模型训练和文件类型确定方法、装置及终端设备与流程
本技术实施例涉及人工智能,尤其涉及一种模型训练和文件类型确定方法、装置及终端设备。
背景技术:
1、用户可以通过命令执行环境(webshell)文件,进行对应的网站管理、服务器管理、权限管理等操作。在实际应用过程中,恶意攻击者可以通过webshell文件对网站进行远程访问,导致网站的隐私信息泄露。
2、为了避免网站遭受攻击,可以通过训练完成的模型对网站的脚本文件进行检测,以确定是否存在webshell文件。在相关技术中,可以通过如下方式进行模型训练:从文件对应的文本中提取恶意标签、恶意方法和最长字符长度频率等文本特征。通过机器学习算法创建分类模型,并通过文本特征对分类模型进行训练,得到目标模型。目标模型用于根据文本特征确定对应文件的文件类型,从而确定文件是否为webshell文件。在上述过程中,由于目标模型无法全面识别所有类型的webshell文件。且只通过webshell文件的文本特征得到目标模型,用于确定webshell文件的文件类型,导致模型训练的准确性较低。
技术实现思路
1、本技术实施例提供一种模型训练和文件类型确定方法、装置及终端设备,用以解决模型训练的准确性较低的问题。
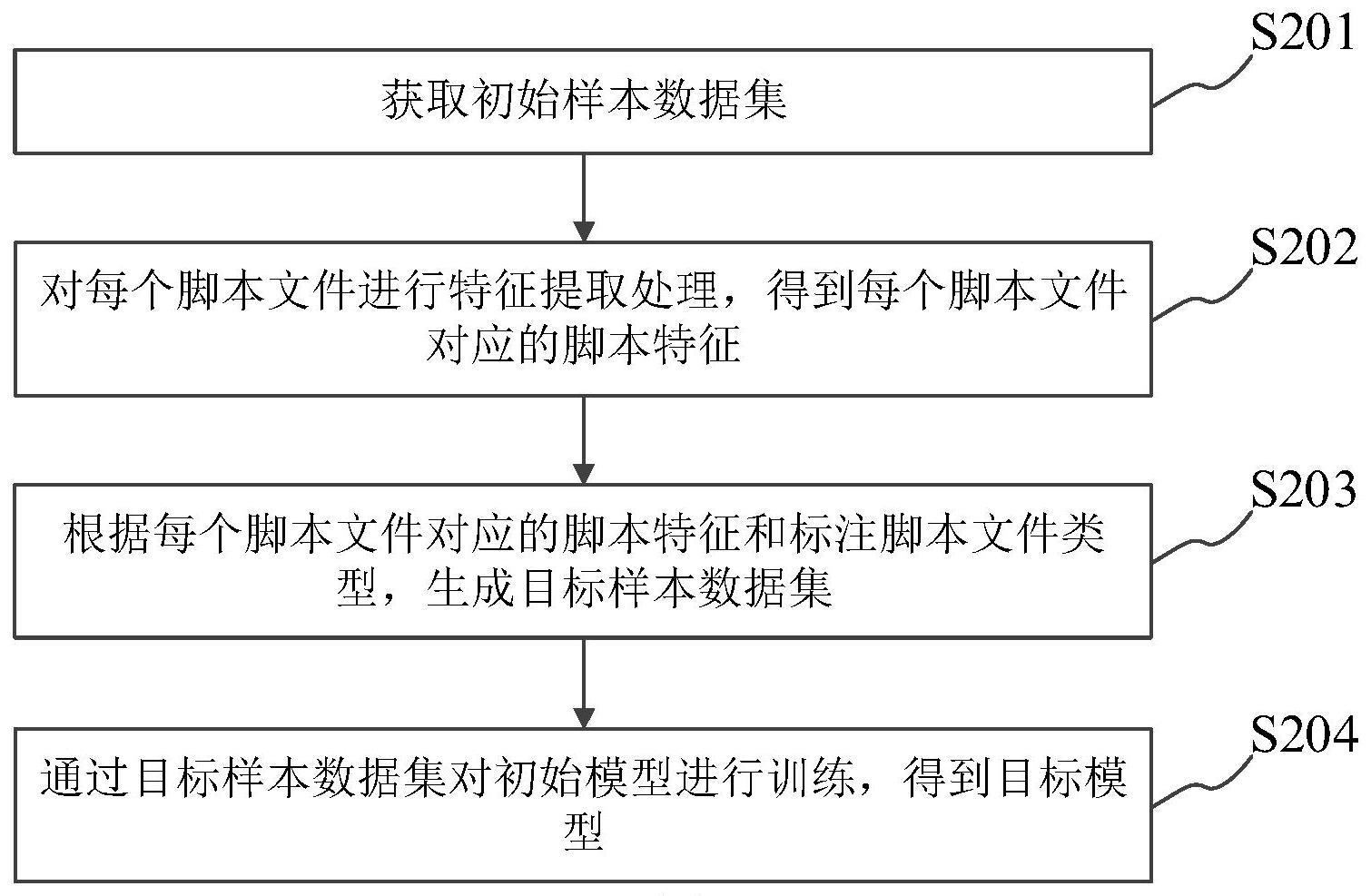
2、第一方面,本技术实施例提供一种模型训练方法,包括:
3、获取初始样本数据集,所述初始样本数据集包括多个脚本文件、以及每个脚本文件对应的标注脚本文件类型;
4、对每个脚本文件进行特征提取处理,得到每个脚本文件对应的脚本特征,所述脚本特征包括至少一个语义特征和至少一个统计特征;
5、根据每个脚本文件对应的脚本特征和所述标注脚本文件类型,生成目标样本数据集,所述目标样本数据集包括多个所述脚本特征、以及每个脚本特征对应的标注脚本文件类型;
6、通过所述目标样本数据集对初始模型进行训练,得到目标模型,所述目标模型用于确定脚本文件对应的脚本文件类型。
7、在一种可能的实施方式中,针对任意一个脚本文件;对所述脚本文件进行特征提取处理,得到所述脚本文件对应的脚本特征,包括:
8、对所述脚本文件进行文本提取处理,得到所述脚本文件对应的语义结构,所述语义结构包括多个节点、以及每个节点对应的分支,所述节点用于指示所述脚本文件的执行操作,所述分支用于指示所述执行操作对应的操作内容;
9、根据所述脚本文件对应的语义结构,确定所述脚本文件对应的至少一个统计特征;
10、对所述脚本文件对应的语义结构进行特征提取处理,得到所述脚本文件对应的至少一个语义特征。
11、在一种可能的实施方式中,所述统计特征包括节点统计特征、分支统计特征和文本统计特征;根据所述脚本文件对应的语义结构,确定所述脚本文件对应的至少一个统计特征,包括:
