伊敏等人在论文《基于spark框架和aspso的并行划分聚类算法》中实现了基于spark框架和aspso的并行划分聚类算法,利用spark框架并行实现聚类算法,极大提升了聚类算法的效率但是没有考虑数据聚类过程中存在的隐私泄露问题。
5、此外,k-means聚类算法的效果很大程度上依赖于初始质心的选择。如果初始质心的选取不当,可能会导致算法陷入局部极小值而得不到最优解。k-means++算法可以解决k-means算法其准确度受其初始中心点选取的影响较大的问题,但是在初始质心选择以及迭代更新质心时计算每个样本点到已选初始化随机中心点最短距离过程中会同样泄露隐私。2019年傅彦铭等人在文献《基于拉普拉斯机制的差分隐私保护k-means++聚类算法研究》中在k-mean++算法的基础上通过拉普拉斯机制实现了满足差分隐私的k-means++算法,在选取初始质心的过程中,采用拉普拉斯机制对数据实施扰动,解决了k-means++聚类算法选取初始化中心点时隐私泄露的问题。
6、然而,在面对海量高维数据聚类任务时,如果要在保证隐私的前提下实现良好的聚类效果,往往需要花费高额的隐私预算。这是由于数据规模增大和维数增多所带来的计算量也随之增加,导致隐私保护所需要的噪声扰动也随之增多,从而加大了隐私预算的开销,运行效率也随之大幅降低。
7、综上所述,为了提高海量数据聚类分析算法的隐私保护能力及运行效率,提出了一种spark框架下支持差分隐私保护的聚类算法,综合利用指数机制及拉普拉斯机制对差分隐私聚类算法进行优化,以减少计算过程中隐私预算的花费,并使聚类算法的输出结果满足差分隐私,同时利用spark计算框架将其拓展到分布式环境下执行以提高聚类分析的效率,实现算法的可拓展性,在解决分布式环境下海量数据的安全聚类问题上会有一定的帮助。
技术实现思路
1、本发明的目的是提出一种基于spark框架下支持差分隐私聚类的方法,以解决上述技术问题。
2、为实现上述目的,本发明提供了如下方案:
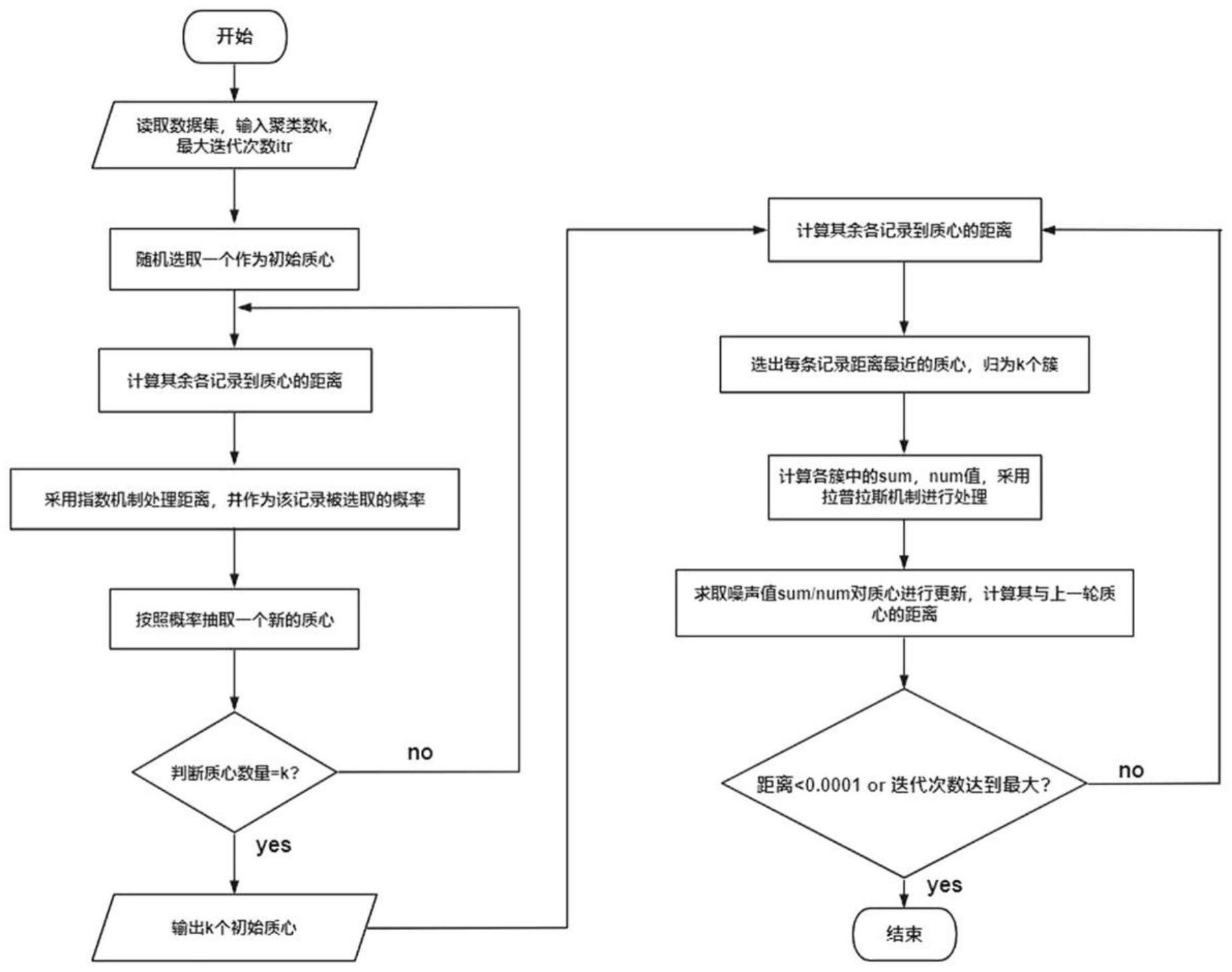
3、本发明的基于spark框架下支持差分隐私聚类的方法为一种分布式环境下支持差分隐私的k-means++聚类算法。该算法通过内存计算引擎spark,创建弹性分布式数据集(rdd),利用转换算子及行动算子操作数据进行运算,并在选取初始化中心点及迭代更新中心点的过程中,通过综合利用指数机制和拉普拉斯机制,以解决初始聚类中心敏感及隐私泄漏问题,同时减少计算过程中对数据实施的扰动。
