一种表格生成方法、装置、设备及存储介质与流程
本发明涉及数据分析,特别涉及一种表格生成方法、装置、设备及存储介质。
背景技术:
1、在数据分析领域,经常需要两个表进行join(用于把来自两个或多个表的行结合起来的方法)操作来获取字段等操作。现有的处理方案大都是直接进行join,但是一旦出现该维度的数据分布较为密集,就会导致内存溢出、性能低下等场景。
2、假设有张表有20亿数据,另外一张维度表有一亿的数据。20亿数据中存在大的重复数据,例如某一个维度出现了几百万甚至几千万行数据。此时两张表根据该维度进行join就有很大可能出现内存溢出的风险,导致程序报错。因此,如何在进行表格数据合并的过程中保持内存的稳定是需要解决的。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种表格生成方法、装置、设备及存储介质,能够解决对两个表格进行join所带来的内存溢出、计算缓慢等风险。其具体方案如下:
2、第一方面,本技术公开了一种表格生成方法,包括:
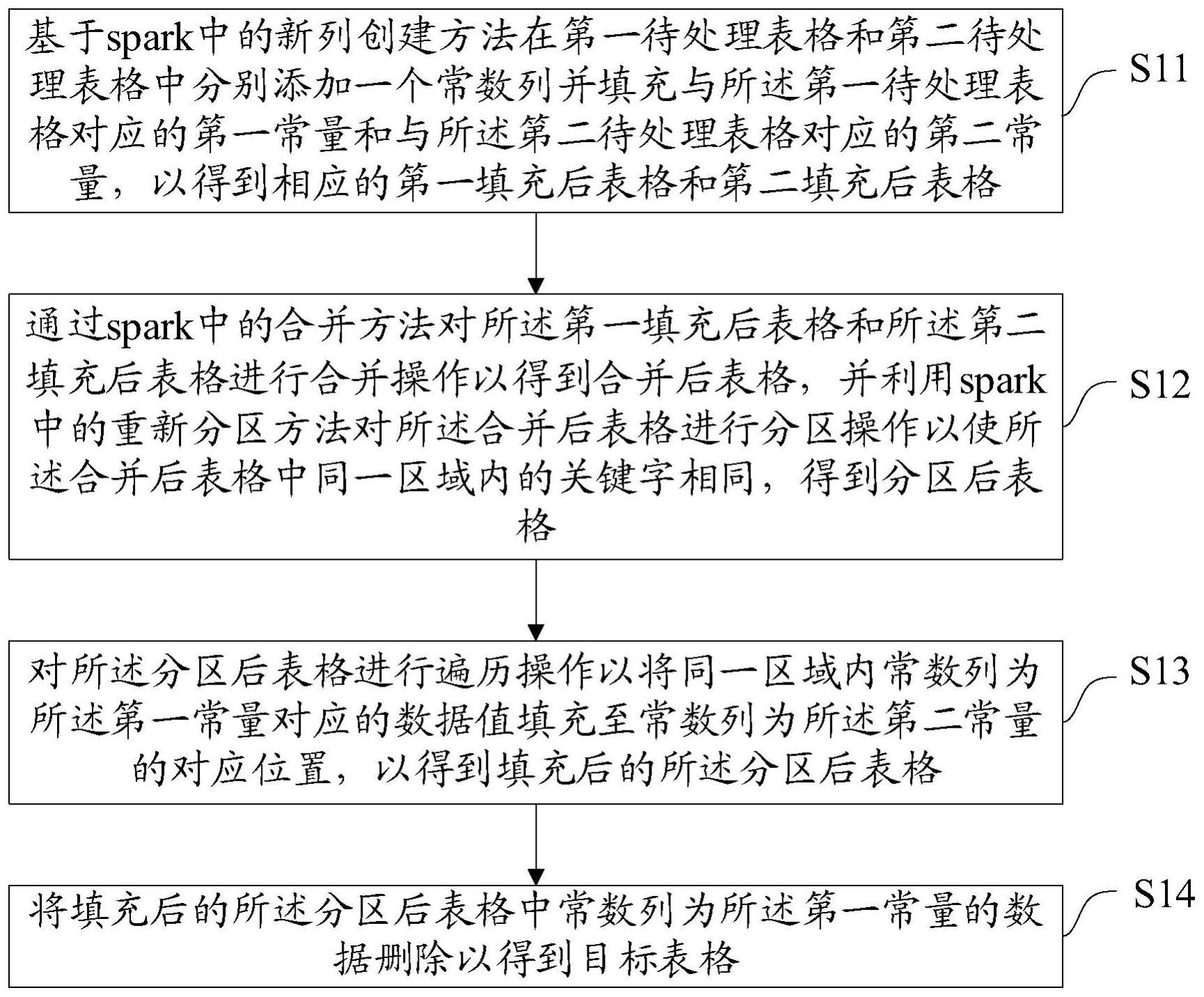
3、基于spark中的新列创建方法在第一待处理表格和第二待处理表格中分别添加一个常数列并填充与所述第一待处理表格对应的第一常量和与所述第二待处理表格对应的第二常量,以得到相应的第一填充后表格和第二填充后表格;
4、通过spark中的合并方法对所述第一填充后表格和所述第二填充后表格进行合并操作以得到合并后表格,并利用spark中的重新分区方法对所述合并后表格进行分区操作以使所述合并后表格中同一区域内的关键字相同,得到分区后表格;
5、对所述分区后表格进行遍历操作以将同一区域内常数列为所述第一常量对应的数据值填充至常数列为所述第二常量的对应位置,以得到填充后的所述分区后表格;
6、将填充后的所述分区后表格中常数列为所述第一常量的数据删除以得到目标表格。
7、可选的,所述第一待处理表格为维度表;所述第二待处理表格为流水表。
8、可选的,所述对所述分区后表格进行遍历操作以将同一区域内常数列为所述第一常量对应的数据值填充至常数列为所述第二常量的对应位置,包括:
9、利用map方法对所述分区后表格进行遍历操作以将同一区域内常数列为所述第一常量对应的数据值填充至常数列为所述第二常量的对应位置。
10、可选的,所述利用spark中的重新分区方法对所述合并后表格进行分区操作以使所述合并后表格中同一区域内的关键字相同之后,还包括:
11、基于所述第一常量和所述第二常量对所述分区后表格中同一区域内的数据进行排序,以得到排序后表格。
12、可选的,所述对所述分区后表格进行遍历操作以将同一区域内常数列为所述第一常量对应的数据值填充至常数列为所述第二常量的对应位置,包括:
13、将所述排序后表格中的第一个数据值确定为当前第一目标数据值;
14、获取所述排序后表格中的下一个数据值作为当前第二目标数据值,并对所述当前第二目标数据值对应的常数列进行判断;
15、若所述当前第二目标数据值对应的常数列为所述第一常量,则将所述当前第二目标数据值确定为新的当前第一目标数据值,并跳转至所述获取所述排序后表格中的下一个数据值作为当前第二目标数据值的步骤,直至所述当前第二目标数据值为所述排序后表格中的最后一个数据值;
16、若所述当前第二目标数据值对应的常数列为所述第二常量,则将所述当前第一目标数据值填充至所述当前第二目标数据值的对应位置,并跳转至所述获取所述排序后表格中的下一个数据值作为当前第二目标数据值的步骤,直至所述当前第二目标数据值为所述排序后表格中的最后一个数据值。