12、确定所述语义结构包括的节点数量以及分支数量;
13、根据所述节点数量,确定所述节点统计特征包括如下至少一种:所述多个节点的最大深度、平均深度和深度方差;
14、根据所述分支数量,确定所述分支统计特征包如下至少一种:所述多个分支的节点数量、标准差、方差和最大值,以及多个分支的平均分支数、最大分支数和分支方差;
15、根据所述语义结构,确定所述文本统计特征包括如下至少一种:所述脚本文件的信息熵、所述多个节点的信息熵集合的最大值、最小值、标准差和方差。
16、在一种可能的实施方式中,对所述脚本文件对应的语义结构进行特征提取处理,得到所述脚本文件对应的至少一个语义特征,包括:
17、通过预设算法对所述语义结构进行深度优先遍历处理,得到所述语义结构的节点序列特征,所述节点序列特征用于指示所述语义结构中执行操作的先后顺序;
18、通过第一模型对所述节点序列特征进行特征提取处理,得到所述脚本文件对应的至少一个语义特征。
19、在一种可能的实施方式中,所述目标样本数据集包括训练数据集和测试数据集;通过所述目标样本数据集对初始模型进行训练,得到目标模型,包括:
20、通过所述训练数据集对所述初始模型进行多次迭代训练,得到中间模型;
21、通过所述测试数据集对所述中间模型进行更新处理,得到所述目标模型。
22、在一种可能的实施方式中,通过所述训练数据集对所述初始模型进行多次迭代训练,得到中间模型,包括:
23、通过所述训练数据集的多个脚本特征对所述初始模型进行第1次迭代训练,得到第一中间模型;
24、通过所述训练数据集的多个脚本特征对第i个中间模型进行第i+1次迭代训练,得到第i+1个中间模型,所述i依次取1、2、3、……,直至中间模型收敛,并将最后一个中间模型确定为所述中间模型。
25、在一种可能的实施方式中,通过所述训练数据集的多个脚本特征对第i个中间模型进行第i+1次迭代训练,得到第i+1个中间模型,包括:
26、通过所述第i个中间模型对所述训练数据集的多个脚本特征进行处理,得到多个预测脚本文件类型;
27、根据所述多个脚本特征对应的标注脚本文件类型和预测脚本文件类型,确定所述第i个中间模型的召回率和精准率;
28、根据所述召回率和所述精准率,更新所述第i个中间模型的模型参数,得到所述第i+1中间模型。
29、在一种可能的实施方式中,所述方法还包括:
30、当所述召回率大于等于第一预设值,和/或所述精准率大于等于第二预设值,且i大于等于n时,确定所述中间模型收敛,所述n为预设迭代次数。
31、第二方面,本技术实施例提供文件类型确定方法,包括:
32、获取目标文件对应的脚本特征,所述脚本特征包括至少一个语义特征和至少一个统计特征;
33、通过目标模型对所述脚本特征进行处理,得到所述目标文件的目标文件类型,其中,所述目标模型为根据权利要求1-8任一项所述的方法训练得到的。
