一种基于自适应多项式基的商品分类方法
本发明涉及电商网络,尤其涉及一种基于自适应多项式基的商品分类方法。
背景技术:
1、随着大数据时代的到来,数据量急剧增长,数据类型更加多元,既存在图像,文本等序列化数据,也存在社交网络,生物蛋白质分子等图数据。图数据通常是一个含节点和边集合的二元组表示,节点表示被关注的对象,边表示对象之间的关联。例如,一张社交网络可以由用户(节点)及他们之间的互动关系(边)构成,一个蛋白质网络可以用分子(节点)及它们之间的化学键(边)构成。考虑到节点之间拓扑关联的神经网络可称为图神经网络。目前,图神经网络已在图结点分类、图分类等任务上取得优异表现。在实际应用中,图神经网络被广泛应用于生物分子性质预测、社交网络数据挖掘、欺诈识别、推荐系统设计当中,也可见于物理、化学系统的真实建模。
2、从图结构数据的角度看,商品构成节点,它们之间由“被共同购买”关系连接起来,形成一张商品网络。在商品网络上运行图神经网络可以得到商品节点的向量,这些向量可以进一步被用于多种目的的商品分类。例如,电商可以对商品进行针对受欢迎程度的分类,为后续选品提供思路;也可以进行商品是否适用于特定人群的分类,作为商品推荐中的一环。
3、值得注意的是,上述根据同时购买关系建边的商品网络未必符合一般图神经网络的基础:同配性假设。同配性假设指的是,在图网络上,由边连接的两个节点倾向于具有同样的标签。例如,仍然考虑分类目标为预测商品的受欢迎程度,假设某用户在一次交易中购买了某备受欢迎的热销品a,又凑单购买了因销量较差而被优惠处理的商品b,则这一次交易行为在商品a和商品b之间建立了一条边,但显然,商品a和商品b不应该属于同一个分类标签,不符合“同配性假设”。
4、考虑到商品网络中倾向于为非同配图,谱图神经网络更适用于被用在商品分类场景。谱图神经网络从图结构中分解得到多种不同基础频率的图信号,信号愈是高频,愈表示节点之间变化快速。通过强调高频信号,谱图神经网络往往能在非同配图上取得远高于一般图神经网络的性能。因此,如何针对上述场景设计谱图神经网络是一个值得考虑的问题。
5、现有技术一基于广义佩奇图神经网络(generalized pagerank graph neuralnetwork),该模型属于谱图神经网络中易于计算的多项式滤波器。下面介绍用广义佩奇图神经网络进行商品分类的具体方案。
6、对于一个构建好的商品交易图结构g,每个商品节点都有一个向量用来描述商品的自身特征,所有节点特征被共同记为矩阵x。首先,广义佩奇图神经网络会对商品的自身特征x进行特征变换,该过程使用一个全连接神经网络完成;接着利用广义佩奇技术对变换后的特征进行k次图传播,并将多次图传播的结果加权起来,该过程可以表述为其中p表示归一化的邻接矩阵,w表示可以学习的系数。该步骤的关键就是学习到有效的系数w。在对特征进行了图传播之后,可以得到每个商品节点的向量表示y,最后使用表示y计算各类别的概率分数,就可以获得商品在各个类别上的预测分数。
