一种基于机器学习的数据自服务资产目录构建方法及装置与流程
本发明涉及数据资产管理,尤其涉及一种基于机器学习的数据自服务资产目录构建方法及装置。
背景技术:
1、随着我国社会经济的快速发展,科学技术水平在不断提高,计算机技术的出现给人们的日常生活和工作带来了极大便利。在网络时代下,数据信息发挥着十分重要的作用,如今人们对于数据信息的获取需求变得越来越高,数据的种类也朝着多样化的方向进行转变,原有的数据处理技术显然已经无法满足当前的实际发展需求,因此需要对现有的计算机处理技术进行创新和优化。
2、数据管理是企业运营的重要组成部分,企业需要有效地管理自身拥有的数据,以实现更好的运营效率和更精确的业务决策。数据资产是指由企业或机构拥有或者控制的、能够产生价值的数据资源,例如客户名单、交易记录、医疗信息等,它来源于大数据,具有数据量大、类型繁多、价值密度低、时效高、时刻在线的特征,人们往往需要花费较大的成本才能从数据资产中找到所需的数据。数据资产目录是数据管理的重要组成部分,能够帮助企业了解和掌握自身拥有的数据资产,包括数据的属性、来源、价值等,进而为企业的业务决策提供支持。
3、在大数据技术不断发展的前提下,各行各业都开始广泛研究和应用大数据解决工作问题。数据资产管理的主要目标是提升数据资产标准化、精益化、信息化管理水平,主要理念和方法是统筹协调资产在规划、设计、建设、运维、改造、退役处置等全生命周期的管理行为和技术要求,实现数据资产全寿命周期内的安全、效能、成本综合最优。为了便于对数据资产进行管理、查找和使用,可以建立数据资产目录,对数据资产进行梳理、编目。
4、传统的数据资产目录构建技术,通常是依赖专门的业务人员,依靠业务知识对存入系统的数据表进行判断、分门别类。然而,由于数据资产来源复杂、数据形态多样、数据数量巨大、更新快,传统的手工建立数据资产目录的方法需要耗费大量的人力、物力和时间,并且容易出现错误和漏洞,影响数据管理的准确性和效率,构建的数据资产目录可用性低下。
技术实现思路
1、本发明针对如何通过人工智能和自动化的手段实现数据分类,完成数据资产盘点与信息补充,从而规划数据资产架构,构建统一数据资产目录,掌握数据资产家底,成为各大企业亟待解决的问题,提出了本发明。
2、为解决上述技术问题,本发明提供如下技术方案:
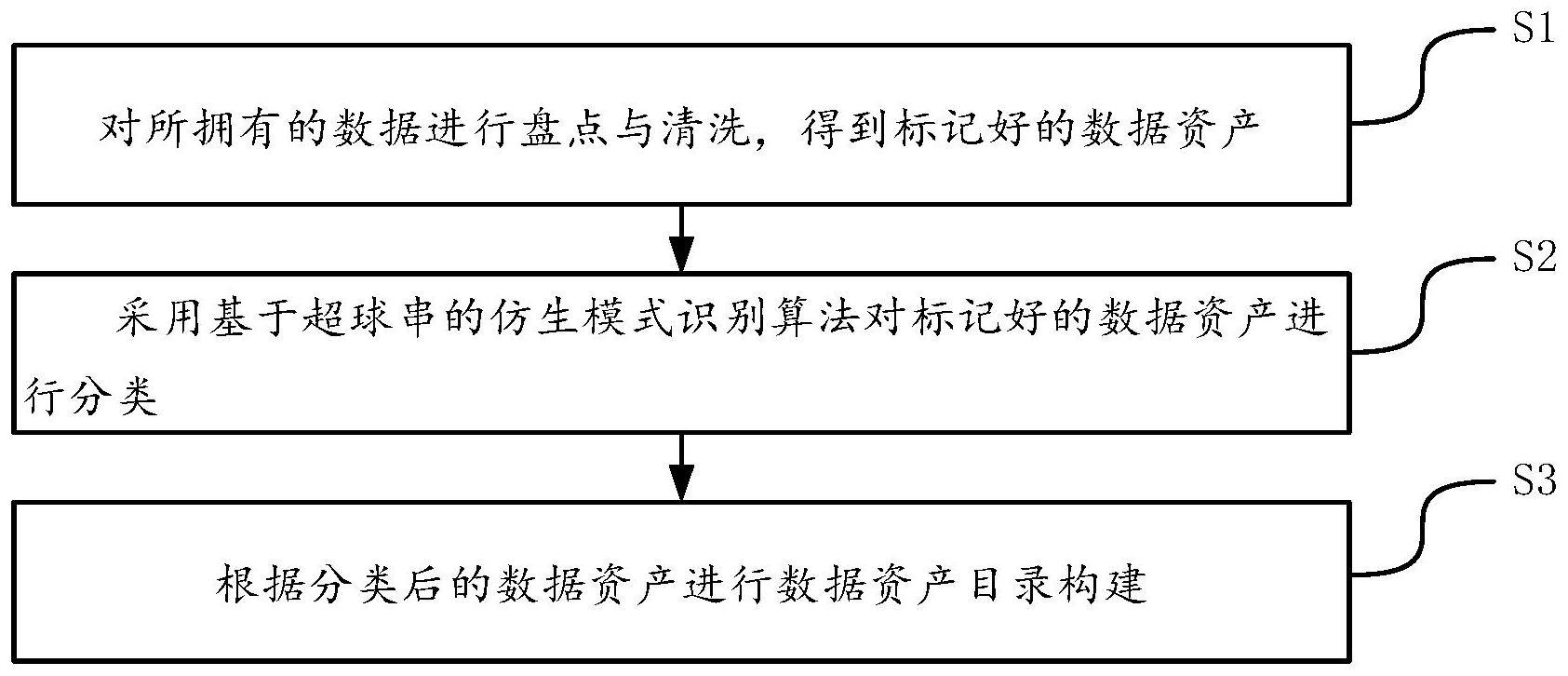
3、一方面,本发明提供了一种基于机器学习的数据自服务资产目录构建方法,该方法由电子设备实现,该方法包括:
4、s1、对所拥有的数据进行盘点与清洗,得到标记好的数据资产。
5、s2、采用基于超球串的仿生模式识别算法对标记好的数据资产进行分类。
6、s3、根据分类后的数据资产进行数据资产目录构建。
7、可选地,s1中的对所拥有的数据进行盘点与清洗,得到标记好的数据资产,包括:
8、s11、对所拥有的数据进行分类。