34、第三方面,本技术实施例提供一种模型训练装置,所述装置包括:
35、获取模块,用于获取初始样本数据集,所述初始样本数据集包括多个脚本文件、以及每个脚本文件对应的标注脚本文件类型;
36、处理模块,用于对每个脚本文件进行特征提取处理,得到每个脚本文件对应的脚本特征,所述脚本特征包括至少一个语义特征和至少一个统计特征;
37、生成模块,用于根据每个脚本文件对应的脚本特征和所述标注脚本文件类型,生成目标样本数据集,所述目标样本数据集包括多个所述脚本特征、以及每个脚本特征对应的标注脚本文件类型;
38、训练模块,用于通过所述目标样本数据集对初始模型进行训练,得到目标模型,所述目标模型用于确定脚本文件对应的脚本文件类型。
39、在一种可能的实施方式中,所述处理模块具体用于:
40、对所述脚本文件进行文本提取处理,得到所述脚本文件对应的语义结构,所述语义结构包括多个节点、以及每个节点对应的分支,所述节点用于指示所述脚本文件的执行操作,所述分支用于指示所述执行操作对应的操作内容;
41、根据所述脚本文件对应的语义结构,确定所述脚本文件对应的至少一个统计特征;
42、对所述脚本文件对应的语义结构进行特征提取处理,得到所述脚本文件对应的至少一个语义特征。
43、在一种可能的实施方式中,所述处理模块具体用于:
44、确定所述语义结构包括的节点数量以及分支数量;
45、根据所述节点数量,确定所述节点统计特征包括如下至少一种:所述多个节点的最大深度、平均深度和深度方差;
46、根据所述分支数量,确定所述分支统计特征包如下至少一种:所述多个分支的节点数量、标准差、方差和最大值,以及多个分支的平均分支数、最大分支数和分支方差;
47、根据所述语义结构,确定所述文本统计特征包括如下至少一种:所述脚本文件的信息熵、所述多个节点的信息熵集合的最大值、最小值、标准差和方差。
48、在一种可能的实施方式中,所述处理模块具体用于:
49、通过预设算法对所述语义结构进行深度优先遍历处理,得到所述语义结构的节点序列特征,所述节点序列特征用于指示所述语义结构中执行操作的先后顺序;
50、通过第一模型对所述节点序列特征进行特征提取处理,得到所述脚本文件对应的至少一个语义特征。
51、在一种可能的实施方式中,所述训练模块具体用于:
52、通过所述训练数据集对所述初始模型进行多次迭代训练,得到中间模型;
53、通过所述测试数据集对所述中间模型进行更新处理,得到所述目标模型。
54、在一种可能的实施方式中,所述训练模块具体用于:
55、通过所述训练数据集的多个脚本特征对所述初始模型进行第1次迭代训练,得到第一中间模型;
56、通过所述训练数据集的多个脚本特征对第i个中间模型进行第i+1次迭代训练,得到第i+1个中间模型,所述i依次取1、2、3、……,直至中间模型收敛,并将最后一个中间模型确定为所述中间模型。