7、该技术核心步骤实际上利用了单项基函数(monomial basis)来拟合理想滤波器。该多项式基在函数拟合中是不稳定的。
8、现有技术二是一种基于雅可比图卷积神经网络(jacobiconv)的多项式滤波器。被用于进行商品分类时,其流程与技术一类似,但核心卷积步骤变为其中gk表示第k阶雅可比基。相较于技术一,技术二将单项式基改为了雅可比基。雅可比基是一族正交多项式基,其具体的形式由两个[0,1]之间的参数决定。
9、该工作首先证明了令多项式滤波器收敛速度最优的多项式基是某个特定测度上的标准正交多项式基,但他们认为该测度在有限时间和较大的图上不可求得,因此折衷从雅可比族多项式序列中通过超参数选择挑选合适的正交多项式基。但作为一种折衷,首先,雅可比基可以涵盖的测度函数范围狭窄、极大可能不能覆盖到目标最优多项式基的测度;其次,雅可比基不为标准正交基。因此,这种折衷距离利用最优多项式基优化多项式滤波器模型的初衷尚远。
技术实现思路
1、为此,本发明首先提出一种基于自适应多项式基的商品分类方法,
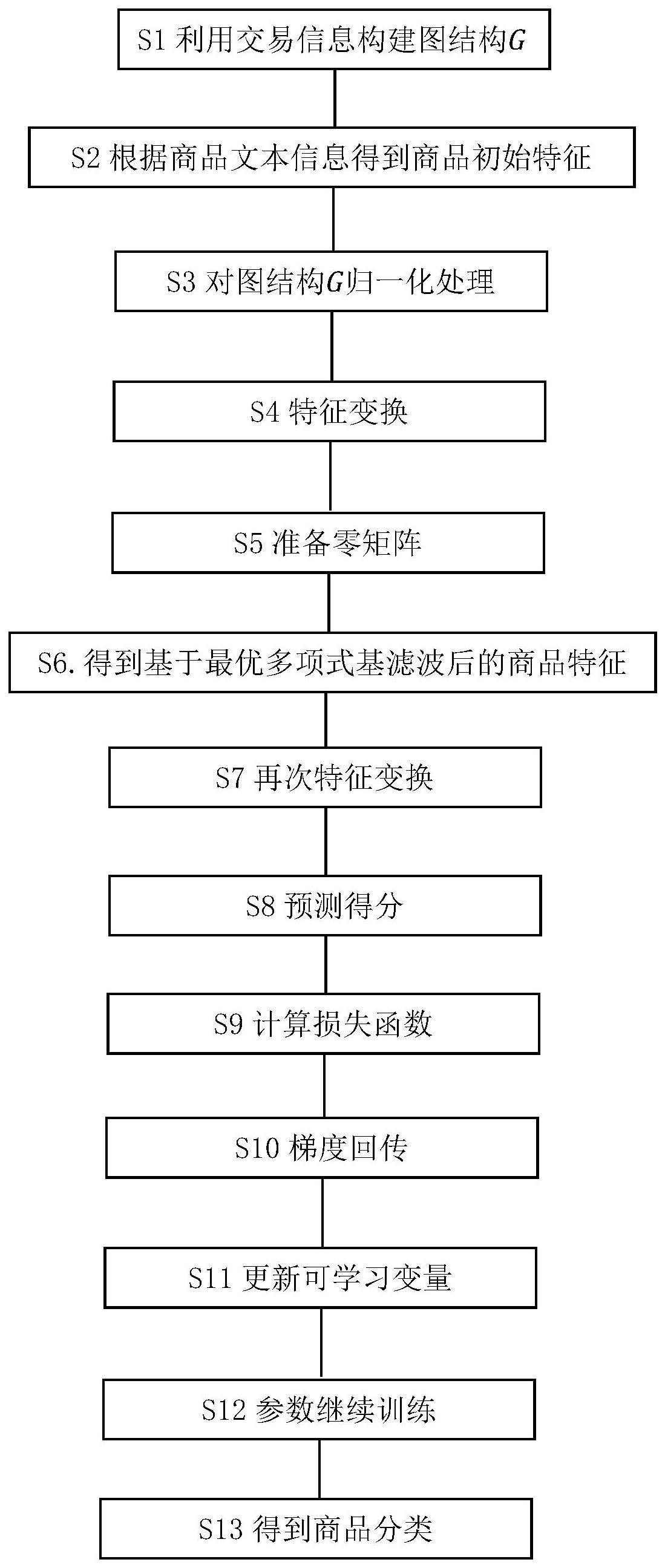
2、s1,对于任意的商品和交易记录数据,利用交易信息构建图结构g,该图结构的节点为不同的商品,节点之间的连边表示两个不同的商品被同时购买或销售;
3、s2,对于每个商品节点,将商品名称、商品描述、配方、制作商、备注五项文本信息拼接起来,经过中文预训练后的bert模型编码器,得到d=768维的向量,作为描述该商品的初始特征。记商品数目为n,全体商品特征向量为finitial,其形状为n行d列;
4、s3,对图结构g的边权进行对称归一化处理,归一化后的邻接矩阵记作
5、s4,对finitial做特征变换,得新的商品特征矩阵f,其形状为n行d列;d为经过变换后的商品特征维数。具体来说,这里的特征变换是一个单层感知机,记作f=σ(finitialw0+b0),其中,σ表示整流线性单元激活函数(linear rectification function,relu),w0是一个d行d列的矩阵,b0是一个1行d列的行向量,w0、b0均为可学习变量,将在s10中被更新;
6、s5,准备一个与f相同形状的零矩阵q,用于承载经滤波变换的商品特征;
7、s6,依次取出f中每一列,即一个通道上的商品特征,记作f;同时,取出q中对应的列,记作q,用来承载滤波之后这个通道上商品特征;对取出的f中的每一列,执行步骤ms1-ms10。ms1-ms10的行为可简述为:基于滤波前商品特征f,逐步更新滤波后商品特征q,并将被更新的商品特征q写回到q的对应列。注意步骤ms1-ms10中含可学习变量,即加权系数;
