卷积神经网络运算装置、方法及移动终端与流程
本技术涉及计算机,尤其涉及一种卷积神经网络运算装置、方法及移动终端。
背景技术:
1、随着人工智能技术的发展,卷积神经网络模型的应用也越来越广泛。
2、卷积神经网络模型中通常包括多个处理层,例如卷积层、池化层、全连接层等等,不同的层均需要进行相应的计算处理。卷积神经网络模型的各层的参数较多,运算量大,涉及大量的数据传输以及数据的运算,导致卷积神经网络模型在运算过程中,需要消耗较长的时间,运算的效率较低。
3、因此亟需提供一种卷积神经网络运算方案,以减小卷积神经网络模型运算消耗的时间,提高运算的效率。
技术实现思路
1、本技术提供一种卷积神经网络运算装置、方法及移动终端,以减小卷积神经网络模型运算消耗的时间,提高运算的效率。
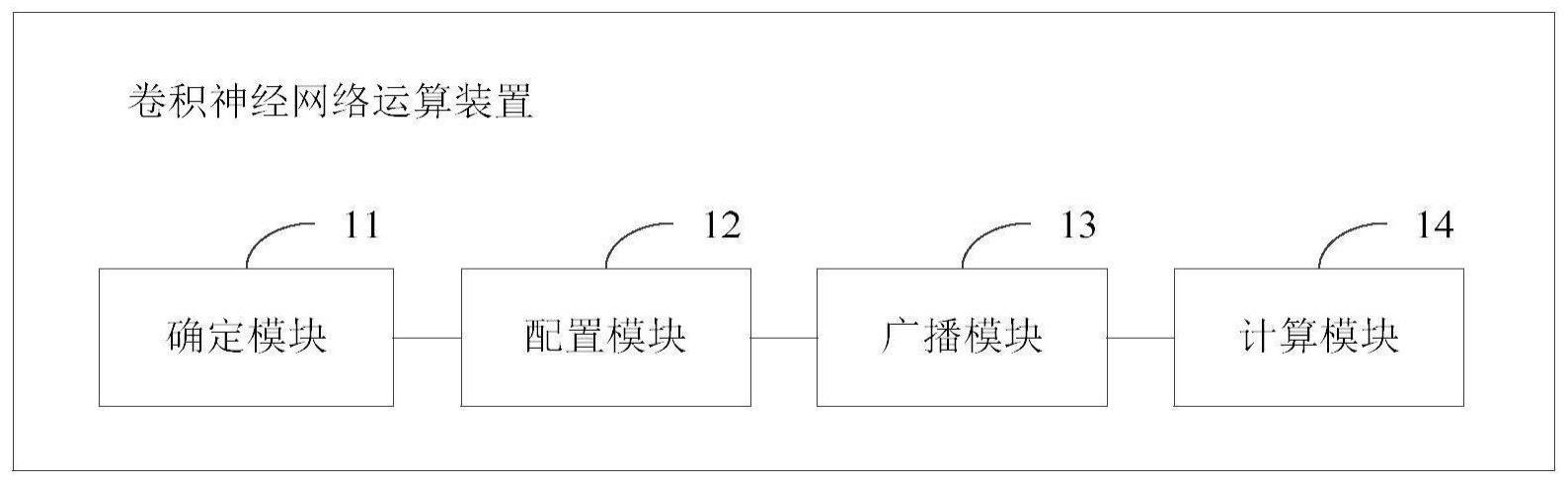
2、第一方面,本技术提供一种卷积神经网络运算装置,所述卷积神经网络运算装置中被配置了多个可重构计算单元,所述装置包括:
3、确定模块,用于根据待处理的卷积神经网络模型的结构,从所述多个可重构计算单元中,确定多个目标可重构计算单元;
4、配置模块,用于根据所述卷积神经网络模型的结构,配置所述多个目标可重构计算单元各自的计算类型、以及所述多个目标可重构计算单元之间的连接关系,所述计算类型为比较处理、加法处理、乘法处理、累加处理、乘累加处理中的任意一项;
5、广播模块,用于根据所述多个目标可重构计算单元各自的计算类型,将所述卷积神经网络模型中的数据分别广播至对应的目标可重构计算单元进行计算,得到所述多个目标可重构计算单元各自的计算结果,其中,所述卷积神经网络模型中存在至少一个数据被广播至至少两个目标可重构计算单元;
6、计算模块,用于根据所述多个目标可重构计算单元之间的连接关系,对所述多个目标可重构计算单元各自的计算结果进行处理,得到所述卷积神经网络模型的模型输出结果。
7、在一种可能的实施方式中,所述可重构计算单元包括输入接口、输出接口以及计算子单元,其中:
8、所述输入接口包括第一输入接口、第二输入接口、第三输入接口、第四输入接口、第五输入接口和第六输入接口;
9、所述输出接口包括第一输出接口和第二输出接口;
10、所述计算子单元包括比较器、乘法器、加法器、第一选通器、第二选通器以及第三选通器;
11、所述比较器的输入端连接所述第一输入接口和所述第二输入接口,所述比较器的输出端连接所述第一输出接口;
12、所述乘法器的输入端连接所述第三输入接口和所述第四输入接口,所述乘法器的输出端连接所述第一选通器的输入端和所述第一输出接口;
13、所述第一选通器的输入端还连接所述第五输入接口,所述第二选通器的输入端连接所述第六输入接口,所述第一选通器的输出端和所述第二选通器的输出端均连接所述加法器的输入端;
14、所述加法器的输出端连接所述第三选通器的输入端;
15、所述第三选通器的输出端连接所述第二选通器的输入端和所述第二输出接口。
16、在一种可能的实施方式中,所述计算类型为比较处理;其中:
17、所述第一输入接口,用于获取第一输入数据,并将所述第一输入数据发送至所述比较器;
18、所述第二输入接口,用于获取第二输入数据,并将所述第二输入数据发送至所述比较器;
19、所述比较器,用于对所述第一输入数据和所述第二输入数据进行比较处理,确定所述第一输入数据和所述第二输入数据中的较大值;
20、所述第一输出接口,用于输出所述第一输入数据和所述第二输入数据中的较大值。
21、在一种可能的实施方式中,所述计算类型为乘法处理或乘累加处理;其中:
22、所述第三输入接口,用于获取第三输入数据,并将所述第三输入数据发送至所述乘法器;
23、所述第四输入接口,用于获取第四输入数据,并将所述第四输入数据发送至所述乘法器;
