联合高分辨率CNN和轻量级Transformer的密集人群计数方法
本发明涉及人群计数,具体涉及一种联合高分辨率cnn和轻量级transformer的密集人群计数方法。
背景技术:
1、人群计数旨在通过计算机视觉技术获取图像中人群数量。这项技术具有重要的学术研究价值和应用价值,在公共安防、智能监控和疫情防控等领域被广泛应用。还可以扩展细胞镜检测、车辆计数等相关领域。目前,很多基于深度学习的人群计数方法被不断提出。特别是基于深度神经网络的密度估计法。这种方法利用经过精心构建的网络模型对密度图进行回归,然后通过对预测密度图积分求和来得到总人数。
2、(一)分析关于人群计数的专利技术
3、申请号为201911161705.0的中国发明专利申请《人群密度估计方法》根据预设阈值使用alexnet网络将人群图片数据集分为密集与稀疏两类,然后针对这两类图像密度特征的不同将其分别送入对应的特征提取网络,从而获取更好有效的人群密度估计特征。但该方法需分别训练alexnet分类网络、密集数据特征提取网络和稀疏数据特征提取网络,导致计算过程繁琐复杂,且图片数据的分类选择错误将会严重影响计数准确度。
4、申请号为202010170236.5的中国发明专利申请《基于级联高分辨卷积神经网络的密集人群计数算法》利用级联式高分辨卷积神经网络chrnet提取密集人群图像高分辨率特征,并采用分区域损失加权的方式,通过使用mse和计数误差两种损失函数进行网络参数优化。其不足之处在于该算法人为设定不同区域及两种不同损失之间的权重,而密度图的优化质量对权重的设置较为敏感,计数结果会因权重设置不当造成较大的偏差。
5、申请号为202211557637.1的中国发明专利申请《一种基于多尺度融合卷积网络的人群计数方法及系统》,提出在vgg16初级特征提取网络后使用多尺度融合卷积网络的来有效提取多尺度信息。但该方法的主干网络采用单列结构,难以实现多层次特征的提取和融合,且多尺度融合卷积网络的融合方式较为简单,不利于对高复杂度的图像场景进行有效的建模。
6、(二)分析基于深度神经网络的人群计数研究
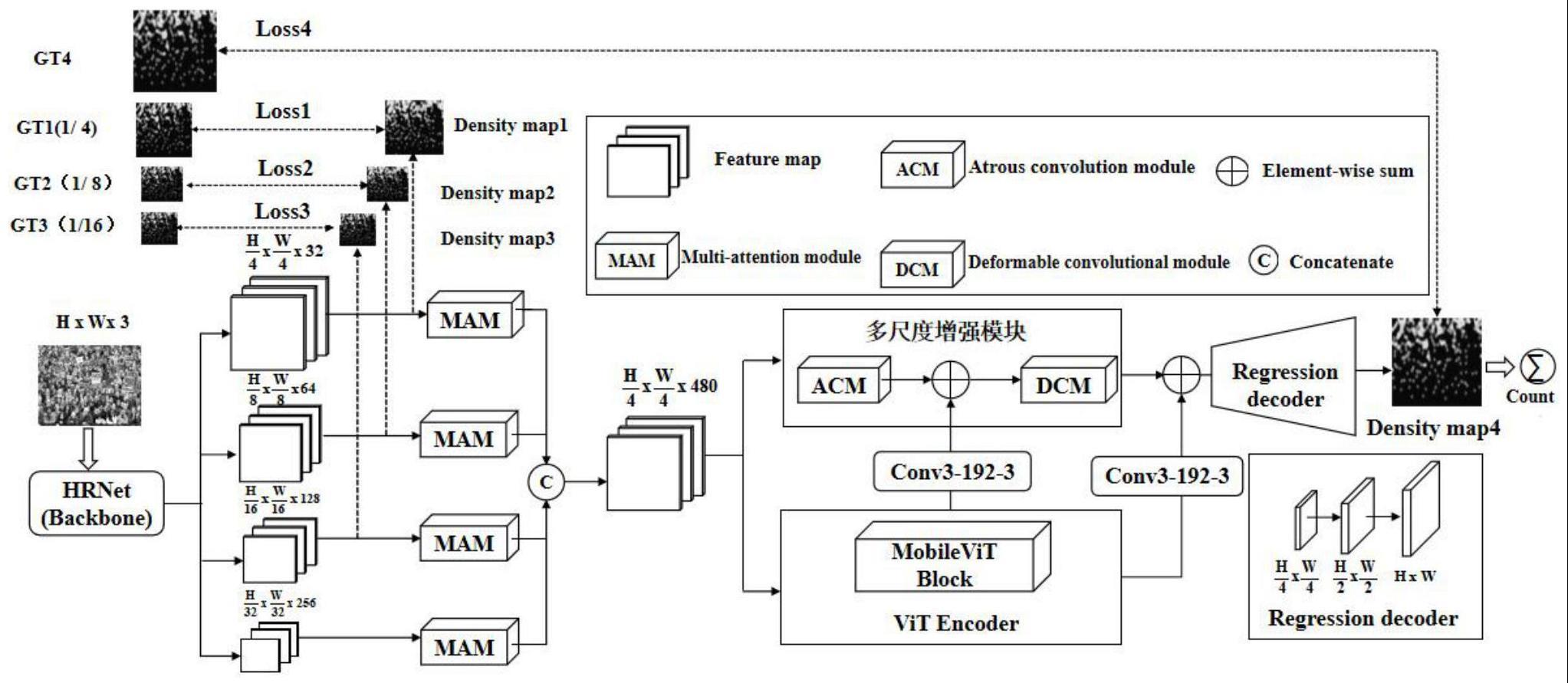
7、li等人提出了一种名为csrnet的基于vgg-16架构的计数网络(《proceedingsofthe ieee conference on computervision and pattern recognition》会议纪要,2018年第1091-1100页)。该网络通过在后端网络中增加空洞卷积层来拓展感知范围和特征提取能力。然而,csrnet网络中存在大量池化操作、步长大于1的卷积层,生成的密度图大小仅为原始输入大小的1/8,可能无法包含足够多的小尺度目标特征信息,导致其在一些复杂场景下的性能受到限制。对于密集人群或小尺度目标,低分辨率特征不利于精确预测。
8、gao等人在提出的计数网络scar中引入了空间和通道注意力机制(《neurocomputing》期刊,2019年第363卷第1-8页)。空间注意力机制用于编码整张图像的像素级上下文信息,以提高模型在像素级上预测密度图的精度;通道注意力机制则用于提取不同的特征信息,使模型对噪声背景更加稳健。该模型中使用的这两种注意力机制可以更好地关注局部细节,但难以捕获全局特征来进行全局上下文建模,从而影响模型对于整个场景的理解。
