基于对话式大语言模型的高可靠单元测试自动生成方法及装置
本发明属于单元测试自动生成,具体涉及基于对话式大语言模型的高可靠单元测试自动生成方法及装置。
背景技术:
1、随着当今的软件规模越来越大、结构越来越复杂,对软件质量的要求也越来越高。即便是微小的缺陷,也足以使企业蒙受巨大的损失。因此,软件测试作为软件交付的最后一道环节变得越来越重要。在软件测试金字塔中,单元测试作为最大、最基本的组成部分,是整个测试流程中最重要的一个环节。但是,单元测试用例的编写需要耗费大量的时间和精力,因此通常被开发者们所忽略。自动生成单元测试用例技术的出现,就致力于解决这一问题。所谓单元测试用例自动生成,是指自动地生成一组单元测试用例,以覆盖尽可能多的代码路径和代码逻辑,以确保软件单元的正确性和稳定性。采用这种技术生成的单元测试用例,可以提高测试覆盖率,减少手动编写测试用例的工作量,并且可以更早地发现和修复软件中的错误和缺陷。
2、目前,现有的单元测试用例生成方法可以分为三类:基于传统程序分析的方法、基于预训练模型的方法、基于对话式大语言模型的方法。基于传统程序分析的方法通常使用变异测试、随机测试、符号执行等技术来生成单元测试用例;基于预训练模型的方法则使用大规模英文和代码语料库训练预训练模型,并将单元测试用例的生成任务定义为翻译任务,从待测代码直接翻译成测试用例;基于对话式大语言模型的方法通过将待测方法的上下文信息输入预设好的提示模版生成提示,然后通过对话的方式来让大语言模型生成针对待测方法的单元测试。然而,这些方法存在以下尚未解决的技术问题:
3、1.基于传统程序分析的方法生成的单元测试用例其变量名和函数名不具有任何语义,只关注如何实现更高的覆盖率,具有可读性差、测试意图不明显等特点,导致了它们难以被开发人员理解和维护。
4、2.基于预训练模型的方法生成的单元测试用例,在可读性上有一定的优势,但目标方法的覆盖率通常比较低,也即生成的单元测试用例中成功调用目标方法的比例较低。另一方面,成功的单元测试用例的比例也很低,但其中相当一部分比例的测试用例可以通过简单的步骤被修复,而预训练模型不具备交互能力,因而只能够多次生成来弥补这一缺陷。导致生成的测试用例通常在目标方法的覆盖率上不够理想。
5、3.现有的基于对话式大语言模型的方法可靠性不高,通常会存在重复生成、测试输入数据覆盖不全面、断言质量无法保证、生成单元测试用例成功率低的问题。通过多次重复地利用对话式大语言模型对同一个待测方法生成测试可能会出现重复覆盖、搜索不彻底、多次生成的测试相似等问题,无法从根本上保证单元测试的质量。
技术实现思路
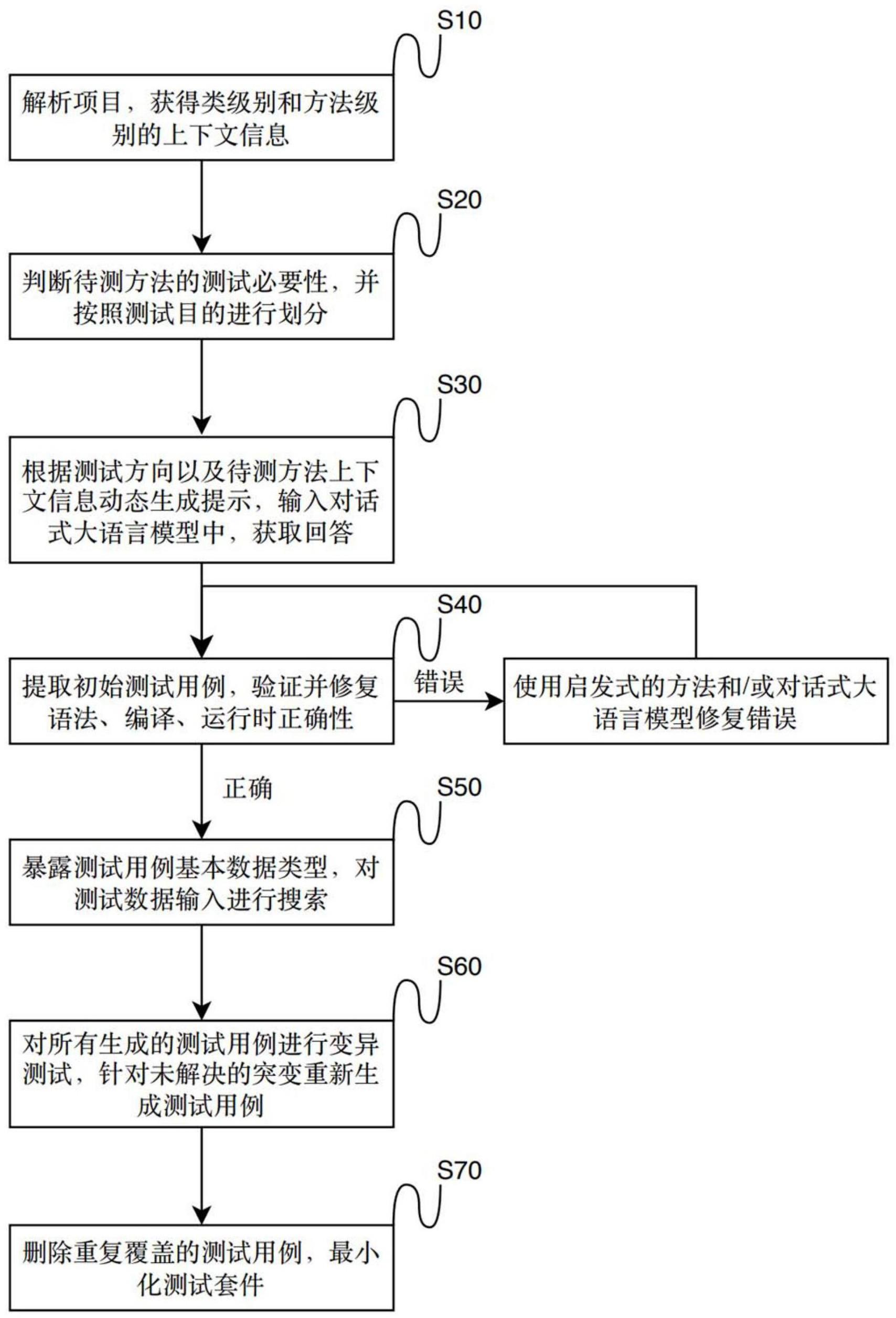
1、基于上述背景,本发明提出了一种高可靠性的基于对话式大语言模型的单元测试自动生成方法,能够实现解析抽象语法树获取类级别的上下文信息,通过对待测方法进行代码可达分析获取方法级别的上下文信息,随后对待测方法进行测试必要性判断,然后根据不同的测试目的划分不同的测试方向,根据不同的测试方向生成初始测试用例,并尝试修复发生错误的测试用例。随后暴露出成功的测试用例的基本数据类型,然后进行测试输入数据的搜索,以尽可能提高测试输入数据覆盖率。之后对已有的测试用例进行变异测试,并针对失败的测试用例进行重新生成,以尽可能提高断言质量。最后,对所有成功的测试用例组成的测试套件进行缩减,避免生成重复覆盖的测试用例。