24、所述乘法器,用于对所述第三输入数据和所述第四输入数据进行乘法处理,得到所述第三输入数据和所述第四输入数据的乘积。
25、在一种可能的实施方式中,
26、若所述计算类型为所述乘法处理,则:
27、所述乘法器,还用于将所述乘积发送给所述第一输出接口;
28、所述第一输出接口,用于输出所述乘积;
29、若所述计算类型为所述乘累加处理,则:
30、所述乘法器,还用于将所述乘积发送给所述第一选通器;
31、所述第一选通器,用于选择将所述乘积发送至所述加法器;
32、所述第三选通器,用于选择将所述第三选通器选择输出的第一输出数据输入至所述第二选通器;
33、所述第二选通器,用于选择将所述第一输出数据发送至所述加法器;
34、所述加法器,用于将所述第一输出数据和所述乘积进行加法处理,得到所述第一输出数据和所述乘积的和;
35、所述第二输出接口,用于输出所述第一输出数据和所述乘积的和。
36、在一种可能的实施方式中,所述计算类型为加法处理;其中:
37、所述第五输入接口,用于获取第五输入数据,并将所述第五输入数据发送至所述第一选通器;
38、所述第一选通器,用于选择将所述第五输入数据发送至所述加法器;
39、所述第六输入接口,用于获取第六输入数值,并将所述第六输入数值发送至所述第二选通器;
40、所述第二选通器,用于选择将所述第六输入数据发送至所述加法器;
41、所述加法器,用于对所述第五输入数据和所述第六输入数据进行加法处理,得到所述第五输入数据和所述第六输入数据的和;
42、所述第二输出接口,用于输出所述第五输入数据和所述第六输入数据的和。
43、在一种可能的实施方式中,所述计算类型为累加处理;其中:
44、所述第五输入接口,用于获取第七输入数据,并将所述第七输入数据发送至所述第一选通器;
45、所述第一选通器,用于选择将所述第七输入数据发送至所述加法器;
46、所述第三选通器,用于选择将所述第三选通器输出的第二输出数值输入至所述第二选通器;
47、所述第二选通器,用于选择将所述第二输出数值发送至所述加法器;
48、所述加法器,用于将所述第二输出数值和所述第七输入数据进行累加,得到所述第二输出数值和所述第七输入数据的累加值;
49、所述第二输出接口,用于输出所述第二输出数值和所述第七输入数据的累加值。
50、在一种可能的实施方式中,所述卷积神经网络模型的结构包括卷积层;所述确定模块具体用于:
51、根据所述卷积层的卷积核矩阵的维度,从所述多个可重构计算单元中,确定n3个第一目标可重构计算单元和n个第二目标可重构计算单元,所述n为所述卷积核矩阵的维度,n3个第一目标可重构计算单元按n2行、n列排列,n为正整数;
52、所述配置模块具体用于:
53、根据所述卷积核矩阵,配置所述n3个第一目标可重构计算单元的计算类型均为乘法处理,配置所述n个第二目标可重构计算单元的计算类型为所述累加处理;
54、根据所述卷积核矩阵,配置任意第i列的第一目标可重构计算单元均与第i个第二目标可重构计算单元连接。
55、第二方面,本技术提供一种卷积神经网络运算方法,应用于卷积神经网络运算装置,所述卷积神经网络运算装置中被配置了多个可重构计算单元,所述方法包括:
56、根据待处理的卷积神经网络模型的结构,从所述多个可重构计算单元中,确定多个目标可重构计算单元;
57、根据所述卷积神经网络模型的结构,配置所述多个目标可重构计算单元各自的计算类型、以及所述多个目标可重构计算单元之间的连接关系,所述计算类型为比较处理、加法处理、乘法处理、累加处理、乘累加处理中的任意一项;
58、根据所述多个目标可重构计算单元各自的计算类型,将所述卷积神经网络模型中的数据分别广播至对应的目标可重构计算单元进行计算,得到所述多个目标可重构计算单元各自的计算结果,其中,所述卷积神经网络模型中存在至少一个数据被广播至至少两个目标可重构计算单元;