9、s12、对分类后的数据根据业务权重、决策权重、使用频度以及分布范围进行数据的重要程度计算,获取重要程度计算结果大于或等于预设阈值的数据作为数据资产,对数据资产进行标记。
10、可选地,s11中的对所拥有的数据进行分类,包括:
11、将所拥有的数据中的记录数据归类于基础业务数据。
12、将基于基础业务数据计算得到的结果归类于洞察分析数据。
13、可选地,s12中的对数据资产进行标记,包括:
14、对数据资产的来源、存储位置、权限信息以及数据类型进行标记。
15、可选地,s12中的业务权重,表示数据是否属于企业核心业务运营范畴;
16、决策权重,表示数据对高层决策的重要程度。
17、使用频度,表示数据被使用的频次。
18、分布范围,表示数据分布在业务域或者系统中的范围。
19、可选地,s2中的采用基于超球串的仿生模式识别算法对标记好的数据资产进行分类,包括:
20、s21、将标记好的数据资产进行向量表示。
21、s22、采用信息增益ig法对向量进行特征选择。
22、s23、对特征选择后的向量,根据超球链模板判断所属类别。
23、可选地,s23中的超球链模板的构建过程包括:
24、s231、获取特征选择后的向量样本,针对每一类别选择预设数量的数据,构成训练样本。
25、s232、对训练样本的坐标,使用基于超球串的仿生模式识别算法构造超球链模板。
26、可选地,s3中的根据分类后的数据资产进行数据资产目录构建,包括:
27、s31、构建数据资产目录的第一层l1为主题域分组,用于描述数据资产管理的最高层级分类。
28、s32、在每个l1目录下划分第二层l2主题域子目录,用于对业务组成部分进行划分,并且同一个主题域有相同的数据所有者。
29、s33、构建数据资产目录的第三层l3为业务对象,用于定义业务领域重要的人、事以及物。
30、s34、构建数据资产目录的第四层l4为逻辑数据实体,其中,逻辑数据实体指描述一个业务对象在任一方面特征的一组属性集合。
31、s35、构建数据资产目录的第五层l5为属性目录,用于描述所属业务对象的性质和特征。
32、s36、将分类后的数据资产中的每个数据填入l1-l5。
33、可选地,方法还包括:
34、获取待添加的新数据,对新数据进行盘点与清洗以及分类,根据分类结果将新数据添加至数据资产目录。
35、另一方面,本发明提供了一种基于机器学习的数据自服务资产目录构建装置,该装置应用于实现基于机器学习的数据自服务资产目录构建方法,该装置包括:
36、标记模块,用于对所拥有的数据进行盘点与清洗,得到标记好的数据资产。
37、分类模块,用于采用基于超球串的仿生模式识别算法对标记好的数据资产进行分类。
38、构建模块,用于根据分类后的数据资产进行数据资产目录构建。
39、可选地,标记模块,进一步用于:
40、s11、对所拥有的数据进行分类。
41、s12、对分类后的数据根据业务权重、决策权重、使用频度以及分布范围进行数据的重要程度计算,获取重要程度计算结果大于或等于预设阈值的数据作为数据资产,对数据资产进行标记。
