一种基于多头注意力机制的慕课学习者识别方法与流程
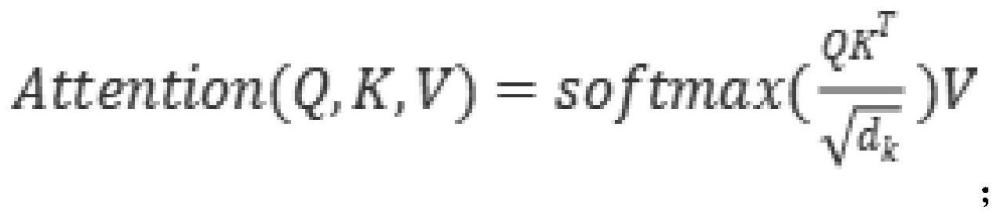
本发明涉及信息数据,具体涉及一种基于多头注意力机制的慕课学习者识别方法。
背景技术:
1、近年来,随着教育大数据概念的普及和学习分析技术的发展,学习者在慕课平台上的行为数据逐渐成为慕课相关研究的重要参考[1][2]。慕课学习者在平台上的活动得到记录,为相关研究提供了更真实的第一手资料。同时,随着社交平台的普及,学习者的学习不仅限于某个平台,越来越多的研究者关注到慕课学习不仅发生在慕课平台上。一些国外研究表明,一部分学习者也会选择在慕课平台之外的社交平台上进行交流[3]。社交平台拥有庞大的用户群和个人社交圈。学习者的心得、疑问、情绪会被他人关注,并可能得到更及时地反馈,在某种程度上,它比慕课的论坛更具互动性。因此,这些社交工具是学习者交流的重要方式。通过研究社交平台中学习者的数据,分析学习者的规则,教师和学习平台可以更好地理解学生的学习体验和学习过程,让课程和平台更好地满足学习者的学习需求和社交需求,提供更适合学习者的服务。然而社交平台用户鱼龙混杂,除慕课学习者外还包括学习机构(如中国大学慕课,慕课网等)。要了解真正的慕课学习者的学习模式和特征以及他们如何相互交流,第一步是识别学习者和其他用户。面对冗杂的社交平台数据,如何使用算法快速高效地甄别用户是否为慕课学习者成为了一个非常有意义的课题。如何快速识别用户是否为慕课学习者成为了慕课相关的科研领域一个非常有意义的课题。
2、根据用户的言论识别用户是否为慕课学习者实质上是一个短文本分类问题。经典的短文本分类方法主要是基于传统机器学习算法构建的,主要包括支持向量机(svm),朴素贝叶斯分类器(nbc),k-最近邻(knn)和决策树(dt)和中心向量法[4]等。这些算法是浅层机器学习方法,忽略了单词与单词之间的关系以及句子与句子之间的关系,对高维数据的处理和泛化能力相对较差。随着深度学习的兴起,特征表示学习逐渐成为机器学习的一个新分支,解决了浅层结构算法表达复杂函数能力有限的问题。该方法被证实可以很好地解决图像和语音领域的许多问题,因为它们的原始数据是连续稠密的数据,且局部相关。想要将深度学习方法应用在文本领域,这其中的关键就是找到一种连续稠密的表示方法来表示文本数据,然后利用cnn/rnn等深度学习模型的自动提取特征表达的能力,节省下复杂的人工提取特征的环节,实现真正端到端解决文本分类问题。几年来,许多受到广泛认可的词向量方法被提出,word2vec[5]、glove[6]、elmo[7]等词向量加速了自然语言处理领域的发展。
3、随着深度神经网络(dnn)的发展,性能越来越强大的模型相继出现。近年来,在短文本分类问题中几,深度神经网络得到了广泛重视。研究者利用神经网络的强大的数据拟合特性,寻找短文本数据中隐含的特征规律。fasttext[8]方法做了最初的尝试,短文本可以表示为词的序列,通过将输入的词转化为词向量,在通过基础的神经网络映射至中间层,计算他们的平均,得到序列的表示,再通过计算得到这段文本属于某一个标签的概率。随后研究者们提出了深度卷积神经网络、深度递归神经网络等模型,并应用在了短文本分类中,如textcnn[9]、textrnn[10]、c-lstm[11]等,通过精心设计的模型获取句子中不同尺度的信息,其中cnn主要被用来提取句子中类似n-gram的关键信息,rnn则更多关注于句子中的序列信息。在attention[12](注意力)机制被提出后,越来越多的现有方法与attention机制结合取得了更好的效果。比较经典的工作是使用双向lstm网络结合attention机制。句子中的词汇首先经过双向lstm网络,对与分类无关的词语的语义进行过滤或者保留较小的数值,从而留下较为重要的语义。将获得的结果经过拼接然后再输送到attention层。attention层给不同的词汇根据重要性赋值。最后将权重与lstm层的结果进行线性求和,所得结果输出到全连接层,经过softmax得到分类结果。
4、上述技术中的方法对attention机制的应用较为简单,且使用的模型多为递归神经网络的变体,这种模型依照序列顺序获取文本中词语间的关系,但难以捕捉文本中远距离的依赖关系,同时由于其递归计算的特性,难以进行并行化计算,因此本发明提出一种基于多头注意力机制的慕课学习者识别方法。
技术实现思路