59、根据所述多个目标可重构计算单元之间的连接关系,对所述多个目标可重构计算单元各自的计算结果进行处理,得到所述卷积神经网络模型的模型输出结果。
60、在一种可能的实施方式中,所述可重构计算单元包括输入接口、输出接口以及计算子单元,其中:
61、所述输入接口包括第一输入接口、第二输入接口、第三输入接口、第四输入接口、第五输入接口和第六输入接口;
62、所述输出接口包括第一输出接口和第二输出接口;
63、所述计算子单元包括比较器、乘法器、加法器、第一选通器、第二选通器以及第三选通器;
64、所述比较器的输入端连接所述第一输入接口和所述第二输入接口,所述比较器的输出端连接所述第一输出接口;
65、所述乘法器的输入端连接所述第三输入接口和所述第四输入接口,所述乘法器的输出端连接所述第一选通器的输入端和所述第一输出接口;
66、所述第一选通器的输入端还连接所述第五输入接口,所述第二选通器的输入端连接所述第六输入接口,所述第一选通器的输出端和所述第二选通器的输出端均连接所述加法器的输入端;
67、所述加法器的输出端连接所述第三选通器的输入端;
68、所述第三选通器的输出端连接所述第二选通器的输入端和所述第二输出接口。
69、在一种可能的实施方式中,所述计算类型为比较处理;其中:
70、所述第一输入接口,用于获取第一输入数据,并将所述第一输入数据发送至所述比较器;
71、所述第二输入接口,用于获取第二输入数据,并将所述第二输入数据发送至所述比较器;
72、所述比较器,用于对所述第一输入数据和所述第二输入数据进行比较处理,确定所述第一输入数据和所述第二输入数据中的较大值;
73、所述第一输出接口,用于输出所述第一输入数据和所述第二输入数据中的较大值。
74、在一种可能的实施方式中,所述计算类型为乘法处理或乘累加处理;其中:
75、所述第三输入接口,用于获取第三输入数据,并将所述第三输入数据发送至所述乘法器;
76、所述第四输入接口,用于获取第四输入数据,并将所述第四输入数据发送至所述乘法器;
77、所述乘法器,用于对所述第三输入数据和所述第四输入数据进行乘法处理,得到所述第三输入数据和所述第四输入数据的乘积。
78、在一种可能的实施方式中,
79、若所述计算类型为所述乘法处理,则:
80、所述乘法器,还用于将所述乘积发送给所述第一输出接口;
81、所述第一输出接口,用于输出所述乘积;
82、若所述计算类型为所述乘累加处理,则:
83、所述乘法器,还用于将所述乘积发送给所述第一选通器;
84、所述第一选通器,用于选择将所述乘积发送至所述加法器;
85、所述第三选通器,用于选择将所述第三选通器选择输出的第一输出数据输入至所述第二选通器;
86、所述第二选通器,用于选择将所述第一输出数据发送至所述加法器;
87、所述加法器,用于将所述第一输出数据和所述乘积进行加法处理,得到所述第一输出数据和所述乘积的和;
88、所述第二输出接口,用于输出所述第一输出数据和所述乘积的和。
89、在一种可能的实施方式中,所述计算类型为加法处理;其中:
90、所述第五输入接口,用于获取第五输入数据,并将所述第五输入数据发送至所述第一选通器;
91、所述第一选通器,用于选择将所述第五输入数据发送至所述加法器;
92、所述第六输入接口,用于获取第六输入数值,并将所述第六输入数值发送至所述第二选通器;
93、所述第二选通器,用于选择将所述第六输入数据发送至所述加法器;
94、所述加法器,用于对所述第五输入数据和所述第六输入数据进行加法处理,得到所述第五输入数据和所述第六输入数据的和;
95、所述第二输出接口,用于输出所述第五输入数据和所述第六输入数据的和。