42、可选地,标记模块,进一步用于:
43、将所拥有的数据中的记录数据归类于基础业务数据。
44、将基于基础业务数据计算得到的结果归类于洞察分析数据。
45、可选地,标记模块,进一步用于:
46、对数据资产的来源、存储位置、权限信息以及数据类型进行标记。
47、可选地,业务权重,表示数据是否属于企业核心业务运营范畴;
48、决策权重,表示数据对高层决策的重要程度。
49、使用频度,表示数据被使用的频次。
50、分布范围,表示数据分布在业务域或者系统中的范围。
51、可选地,分类模块,进一步用于:
52、s21、将标记好的数据资产进行向量表示。
53、s22、采用信息增益ig法对向量进行特征选择。
54、s23、对特征选择后的向量,根据超球链模板判断所属类别。
55、可选地,分类模块,进一步用于:
56、s231、获取特征选择后的向量样本,针对每一类别选择预设数量的数据,构成训练样本。
57、s232、对训练样本的坐标,使用基于超球串的仿生模式识别算法构造超球链模板。
58、可选地,构建模块,进一步用于:
59、s31、构建数据资产目录的第一层l1为主题域分组,用于描述数据资产管理的最高层级分类。
60、s32、在每个l1目录下划分第二层l2主题域子目录,用于对业务组成部分进行划分,并且同一个主题域有相同的数据所有者。
61、s33、构建数据资产目录的第三层l3为业务对象,用于定义业务领域重要的人、事以及物。
62、s34、构建数据资产目录的第四层l4为逻辑数据实体,其中,逻辑数据实体指描述一个业务对象在任一方面特征的一组属性集合。
63、s35、构建数据资产目录的第五层l5为属性目录,用于描述所属业务对象的性质和特征。
64、s36、将分类后的数据资产中的每个数据填入l1-l5。
65、可选地,还包括:
66、获取待添加的新数据,对新数据进行盘点与清洗以及分类,根据分类结果将新数据添加至数据资产目录。
67、一方面,提供了一种电子设备,所述电子设备包括处理器和存储器,所述存储器中存储有至少一条指令,所述至少一条指令由所述处理器加载并执行以实现上述基于机器学习的数据自服务资产目录构建方法。
68、一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现上述基于机器学习的数据自服务资产目录构建方法。
69、上述技术方案,与现有技术相比至少具有如下有益效果:
70、上述方案,对于传统数据资产目录构建方法中的问题,本发明结合机器学习方法采用了基于超球串的仿生模式识别算法对数据空间进行识别学习,解决了大量数据标签划分周期长、人工工作量大的问题。
71、针对传统数据资产目录划分混乱问题,本发明从业务出发逐级细分,提出了五级结构的数据资产目录框架,有效解决了数据资产管理混乱的问题。
- 还没有人留言评论。精彩留言会获得点赞!