基于影响因素分析的光伏发电功率预测方法与流程
本发明涉及一种基于影响因素分析的光伏发电功率预测方法,属于光伏发电功率预测。
背景技术:
1、太阳能具有广泛性、清洁性等优点,同时具备可扩展性强,可持续性强等特点,是最理想的可再生能源之一。在太阳能应用方法中,光伏发电是最重要的形式之一。因为光伏发电不需要消耗任何资源,也不会对环境造成破坏,它将是未来发展电力事业的最佳途径,也是节能减排的有效手段。无论是从保护地球环境的角度,还是在解决人类日益增长的电力需求问题上,光伏发电都具有重要的意义。随着近年来光伏领域技术的不断进步,光伏发电得到了迅速的发展,在发电产业中所占的比例越来越大。光伏系统可应用于农家电系统、偏远地区大型光伏电站、微电网等,发挥着重要作用。
2、然而,最严重的问题是光伏发电的功率输出不稳定,受太阳光强度的影响很大。当夜间没有阳光时,光伏板就不会发电。而且在白天的天气以及日照强度发生变化,对电力输出的影响也很大。晴天云层出现变化时,光伏发电输出功率也会产生波动。因此,为了更好地利用太阳能,大力发展光伏发电产业,就需要掌握光伏发电的规律,准确预测光伏发电的输出功率。准确的光伏功率预测不仅可以为系统规划和调度提供可靠的依据,而且对系统优化、能源有效利用、电网安全稳定运行都具有重要作用。
3、现行的光伏发电功率预测方法往往对稳定运行状态下的光伏发电功率预测精确度较高,但在多种气象因素的影响下准确度往往得不到保障,从预测精度来看,现行的多种机器学习预测算法在光伏发电预测领域中效果不佳。
4、但光伏发电功率预测的均方根误差(rmse)的整体水平仍在6%-10%左右,商业应用的预测软件rmse较低,且稳定性不足,与电力系统和微电网运行的实际应用要求差距很大,很难以满足日益增长的光伏发电功率预测的精度需求。
技术实现思路
1、本发明目的是提供一种基于影响因素分析的光伏发电功率预测方法,光伏功率预测精准度高,可以提高电网稳定性、增加电网消纳光电能力,能够有效地帮助电网调度部门做好各类电源的调度计划,解决了背景技术中存在的问题。
2、本发明的技术方案是:
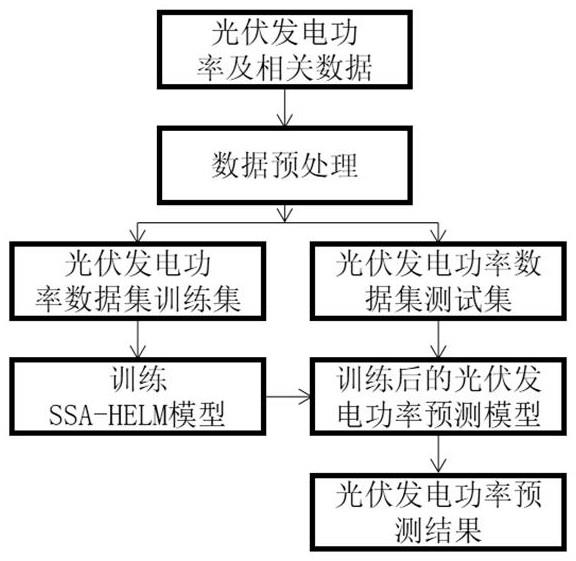
3、一种基于影响因素分析的光伏发电功率预测方法,包含如下步骤:通过对影响因素进行分析,通过多层极限学习机对光伏发电功率实现精准预测,采用麻雀搜索算法对多层极限学习机的参数进行优化,提高了光伏发电功率预测模型的稳定性和预测精度。
4、具体步骤如下:首先,采集光伏系统的历史发电功率数据,以及历史运行数据中对应的云层不透明度、温湿度和太阳光照辐射强度等因素,对收集到的历史发电功率数据进行预处理,历史数据的处理主要是对于历史发电功率数据中涉及到的影响因素进行整理,并对数据本身的归一化处理和异常数据进行清除处理等;其次,将预处理完成后的数据输入预测模型,从而得到发电功率的预测结果。
5、所述麻雀搜索算法的步骤如下:
6、①初始化种群,设定麻雀种群总数量n、发现者数量、意识到危险的麻雀数量以及最大迭代次数itermax、警报阈值r2;
7、②将均方根误差(root mean square error,rmse,rmse)作为适应度函数,然后计算出每只麻雀的适应度值,并找到最佳适应度和最差适应度值,分别定义为fg和fw;
8、③通过计算得到发现者、觅食者和意识到危险麻雀的新位置,若新位置的适应度值优于之前的,则更新它;
9、④进行迭代,重复步骤③,不断地更新最佳麻雀的位置,当迭代次数增加到itermax时,迭代停止;最优解为所有次迭代中适应度值最低的那只麻雀。
10、根据麻雀搜索算法的规则,在每次迭代过程中,发现者的位置更新如下:
11、
12、式中:t为当前迭代次数;j为当前的维度;为迭代t次时第i只麻雀的第j维的位置;itermax为最大迭代次数;α∈[0,1]是一个随机数;r2和st分别为警报值和安全阈值,根据经验通常r2∈[0,1],st∈[0.5,1];q为服从正态分布的随机数;l为d维单位向量,其中d为要优化的变量的维数,每个元素都是1;