2、本发明的目的是通过以下技术方案实现的:
3、根据本说明书的第一方面,提供一种基于对话式大语言模型的高可靠单元测试自动生成方法,包括以下步骤:
4、s1,对待测项目进行解析,提取出对象文件,并对对象文件进行解析,从类级别的上下文信息中提取出待测方法列表,针对每个待测方法进行代码可达分析,获取方法级别的上下文信息,包括每个待测方法所使用的依赖类、字段、调用方法;
5、s2,针对每个待测方法,使用对话式大语言模型进行测试必要性判断,如果判断待测方法有测试必要,则会对测试目的进行划分,获取测试方向列表;
6、s3,从测试方向列表中的一个测试方向出发,根据待测方法的代码可达分析结果,使用动态上下文生成技术,在最大提示长度限制下,生成包含尽可能多的待测方法上下文的提示,并将该提示输入对话式大语言模型中,获得包含初始测试用例的回答;
7、s4,从包含初始测试用例的回答中提取出初始测试用例,对初始测试用例进行语法验证,编译并执行该测试用例,如果在此过程中发生了错误,则尝试利用启发式的方法和/或对话式大语言模型修复该错误;
8、s5,针对每个成功的测试用例,首先将测试用例中基本数据类型字段暴露出来,再对测试输入数据的空间进行搜索;
9、s6,针对所有生成的测试用例,采用变异测试的方式对测试用例的断言质量进行验证;针对没有成功解决的突变,将突变信息融入一个新的提示,利用对话式大语言模型再次生成新的测试用例,直到解决突变或达到最大尝试次数;
10、s7,对所有成功生成的测试用例组成的测试套件进行最小化,以保证套件中的测试用例在测试目的、覆盖情况、突变解决情况上不会重复。
11、进一步地,s1具体为:
12、s1.1,遍历整个待测项目,提取出对象文件,并对对象文件进行解析,使用解析器将对象文件解析成抽象语法树ast的形式;
13、s1.2,从抽象语法树的根节点出发,遍历整个抽象语法树,从抽象语法树中提取出类级别的上下文信息,包括包声明语句、引入的外部依赖、类签名、类构造函数、类字段、获取器和设置器的方法签名、以及待测方法列表;
14、s1.3,针对每个待测方法进行代码可达分析,获取方法级别的上下文信息,包括方法体、方法的修饰符、方法是否使用到了字段、方法是否使用到了获取器和设置器、方法所使用的依赖类、调用方法的信息。
15、进一步地,s2具体为:
16、s2.1,针对每个待测方法,将其渲染进一个包含有测试必要性判断和测试目的划分的提示模版中,输入对话式大语言模型,并指定回答格式,通过正则表达式根据回答内容判断测试必要性;
17、s2.2,如果对话式大语言模型判断待测方法有测试必要性时,则根据回答内容获取通过测试目的划分得到的测试方向列表。
18、进一步地,s3具体为:
19、s3.1,根据一个待测方向,以及待测方法所在类的关键信息、待测方法的可达代码块,在确保不超出预设的最大提示长度的情况下,尽可能提供更多的待测方法上下文,渲染成提示;具体为:
20、尝试生成最小上下文,在最小上下文中必须包含方法体、所在类的签名、构造函数的签名、可达字段以及相应的获取器和设置器的签名;如果最小上下文的长度大于预设的最大提示长度,则会取消此次生成测试用例的尝试;
