一种基于YOLOv7-WFD模型的安全帽检测方法及装置
本发明属于目标检测,具体涉及一种基于yolov7-wfd模型的安全帽检测方法及装置。
背景技术:
1、近年来,基于图像或视频的目标检测已成为计算机视觉领域的研究热点之一。目标检测网络模型具备同时判断和识别多个目标类别与位置的能力,因此在解决工程安全问题方面具有广泛应用价值。
2、在工程行业内,建筑业是事故风险较高的行业之一,为了降低风险,在施工过程中,通常要求工人们佩戴安全护具。安全帽作为工人最基本的个人防护装备之一,在保护工人的生命安全方面具有极其重要的作用。然而,由于现场监管不利以及工人安全意识的不高,因未佩戴安全帽而导致的工地伤亡事故通常会造成巨大的生命和财产损失。据统计,在建筑行业中,工人的伤亡率一直居高不下,其中头部损伤占据了所有伤害的20%以上。为了降低伤亡率,工地迫切需要一个有效的监管系统来监督工人是否佩戴安全帽。过去,大部分施工现场主要依靠人工管理对安全帽佩戴进行监管。然而,由于施工现场的人流量大、作业范围广,人工监管的效率一直较低。随着科技的发展,视频监控的普及度越来越高,逐渐成为安全帽检测系统的主要手段。然而,传统的视频监控智能进行视频录制而没有视频分析的功能,最终的决策仍然依赖于人类的判断,自动化程度不高;而基于深度学习中的目标检测算法则成为提高自动化程度的重要工具。
3、传统的目标检测算法采用基于滑动窗口的区域选择策略,这种方法缺乏针对性,并且复杂度较高。此外,手工设计的特征提取器在处理多样化目标时的鲁棒性不强。随着科技的发展,现代计算机已经能够满足深度学习对于计算量的需求,因此具备强大学习能力的深度学习被广泛应用于图像处理和目标检测领域。目前,许多目标检测任务已经放弃了传统的方法,转而采用基于卷积神经网络的方法,例如cnn、faster-cnn。这些方法的优点在于不需要手动设计特征提取器,在提取图像特征方面具有更高的效能。与传统目标检测算法相比,基于卷积神经网络的方法在检测速度和精度上取得了巨大的提升,但是针对特定应用场景仍有很大的提升空间。
技术实现思路
1、发明目的:本发明提供一种基于yolov7-wfd模型的安全帽检测方法及装置,能快速、精确的检测出工人是否佩戴安全帽。
2、技术方案:本发明所述的一种基于yolov7-wfd模型的安全帽检测方法,包括以下步骤:
3、(1)预先获取工地现场原始图像,并对图像进行预处理;