8、s7,对所有维度上经滤波操作的商品特征q再次进行特征变换,得其形状为n行c列,其中c为商品类别数;具体来说,这里的特征变换是一个单层感知机,记作其中,σ为relu(同s4),w1是一个d行c列的矩阵,b1是一个形状为1行c列的行向量,w1、b1均为可学习变量,将在s10中被更新;
9、s8,对做softmax操作,得到各商品在共c个商品类别上的预测得分;
10、s9,用软化后的交叉熵损失函数根据已知的商品正确类别衡量其预测得分与真实所属类别的损失值。具体而言,交叉熵损失函数记作其中表示模型对第i个商品属于第c个预测类别的概率评分,商品数目为n,pic采用一种软化的标准,其取值准则为:若第i个商品的真实类别为c,则为0.8,否则为
11、s10,将该损失值进行梯度回传,得到s4、s6、s7中各个可学习变量在这一轮训练后的梯度;
12、s11,用梯度下降法更新s4、s6、s7中的可学习变量;
13、s12,返回s4,基于更新后的可学习参数继续训练。在此过程中,对于带标签的商品,其预测得分情况与真实所属类别之间的损失不断降低。当损失不再降低时,训练结束。
14、s13,将训练好的模型用于未知类别的商品,记录预测结果为商品分类表。
15、其中ms1-10具体为:
16、ms1,设多项式阶数为k(实际运用中常选择k为10或者20),初始化可学习系数向量α=[α0,α1,...,αk];下面计算和当前维商品特征/信号有关的k+1个基商品特征,它们都是滤波后的商品特征的组成部分;
17、ms2,初始化第-1个基商品特征为全零向量,记作
18、ms3,通过对滤波前商品特征f做归一化,得到第0号基商品特征,记作p0←f/|f|;
19、ms4,更新滤波后商品特征q。向z中以α0为权重加入第0号基商品特征,记作q←q+α0p0;
20、ms5,设计数变量i=0,记录已经计算出并加权到第i号基商品特征;
21、ms6,开始计算第f+1号基商品特征pi+1。将已计算出的pi在上进行一次图传播,用数学公式表述为
22、ms7,在上一步中的pi+1中去掉第i号和第i-1号基商品特征的成分;
23、ms8,对上一步中的pi+1中做归一化得到,记作pi+1←pi+1/|pi+1|;正式得到第i+1号基商品特征pi+1;
24、ms9,利用新得到的基商品特征pi+1,更新滤波后商品特征q。向q中加入αi+1pi+1,记作q←q+αi+1pi+1;
25、ms10,令计数变量增1,记作i←i+1;若i>k,程序停止;否则,返回步骤ms6,继续计算基商品特征并更新滤波后商品特征q。
26、本发明所要实现的技术效果在于:
27、本发明方案能够高效计算在理论上具备最优收敛性质的多项式基。该最优多项式基的概念曾在现有技术二中被提出,但被认为不可在可承担的时间成本内解得,故在此前未能被有效利用。本方案中,其复杂度仅为每次训练k次图传播,和一般固定多项式基的滤波器模型无异。该性质能够提升滤波器模型在非同配的商品分类网络上的性能。
- 还没有人留言评论。精彩留言会获得点赞!