1、针对现有技术所存在的上述缺点,本发明的第一目的在于提供一种基于多头注意力机制的慕课学习者识别方法,解决上述背景技术中的问题。
2、为实现上述目的,本发明提供了如下技术方案:
3、一种基于多头注意力机制的慕课学习者识别方法,包括以下步骤:
4、s1、数据的获取;
5、s2、数据的筛选;
6、s3、数据预处理;
7、s4、计算模型的构建。
8、通过采用上述技术方案:利用爬虫收集并预处理社交平台慕课相关数据,建立数据集,利用基于多头注意力机制的深度神经网络学习文本中的特征信息,可以实现对社交平台中慕课学习者的识别。
9、进一步的,所述步骤s1中,数据获取的具体为:使用爬虫程序从新浪社交平台获取了从2011年1月1日起至2017年12月31日以“慕课”或“慕课”为关键词的社交平台文本(下称慕课社交平台文本)。
10、通过采用上述技术方案:通过爬虫程序能够获取往年大量的数据,方便进行数据的比对和筛选。
11、进一步的,所述步骤s2中,数据的筛选具体为:2013年与2014年的数据获取较为充分,数据量较大,本研究选取2014年和2015两年全年的社交平台数据作为研究的数据集。
12、通过采用上述技术方案:能够筛选掉不符合条件的数据信息,从而提高最后结果的准确性。
13、进一步的,所述步骤s3中,数据处理的步骤为:
14、1)、删除掉无意义的文本及符号,如除了、但、当、的、了、《》、“”等;
15、2)、进行分词,并保存分词结果;
16、3)、将数据集随机打乱顺序,保证输入算法模型数据顺序的随机性,再根据比例将数据集分为训练集和测试集。
17、通过采用上述技术方案:能够预先去除选取的数据中无效数据,从而避免在后期计算过程中影响计算结果。
18、进一步的,所述步骤s4中,计算模型的构建具体为:transformer模型是由多个相同的编码、解码单元堆叠而成,本技术中完成了文本分类任务只需要用到编码单元,编码单元主要由multi-head self-attention和feed forward模块组成,并使用了residualconnection以及layer-normalization加速模型收敛。
19、通过采用上述技术方案:通过对计算模型的构建能够系统化的对数据进行计算,进一步提高计算的效率。
20、进一步的,multi-head self-attention由self-attention机制延伸而来,self-attention机制计算了文本序列中词语间的关联程度,更好地将序列的上下文信息编码进每一个词语的表示中,同时由于self-attention的计算机制,它完全不受词语间距离的影响,可以更好地捕捉到序列中的远距离依赖关系;前馈神经网络模块由两个线性变换组成,中间有一个relu激活函数。
21、进一步的,self-attention的公式如下:
22、
23、relu激活函数的对应到公式的形式为:
24、pnn(x)=max(0,xw1-b1)w2-b2
25、multi-head self-attention的具体算法为:
26、multihend(q,k,v)=concat(head1,...,headh)w0
27、
28、通过采用上述技术方案:可以使用算法进行预测。
29、有益效果
30、采用本发明提供的技术方案,与已知的公有技术相比,具有如下有益效果:
31、本发明中self-attention机制计算了文本序列中词语间的关联程度,更好地将序列的上下文信息编码进每一个词语的表示中,同时由于self-attention的计算机制,它完全不受词语间距离的影响,可以更好地捕捉到序列中的远距离依赖关系,multi-headself-attention是进一步完善的self-attention,为self-attention提供了多个表示子空间,在multi-head self-attention中,我们有多个query/key/value权重矩阵,这些集合中的每个矩阵都是随机初始化生成的,然后通过训练,用于将词向量投影到不同的表示子空间中。我们为每个attention head都独立维护一套q/k/v的权值矩阵,对于每一个输入,同时计算这些不同的head的输出,再将不同head的输出拼接在一起并通过神经网络映射到与输入相同的维度,从而可以作为下一个模块的输入,配合利用爬虫收集并预处理社交平台慕课相关数据,建立数据集,利用基于多头注意力机制的深度神经网络学习文本中的特征信息,可以实现对社交平台中慕课学习者的识别。
- 还没有人留言评论。精彩留言会获得点赞!