9、liang等人提出了基于vision transformer(vit)的人群计数网络transcrowd(《science china
10、information sciences》期刊,2022年第6期第104-120页),成功地将transformer引入到人群计数领域。该模型采用vit作为主干网络来进行全局上下文建模,并于弱监督的形式取得较为理想的计数结果。然而,基于纯vit的计数模型往往计算成本较高,导致模型难以训练和优化,更不利于模型在移动端的部署应用。
技术实现思路
1、本发明旨在克服前述的现有技术中存在的多尺度特征融合不够紧密、特征分辨率较低、网络难以训练等难题,提供一种能保持人群特征高分辨率并提升人群预测精度的方法。
2、本发明采用改进的高分辨率特征提取网络hrnet作为前端网络,将其特征图输出大小维持在原始输入大小的1/4,产生丰富的高分辨率表示,有助于保持感受野信息的丰富性,进一步提高提高预测密度图的准确度;采用轻量的vit encoder来建模复杂的全局上下文,并使用多尺度特征增强加来加强特征提取,有效缓解多尺度变化、透视效应等因素对计数结果的影响。
3、为了达到上述目的,本发明提供一种联合高分辨率cnn和轻量级transformer的密集人群计数方法,包括以下步骤:
4、步骤s1:利用固定高斯核法计算人群图像中人头的尺度大小,生成用于网络训练的监督密度图;
5、步骤s2:构建基于高分辨率特征提取网络hrnet和轻量级transformer的人群计数网络;
6、步骤s3:对人群数据集进行数据增广,利用训练集对步骤s2中构建的计数网络进行多密度图训练,筛选保存最优模型;
7、步骤s4:利用测试集对步骤s3得到的最优网络模型进行测试,并通过对网络预测的密度图像素值进行累加求和,得到图片人群最终的计数结果。
8、进一步地,步骤s2的具体过程如下:
9、步骤s2-1:利用预训练的高分辨率特征提取网络hrnet下的特征提取模块stage1-4提取输入图像的初级特征,得到四个分辨率不同、通道数不同的初级特征图。进一步利用核大小为1×1的卷积层分别对分辨率最高的三个初级特征图作特征提取,得到三个不同分辨率大小的初级密度图density map1、density map2和density map3,这三个初级密度图的通道数为1,垂直高度和水平宽度分别为原始输入尺度的1/4、1/8和1/16;
10、步骤s2-2:构建多注意力模块,基于四个不同分辨率的初级特征图,分别执行多种注意力操作,并按通道连接方式融合形成新的注意力特征图;
11、步骤s2-3:构建并行的多尺度增强模块和vit encoder特征提取模块,利用并行连接的vit编码器和多尺度增强模块对融合后的注意力特征图进行全局上下文建模及多尺度特征增强;
12、步骤s2-4:构建解码器模块,将特征增强及全局上下文建模后的特征图送入解码器模块进行解码,以将特征图尺寸恢复到原始输入大小,预测得到最终的预测密度图density map4。
13、进一步地,步骤s2-2的具体过程如下:
14、步骤s2-2-1:将四个初级特征图送入自注意力和通道注意力子模块,每一个初级特征图分别产生自注意力特征子图和通道注意力特征子图;
15、步骤s2-2-2:使用一个动态权重生成机制(由卷积层和sigmoid激活函数组成的网络)为这两种注意力特征子图计算权重;
16、步骤s2-2-3:将输出的这两种权重相加得到总权重,权重的和被用于对这两种注意力权重输出进行归一化;
17、步骤s2-2-4:使用预先生成的自注意力特征子图和通道注意力特征子图分别与它们的归一化后的权重相乘,随后相加形成加权后的注意力特征图;
18、步骤s2-2-5:以最大分辨率的注意力特征图为基准,采用近邻插值方法对其它三分支输出的注意力特征图进行上采样,并按通道连接的方式融合成包含480通道的注意力特征图。
19、进一步地,步骤s2-3的具体过程:
20、步骤s2-3-1:将步骤s2-2得到的注意力特征图分别输入vit编码器和多尺度增强模块中的空洞卷积子模块,输出两个中间特征图;
21、步骤s2-3-2:使用卷积层将vit编码器输出的特征图的通道和空洞卷积模块输出的特征图的通道调为一致,以元素加法的方式将两种通道相同的中间特征图相加;
22、步骤s2-3-3:将步骤s2-3-2融合后的特征图送入多尺度增强模块中的可变形卷积子模块,得到进一步增强后的特征图;
23、步骤s2-3-4:将vit编码器输出并经通道转换后的特征图与步骤s2-3-3得到的增强后的特征图以元素相加的方式相加,得到进一步融合后的特征图。
24、进一步地,步骤s3对人群数据集进行数据增广,并进行多密度图监督训练,具体过程如下:
25、步骤s3-1:为了增强训练数据,使用随机裁剪和水平翻转,其中,裁剪尺寸为256×256,翻转概率为0.5;
26、步骤s3-2:通过计算最终预测的密度图(density map4)和预测的初级密度图(density map1、density map2、density map3)与它们的gt密度图之间的加权损失之和来进行多密度图监督训练,以增强中间特征图的鲁棒性,进而促进最终密度图回归的准确性;
27、步骤s3-3:筛选保存最优模型。
28、本发明与现有技术相比,其优点在于:(1)本发明以改进的高分辨率特征提取网络hrnet为主干网络,不仅能够保持人群特征高分辨率输出,而且可以融合多尺度信息,从而使得预测的特征图在空间上更加精确,特别是对于密集人群或小尺度目标。(2)本发明使用了一种轻量级的vit encoder来建模复杂的全局上下文,并联合多种注意力操作(自注意力、通道注意力)来平衡特征图的全局信息和局部细节,帮助模型更好地区分不同的人群区域和复杂背景,减轻了遮挡、背景和透视等问题的干扰,进一步提升了人群计数的鲁棒性。(3)本发明在cnn分支中构建了结构简单且高效的多尺度特征增强模块,有效地弥补了主干网络在采样操作过程中可能丢失的特征细节,并在一定程度上解决了多尺度问题导致的计数精度不高的问题。(4)本发明采用多密度图监督训练策略进行网络参数优化,充分汇集来自网络不同层、不同分辨率的特征信息进行特征交互。利用不同分辨率密度图之间的相关性,从而更好地学习场景中人群分布状况,显著提升了模型的收敛速度和泛化性能。
- 还没有人留言评论。精彩留言会获得点赞!