4、算法的基本思路是先计算初始化中心点,其中使用指数机制对数据进行ε1-差分隐私保护,选取初始化中心点之后进行迭代求均值对中心点进行更新,并采用拉普拉斯机制对数据进行ε2-差分隐私保护,使得聚类算法的结果满足ε-差分隐私保护。
5、本发明的一个方面,针对其在计算样本点到已选初始化随机中心点最短距离过程中会泄露隐私的问题,采用指数机制进行优化,以减少对数据实施的扰动。为了使选取的中心点在数据中分布尽量离散,效用函数需满足如下要求:设已有的初始中心点集合为c,各记录与集合c中已选取的各中心点之间的最短距离越大,效用值就越大。为了使效用函数满足此要求。采用非中心点vi与中心点集合c之间的最短欧氏距离来构造效用函数,如下所示。
6、
7、算法步骤如下所示:
8、1)设数据集中的记录数为n,每条记录均为d维的向量vi(1≤i≤n),聚类目标数为k,各聚类的中心点记为cj(1≤j≤k)。
9、2)从hdfs读入数据集创建rdd,将数据切片后读入至不同分区。
10、3)随机选取第一个中心点c1,计算每条记录距已选中心点的最短距离disti(1≤i≤n),利用maptopair将rdd转变成pairrdd,并将记录处理成key-value键值对形式,其中key即为最短距离。
11、4)dist经由全局敏感度为δu的评分函数u(dist,r)处理输出r,计算exp(ε×r/2δu)作为效用值pri。
12、5)利用enumerateddistribution类对pri进行归一化操作,作为抽样的概率进而选取下一个中心点。
13、作为进一步的优选方案,重复执行上述步骤直至选出k个初始聚类中心。
14、另一方面,选出k个初始聚类中心后,在各分区内并行计算,迭代求取均值,并对结果进行拉普拉斯机制保护,最后对簇类中心进行更新。算法步骤如下所示:
15、1)计算每条记录距已选中心点{c1,c2,…ck}的最短距离disti(1≤i≤n),同样将rdd转变成pairrdd,将记录处理成key-value键值对形式,其中key的值为该记录距离最近的中心点cj(1≤j≤k)。
16、2)利用行动算子reducebykey对不同分区的记录按照其所属最近的中心点进行聚合,共k个分区。
17、3)各分区内分别统计记录总数numj,以及各记录属性向量之和sumj,分别加入拉普拉斯噪声得到num'j,sum'j。
18、4)重新计算该分区内的中心点
19、需要说明的是,算法的迭代条件设置为新一轮的中心点与上一轮中心点距离的变化,当两者距离小于设定的阈值时或者当隐私预算花费完时结束循环,否则继续进入下一轮迭代。