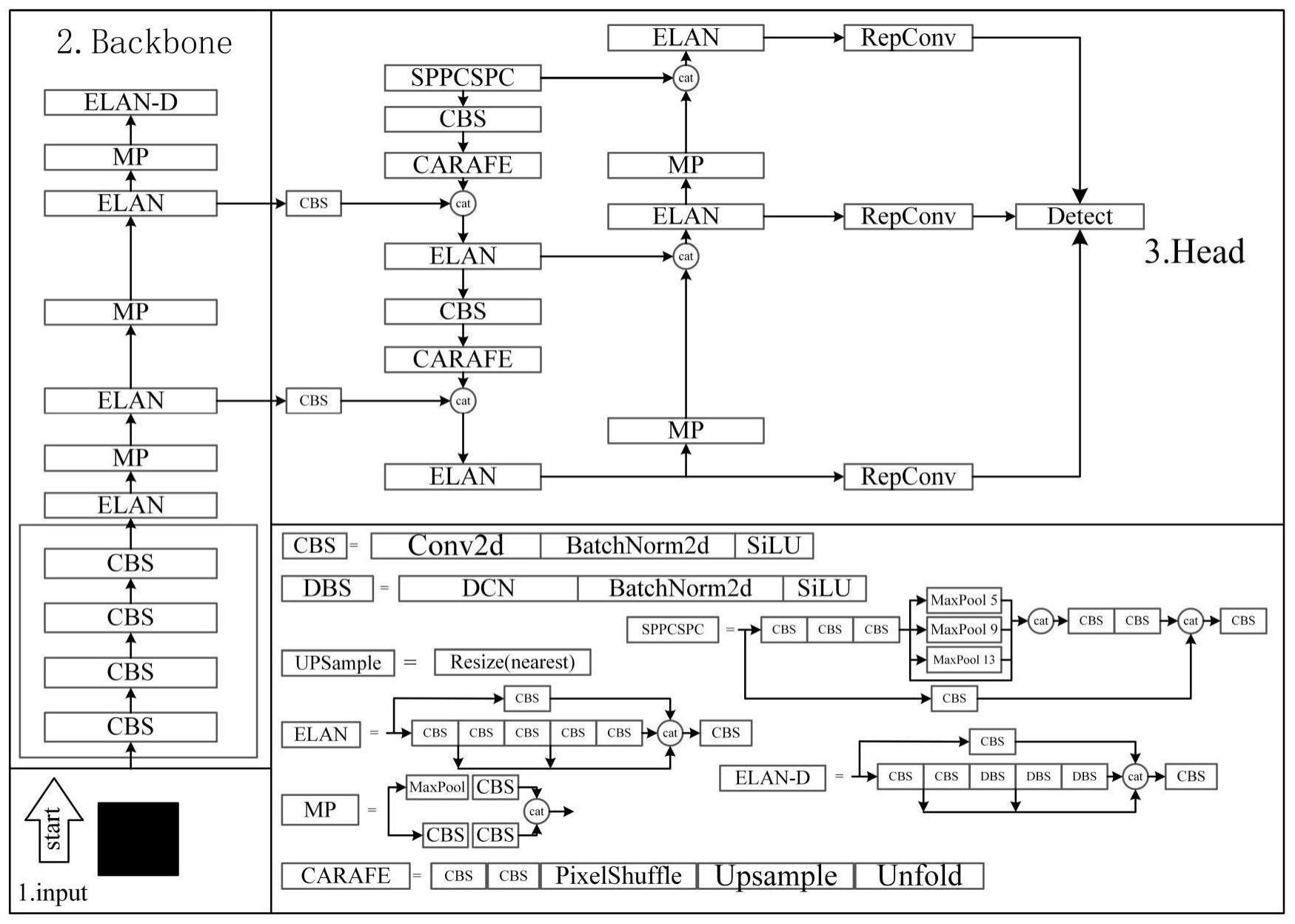
4、(2)构建yolov7-wfd模型:在原始的yolov7模型中,将主干中的最后一个elan模块替换为elan-d模块,即将原elan模块中的部分cbs替换为dbs;所述dbs模块由一个可变形卷积层dcn、一个归一化层和silu激活函数组成;另外,将头部中的upsample模块替换为carafe上采样算子,扩大模型视野范围;
5、(3)训练yolov7-wfd模型,并使用结合了动态非单调聚焦机制的wise-iou损失函数作为边界框回归损失评价yolov7-wfd模型性能;
6、(4)将待检测的图像输入经过训练好的改进的yolov7-wfd模型中,输出检测结果。
7、进一步地,步骤(2)所述可变形卷积层dcn实现过程如下:
8、给出一个输入的rgb图片,与当前像素p0,dcn算子公式表示为:
9、
10、其中,c表示通道数,h表示图片的长度,w表示图片的宽度,g表示分组总数,j表示采样点总数,k枚举采样点,wg表示第g组的投影权重,mgk表示第g组和第k个网格采样点的位置无关投影权重,通过sigmoid函数进行归一化,表示输入特征图的被切割一部分,pk表示预定义网格采样的第k个位置是正则卷积,△pgk表示第g组和第k个网格采样点对应的偏移量,且经过dcn算子处理过后图片的通道数c'=c/g。
11、进一步地,步骤(2)所述carafe上采样算子包括核预测模块和内容感知重组模块;
12、所述核预测模块根据目标位置的内容通过预测生成自适应重组内核,重组核的大小为kup×kup:
13、wl'=ψ(n(xl,kencoder))
14、核预测模块ψ根据内容和邻域的感知生成重组核,并为每个位置l′=(i′,j′)预测基于位置的核wl';
15、所述内容感知重组模块应用加权和算子φ对以l=(i,j)为中心的n(xl,kup)区域进行特征重组,以下为重组公式:
16、
17、其中,r=[kup/2]。
18、进一步地,所述核预测模块包括通道压缩器、内容编码器和内核归一化器;
19、所述通道压缩器通过采用1×1卷积层将输入特征通道从c压缩为cm,允许后续内容编码器中使用更大的内核大小;
20、所述内容编码器应用内核大小kencoder的卷积层来根据输入特征的内容生成重组内核;编码器的参数为:kencoder×kencoder×cm×cup,