57、在一种可能的实施方式中,所述训练模块具体用于:
58、通过所述第i个中间模型对所述训练数据集的多个脚本特征进行处理,得到多个预测脚本文件类型;
59、根据所述多个脚本特征对应的标注脚本文件类型和预测脚本文件类型,确定所述第i个中间模型的召回率和精准率;
60、根据所述召回率和所述精准率,更新所述第i个中间模型的模型参数,得到所述第i+1中间模型。
61、在一种可能的实施方式中,所述训练模块具体用于:
62、当所述召回率大于等于第一预设值,和/或所述精准率大于等于第二预设值,且i大于等于n时,确定所述中间模型收敛,所述n为预设迭代次数。
63、第四方面,本技术实施例提供一种文件类型确定装置,所述装置包括:
64、获取模块,用于获取目标文件对应的脚本特征,所述脚本特征包括至少一个语义特征和至少一个统计特征;
65、处理模块,用于通过目标模型对所述脚本特征进行处理,得到所述目标文件的目标文件类型,其中,所述目标模型为根据权利要求1-8任一项所述的方法训练得到的。
66、第五方面,本技术实施例提供一种终端设备,包括:
67、至少一个处理器;以及
68、与所述至少一个处理器通信连接的存储器;其中,
69、所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行第一方面任一项,或者第二方面任一项所述的方法。
70、第六方面,本技术实施例提供一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行第一方面任一项,或者第二方面任一项所述的方法。
71、第七方面,本技术实施例提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现第一方面任一项,或者第二方面任一项所述的方法。
72、本技术实施例提供的模型训练和文件类型确定方法、装置及终端设备,获取初始样本数据集,初始样本数据集包括多个脚本文件、以及每个脚本文件对应的标注脚本文件类型。对每个脚本文件进行特征提取处理,得到每个脚本文件对应的脚本特征,脚本特征包括至少一个语义特征和至少一个统计特征。根据每个脚本文件对应的脚本特征和标注脚本文件类型,生成目标样本数据集。通过目标样本数据集对初始模型进行训练,得到目标模型,目标模型用于确定脚本文件对应的脚本文件类型。在上述过程中,由于初始样本数据集包括多种类型的脚本文件,且通过每个脚本文件对应的至少一个语义特征和至少一个统计特征,对初始模型进行训练得到目标模型。目标模型可以根据每个脚本文件对应的至少一个语义特征和至少一个统计特征,确定多种类型的脚本文件。而不是只确定特定类型的脚本文件,提高了模型训练的准确性。
- 还没有人留言评论。精彩留言会获得点赞!