20、在一些实施例中,生成初始化中心点过程中,采用记录与中心点之间的最短欧式距离构造评分函数,尽可能地保证每个质心点之间的距离相对较远,从而能够更快、更准确地收敛到局部最优解。计算dist的过程等同于对空间[0,1]d进行划分的直方图查询,故评分函数的全局敏感度δu=1。设此过程消耗隐私预算为ε1,则每次选取初始中心点所消耗的隐私预算为ε1/k。
21、进一步的,迭代更新中心点的过程中,分区内的记录数num其全局敏感度为1,sum其全局敏感度为记录的维数大小d。由性质1可知,整个查询序列的全局敏感度δf=d+1,设此过程隐私预算为ε2,总迭代次数为t,第t次迭代的隐私预算即为ε2/2t,故算法在第t轮迭代时针对numj,sumj分别加入随机噪声lap(d+1)2t+1/ε2,可以保证spark框架下迭代更新过程中满足ε2-差分隐私保护。令ε=ε1+ε2,由性质1可知,整个聚类过程满足ε-差分隐私。
22、与现有技术相比,本发明首次将指数机制与拉普拉斯机制进行结合,分别运用在初始化质心选择的优化上以及各簇质心迭代更新的过程中,以减少隐私预算的开销。指数机制针对随机化算法f输入数据集d,输出一个实体对象r∈r,μ(d,r)为效用函数,δμ为函数μ(d,r)的敏感度,若以正比于exp(ε·μ(d,r)/2δμ)的概率从输入中选择并输出r,则f满足ε-差分隐私。利用指数机制以更高的概率选择效用得分更高的输出这一特性,将效用函数设置为计算记录与质心的距离,进行概率抽样,每次仅释放一个最大噪声分数的值作为新的质心。相比于使用拉普拉斯机制对数据扰动后选择距离最大的值作为质心,可以减少隐私预算的开销,从而提升差分隐私聚类算法的可用性。
23、另一方面,利用spark计算框架实现算法的并行化,创建弹性分布式数据集rdd,利用transformation转换算子及action行动算子操作数据进行运算,提高算法的效率及灵活性,相比于mapreduce需要将每次计算的结果写入磁盘,然后再从磁盘读取数据,导致频繁的磁盘io,spark得益于rdd和dag,除shuffle过程以外通常不需要将计算的结果写入磁盘,可以在内存中进行迭代计算。基于spark将算法由单机运行拓展至集群运行,以实现海量数据的高效安全聚类。
24、综上所述,本发明具有如下有益效果:本发明提出了一种采用spark分布式计算框架来实现聚类分析,从而能够处理大规模数据集并满足海量数据聚类的需求。相比于传统算法,该算法具有更好的可扩展性和分布式计算能力。在聚类过程中,该算法采取指数机制和laplace机制相结合的方法,从而有效降低隐私预算开销,进而缓解海量数据聚类过程中隐私性和可用性之间的矛盾问题。
- 还没有人留言评论。精彩留言会获得点赞!