21、所述核归一化器对于每个重组核,使用softmax函数进行归一化,保证核的权重和自适应性。
22、进一步地,步骤(3)所述wise-iou的计算公式如下:
23、
24、
25、其中,b表示预测边界框的质心,bgt表示真实边界框的质心,ρ表示b和bgt之间的欧几里得度量,d是包含预测边界框和地面真实边界框的最小封闭区域的对角线距离,iou为预测边界框与真实边界框之间的交并比;wg和hg分别为预测边界框和地面真实边界框的最小封闭区域的宽与长,*表示将wg和hg从计算图中分离出来,以避免产生影响收敛的梯度;r表示梯度增益,β表示异常值的程度,α和δ是超参数。
26、进一步地,步骤(2)所述carafe采用一组固定的超参数,其中通道压缩器的cm为64,内容编码器的kencoder=3,kup=5,上采样系数σ=2。
27、基于相同的发明构思,本发明还提出一种装置设备,包括存储器和处理器,其中:
28、存储器,用于存储能够在处理器上运行的计算机程序;
29、处理器,用于在运行所述计算机程序时,执行如上所述的基于改进的yolov7-wfd模型模型的安全帽检测方法步骤。
30、基于相同的发明构思,本发明还提出一种存储介质,所述存储介质上存储有计算机程序,所述计算机程序被至少一个处理器执行时实现如上所述的基于改进的yolov7-wfd模型模型的安全帽检测方法步骤。
31、有益效果:与现有技术相比,本发明的有益效果:本发明构建的yolov7-wfd模型提出了一种新的模块dbs,该模块中使用了可变形卷积层替代原cbs中的常规卷积层,实现了模型对输入数据的采样偏移量和调制标量自适应调整的能力,从而实现了自适应空间聚合;这一方法降低了正则卷积的过归纳偏置,并且仍然采用常见的3x3卷积窗口,避免了大密度核所带来的优化问题和高昂的计算成本;引入了carafe上采样算子,通过该算子,模型能够获得更广阔的视野,不再局限于利用亚像素邻域的差异;相反,它能够在更大的接受域中聚合上下文信息;此外,carafe上采样算子不再对所有样本使用固定的内核,而是支持特定于实例的内容感知处理,从而能够动态生成自适应内核;通过采用结合了动态非单调聚焦机制与wise-iou损失函数作为边界框回归损失,使得检测器能够考虑不同质量的锚盒,从而提升检测任务的整体性能,这一策略还能够评估锚盒质量的“离群值”,进一步提高模型的鲁棒性和准确性;基于以上实现了是否佩戴安全帽的精准快速检测。
- 还没有人留言评论。精彩留言会获得点赞!