17、可选的,所述将填充后的所述分区后表格中常数列为所述第一常量的数据删除以得到目标表格,包括:
18、通过spark中的过滤方法将常数列为所述第一常量的数据从所述合并后表格中删除以得到目标表格。
19、第二方面,本技术公开了一种表格生成装置,包括:
20、常数列添加模块,用于基于spark中的新列创建方法在第一待处理表格和第二待处理表格中分别添加一个常数列并填充与所述第一待处理表格对应的第一常量和与所述第二待处理表格对应的第二常量,以得到相应的第一填充后表格和第二填充后表格;
21、表格分区模块,用于通过spark中的合并方法对所述第一填充后表格和所述第二填充后表格进行合并操作以得到合并后表格,并利用spark中的重新分区方法对所述合并后表格进行分区操作以使所述合并后表格中同一区域内的关键字相同,得到分区后表格;
22、数据值填充模块,用于对所述分区后表格进行遍历操作以将同一区域内常数列为所述第一常量对应的数据值填充至常数列为所述第二常量的对应位置,以得到填充后的所述分区后表格;
23、数据删除模块,用于将填充后的所述分区后表格中常数列为所述第一常量的数据删除以得到目标表格。
24、可选的,所述数据值填充模块,包括:
25、数据值确定单元,用于将所述排序后表格中的第一个数据值确定为当前第一目标数据值;
26、常数列判断单元,用于获取所述排序后表格中的下一个数据值作为当前第二目标数据值,并对所述当前第二目标数据值对应的常数列进行判断;
27、第一步骤跳转单元,用于若所述当前第二目标数据值对应的常数列为所述第一常量,则将所述当前第二目标数据值确定为新的当前第一目标数据值,并跳转至所述获取所述排序后表格中的下一个数据值作为当前第二目标数据值的步骤,直至所述当前第二目标数据值为所述排序后表格中的最后一个数据值;
28、第二步骤跳转单元,用于若所述当前第二目标数据值对应的常数列为所述第二常量,则将所述当前第一目标数据值填充至所述当前第二目标数据值的对应位置,并跳转至所述获取所述排序后表格中的下一个数据值作为当前第二目标数据值的步骤,直至所述当前第二目标数据值为所述排序后表格中的最后一个数据值。
29、第三方面,本技术公开了一种电子设备,包括:
30、存储器,用于保存计算机程序;
31、处理器,用于执行所述计算机程序以实现前述的表格生成方法。
32、第四方面,本技术公开了一种计算机可读存储介质,用于保存计算机程序,所述计算机程序被处理器执行时实现前述的表格生成方法。
33、可见,本技术中,基于spark中的新列创建方法在第一待处理表格和第二待处理表格中分别添加一个常数列并填充与所述第一待处理表格对应的第一常量和与所述第二待处理表格对应的第二常量,以得到相应的第一填充后表格和第二填充后表格;通过spark中的合并方法对所述第一填充后表格和所述第二填充后表格进行合并操作以得到合并后表格,并利用spark中的重新分区方法对所述合并后表格进行分区操作以使所述合并后表格中同一区域内的关键字相同,得到分区后表格;对所述分区后表格进行遍历操作以将同一区域内常数列为所述第一常量对应的数据值填充至常数列为所述第二常量的对应位置,以得到填充后的所述分区后表格;将填充后的所述分区后表格中常数列为所述第一常量的数据删除以得到目标表格。这样一来,通过spark中的新列创建方法和重新分区方法代替表格join的方法,对于多张表中的列根据相同维度补充到一张表中,得到一个补充了其他表中列的表,表的行数不变,列数增加。解决解决了spark在join时,出现数据倾斜时,会导致内存溢出、计算缓慢、reduce超时等问题。
- 还没有人留言评论。精彩留言会获得点赞!