21、根据待测方法是否依赖于外部类来动态添加更多的待测方法上下文;如果待测方法依赖于外部类,则尝试在上下文信息中添加该外部类以及被调用方法的签名,添加信息后会进行提示生成,确保提示的长度小于预设的最大提示长度;如果待测方法没有外部依赖,则尝试在上下文信息中添加待测方法所在类中被调用方法的签名,如果仍然未超出预设的最大提示长度,则尝试在上下文信息中添加待测方法所在类中所有方法的签名;如果在尝试添加更多信息到上下文信息过程中,出现了提示超出预设的最大提示长度的情况,则会停止此次的添加行为;
22、s3.2,在步骤s3.1生成了满足要求的待测方法上下文后,将该上下文按照上下文的内容,渲染至相应的提示模版中;具体为:
23、如果上下文中包含有依赖信息,则将上下文信息渲染至包含有依赖的模版中;如果上下文中不包含有依赖信息,则将上下文信息渲染至无依赖的模版中;最终生成一个满足最大提示长度限制、符合当前测试方向、富含待测方法上下文的提示;
24、s3.3,将s3.2生成的提示输入对话式大语言模型中,获得包含初始测试用例的回答。
25、进一步地,s4具体为:
26、s4.1,提取初始测试用例,如果提取失败,则本次尝试将会被放弃;
27、s4.2,对初始测试用例进行语法验证,具体为:
28、使用语法解析器尝试对有效测试用例进行解析,如果在解析过程出现了错误,则尝试以语句结束符或者代码块结束符作为标志来修复测试用例,如果修复失败,则本次尝试将会被放弃;
29、s4.3,对测试用例的编译正确性进行验证,具体为:
30、使用编译器尝试对测试用例进行编译,如果在编译过程中出现了错误,则将取出的代码片段与待测方法所在的类的包声明语句和导入依赖的语句进行逐行比对,针对测试用例中没有包含的语句,逐一将缺失的语句添加至测试用例中;如果仍然出现了编译错误,则通过既有的规则匹配出最为相关的错误信息,融合错误信息、测试用例、待测方法上下文,生成用于修复错误的提示;如果修复失败,则本次尝试将会被放弃;
31、s4.4在s4.3验证了编译正确性后,执行测试用例;具体为:
32、如果在执行过程中出现了错误,则通过既有的规则匹配出最为相关的错误信息,融合错误信息、测试用例、待测方法上下文,生成用于修复错误的提示;如果修复失败,则本次尝试将会被放弃。
33、进一步地,s4.1具体为:
34、测试用例在大语言模型的回答中主要有两种存在形式,一种是存在明确定界符,且回答将测试用例包含在起始和结束定界符中;另一种则是没有明确的定界符;
35、针对第一种形式的回答,采用正则表达式来匹配并提取出回答中所有的代码片段;对所有代码片段进行筛选,筛选出同时包含有“@test”、“class”、“import”关键词的代码片段作为一个有效的测试用例;
36、针对第二种形式的回答,采用定界法来界定包含测试用例代码片段的上界和下界;具体地,首先定位到包含有“class”+方法名+“test”关键词所在的行,并以该行作为起始行,分别向上和向下寻找边界;在寻找边界的过程中,判断一行的结束字符是否被允许作为一个语句的结束字符,,如果允许则判断该行是代码片段中的一部分,否则判断该行为代码片段的边界。