96、在一种可能的实施方式中,所述计算类型为累加处理;其中:
97、所述第五输入接口,用于获取第七输入数据,并将所述第七输入数据发送至所述第一选通器;
98、所述第一选通器,用于选择将所述第七输入数据发送至所述加法器;
99、所述第三选通器,用于选择将所述第三选通器输出的第二输出数值输入至所述第二选通器;
100、所述第二选通器,用于选择将所述第二输出数值发送至所述加法器;
101、所述加法器,用于将所述第二输出数值和所述第七输入数据进行累加,得到所述第二输出数值和所述第七输入数据的累加值;
102、所述第二输出接口,用于输出所述第二输出数值和所述第七输入数据的累加值。
103、在一种可能的实施方式中,所述卷积神经网络模型的结构包括卷积层;所述根据待处理的卷积神经网络模型的结构,从所述多个可重构计算单元中,确定多个目标可重构计算单元,包括:
104、根据所述卷积层的卷积核矩阵的维度,从所述多个可重构计算单元中,确定n3个第一目标可重构计算单元和n个第二目标可重构计算单元,所述n为所述卷积核矩阵的维度,n3个第一目标可重构计算单元按n2行、n列排列,n为正整数;
105、所述根据所述卷积神经网络模型的结构,配置所述多个目标可重构计算单元各自的计算类型、以及所述多个目标可重构计算单元之间的连接关系,包括:
106、根据所述卷积核矩阵,配置所述n3个第一目标可重构计算单元的计算类型均为乘法处理,配置所述n个第二目标可重构计算单元的计算类型为所述累加处理;
107、根据所述卷积核矩阵,配置任意第i列的第一目标可重构计算单元均与第i个第二目标可重构计算单元连接。
108、第三方面,本技术提供一种移动终端,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现如第二方面任一项所述的卷积神经网络运算方法。
109、第四方面,本技术提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如第二方面任一项所述的卷积神经网络运算方法。
110、第五方面,本技术提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如第二方面任一项所述的卷积神经网络运算方法。
111、本技术实施例提供的卷积神经网络运算装置、方法及移动终端,卷积神经网络运算装置中被配置了多个可重构计算单元,卷积神经网络运算装置根据待处理的卷积神经网络模型的结构,从多个可重构计算单元中,确定多个目标可重构计算单元,然后根据卷积神经网络模型的结构,配置多个目标可重构计算单元各自的计算类型、以及多个目标可重构计算单元之间的连接关系;根据多个目标可重构计算单元各自的计算类型,将卷积神经网络模型中的数据分别广播至对应的目标可重构计算单元进行计算,得到多个目标可重构计算单元各自的计算结果,其中,卷积神经网络模型中存在至少一个数据被广播至至少两个目标可重构计算单元;根据多个目标可重构计算单元之间的连接关系,对多个目标可重构计算单元各自的计算结果进行处理,得到卷积神经网络模型的模型输出结果。由于可重构计算单元可以被配置为不同的计算类型,包括比较处理、加法处理、乘法处理、累加处理、乘累加处理中的任意一项,因而能够保证卷积神经网络模型的运行便于被移植到移动终端侧进行处理,而在卷积神经网络模型的运算过程中,通过广播的方式来进行数据的传输,存在至少一个数据被广播至至少两个目标可重构计算单元,这种广播的数据传输的方式能够减小数据在不同单元中传递所消耗的时间,大大提高数据传输速率和运算的并行度,减小了卷积神经网络模型运算消耗的时间,提高了运算的效率,一定程度减少了时钟浪费。
- 还没有人留言评论。精彩留言会获得点赞!