13、如果r2<st,说明周围没有捕食者,发现者进入广域搜索模式;如果r2≥st,说明部分麻雀发现了捕食者,且所有麻雀需要迅速飞到其他安全区域;
14、觅食者频繁地监视发现者,觅食者的位置更新公式如下:
15、
16、式中:为第t次迭代全体最差位置;为第t+1次迭代发现者的最佳位置;a为与输入维度相同的1×d维矩阵,其中每个元素随机分配1或-1,且a+=at(aat)-1;n为麻雀的数量;
17、当i>n/2时,说明适应度值较差的第i个饥饿的觅食者最有可能饿死;i≤n/2,是跟随发现者的觅食者的更新位置;
18、意识到危险麻雀的位置更新公式如下:
19、
20、式中:是第t次迭代的全局最佳位置;λ作为步长控制参数,是个随机数,服从均值为0,方差为1的正态分布;j∈[-1,1]的一个随机数;fi为当前麻雀的适应度值;fg和fw为全局最佳适应度值和最差适应度值;ε定义为特别小的常数,主要是为了防止fi-fw=0的情况;
21、当fi>fg时,表示在群体边缘的麻雀的位置变化;最安全的位置是群体最中心的位置;fi=fg表明处于种群中间的麻雀意识到了危险,需要靠近其他麻雀;j表示麻雀移动的方向,也是步长控制系数。
22、所述多层极限学习机的步骤如下:
23、①输入训练样本集(xi,ti)(1≤i≤q),设置隐含层节点数l;
24、②初始化网络,随机生成权值w和阈值b并求它们的正交基;
25、③选择激活函数sigmoid,该函数表达式为g(u)=1/(1+exp(-au)),利用公式计算隐含层输出h;
26、④计算输出层权值β=h+e;
27、⑤计算第一层输出矩阵temp=β·h;
28、⑥然后将第一层的输出矩阵带入激活函数中后得到第二层的输入矩阵:k=1/(1+exp(-a·temp));
29、⑦返回步骤②,直到计算出i个输出权值β。
30、所述多层极限学习机训练框架分为两个部分:无监督特征表示和有监督特征分类,无监督特征表示是用于提取输入数据多层稀疏特征的基于自编码的elm,有监督特征分类是用于最终决策的原始elm;
31、输入的原始数据被转换至elm随机特征空间,每一个隐含层输出可以表示为:
32、hi=g(hi-1β) (4)
33、其中,hi是第i层的输出,hi-1是第i-1层的输出,g是隐含层激活函数,β是输出权值;多层极限学习机的每一层都是一个独立的模块,每一层相当于一个特征提取器;随着层数的增加,特征分布会更加紧凑,一旦前一个隐含层的特征被提取,本层的权值和其他参数就被固定;
34、elm稀疏自编码过程是将稀疏约束条件添加到自编码优化过程中,elm稀疏自编码的输入权值是随机产生的,随机产生的输入权值在训练中能够满足逼近任何输入数据的条件,下述公式表示通过自编码将输入数据xi映射至高维空间:
35、h(xi)=g(a·xi+b) (5)
36、由此得到原始数据映射至高维空间后的隐含层输出矩阵元,上述公式中,a是一个n×n矩阵,b是隐含层神经元的阈值。
37、多层极限学习机的无监督特征表示是用于提取输入数据多层稀疏特征的基于自编码的elm,相当于是在多层学习结构上的特征提取器,其功能是使用编码输出通过最小化重建误差去逼近输入,使经过特征提取后的数据更好地用于有监督特征分类,提高样本分类精度。
38、本发明的有益效果是:多层极限学习机算法可以更好地处理复杂的建模问题,有助于减少过拟合情况的发生,同时还可以有效地减少训练模型所需的时间;采用麻雀搜索算法对多层极限学习机的隐含层权值进行优化,提升光伏发电功率预测模型的稳定性和预测精度,从而提高电网稳定性,增加电网消纳光电能力,光伏功率预测精准度高,光伏并网给电网的安全运行带来的影响小,能够有效地帮助电网调度部门做好各类电源的调度计划。
- 还没有人留言评论。精彩留言会获得点赞!