37、进一步地,s5具体为:
38、s5.1,针对每个成功通过的测试用例,对其进行解析,记录基本数据类型的赋值语句作为搜索的入口;
39、s5.2,开始搜索过程,对基本数据类型所有可能出现的值进行枚举和组合,之后修改原测试用例中的赋值语句形成新的测试用例,执行测试用例并记录其执行结果,包括覆盖率和测试通过情况;不断重复执行直到所有可能出现的值都已经被遍历或者达到了最大的搜索时间限制,搜索结束;
40、s5.3,根据搜索过程中的执行结果,将所有的测试输入数据进行分类,最后只保留不同覆盖情况且执行通过的测试用例。
41、进一步地,s6具体为:
42、s6.1,在原待测方法中植入突变,包括条件变异、算术运算符变异、一般表达式变异、语句变异、边界值变异、返回值变异、逻辑操作符变异,形成变异后的待测方法;
43、s6.2,将所有测试方向生成的全部测试用例运行在变异后的待测方法上,如果原来通过的测试用例在变异后的待测方法上执行失败,则说明植入的突变被解决了;该步骤同时需要记录突变的解决情况;
44、s6.3,如果仍存在未解决的突变,则将突变的信息、待测方法的上下文信息动态地渲染进提示模版中生成一个为了解决该突变的提示,输入大语言模型中,生成新的测试用例,直到该突变被解决或者达到了最大尝试次数。
45、进一步地,s7具体为:
46、s7.1针对所有生成的测试用例的覆盖情况,选择删除体积最大、覆盖情况一致且解决突变一致的测试用例,直到所有的测试用例的覆盖情况、解决突变情况均不一致;
47、s7.2合并所有的测试用例到一个测试套件中,运行该测试套件;如果测试套件未能运行成功,则说明该测试套件中存在有冲突的测试用例,首先尝试加入准备环境和清理环境的步骤,如果未能成功解决该冲突,则尝试删除部分测试用例。
48、根据本说明书的第二方面,提供一种基于对话式大语言模型的高可靠单元测试自动生成装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,用于实现如第一方面所述的基于对话式大语言模型的高可靠单元测试自动生成方法。
49、基于上述技术方案,本发明具有以下有益技术效果:
50、1.本发明提出了一个高可靠性的基于对话式大语言模型的单元测试自动生成方法,能够自动对项目解析、进行代码可达分析、提取相关信息、测试目的划分、动态生成上下文,自动生成并修复初始测试用例,随后对初始测试用例的测试输入数据进行搜索,使用变异测试来保证生成的测试用例的质量,最后最小化测试用例,最终输出正确、可靠、覆盖率高、体积小的测试套件。
51、2.在实验中,本发明在不同的项目上(包括大小、领域和版本等不同特点)都表现出了稳定的效果。相较于传统方法,无论在分支覆盖率还是行覆盖率上,都展现出了显著的优势。同样,在与基于预训练模型的方法比较时,本发明在行覆盖率和待测方法的覆盖率上均优于该类方法。最后,在和已有的基于对话式大语言模型的方法对比时,无论是在测试意图、测试输入数据的完整性、测试断言的质量,还是在测试用例的重复度上,本发明都表现出了显著的优势。
52、3.实验证明,本发明生成的测试用例在可读性、可理解性、可维护性、测试输入数据完整性、断言质量、体积上具有显著优势。
- 还没有人留言评论。精彩留言会获得点赞!