一种基于空间注意力机制的多模态图像分割模型和方法
本发明属于医疗图像处理,具体涉及一种基于空间注意力机制的多模态图像分割模型和方法。
背景技术:
1、脑肿瘤是指在脑组织中形成的异常生长的肿瘤,根据其位置和大小,可能会对脑部功能产生不同程度的影响。其中,神经胶质瘤是一种起源于脑组织神经胶质细胞的肿瘤,经长期研究分析发现,通常为恶性。在诊断过程中,需要对图像进行分割,提取特征区域以辅助诊断。然而,手动分割需要大量的时间和人力,并且容易出现主观误差。因此,自动分割方法成为了一种更加高效和准确的选择。
2、但是,单模态自动分割方法在胶质瘤分割中仍然存在一些挑战。首先,胶质瘤的形态和大小变化很大,使得单一模态的影像数据难以捕捉到所有的信息。其次,胶质瘤病灶边缘模糊和病灶内部异质性会导致分割结果不准确。因此,多模态自动分割方法成为了一种更加有效的选择,它可以结合多种影像数据,提高分割的准确性和稳定性。
3、现有的多模态分割胶质瘤的方法包括基于多任务学习和生成对抗网络。这些方法都使用多个模态的影像数据进行特征提取和融合,然后使用分类器进行分割。然而,这些方法中存在一个共同的问题,即模型中可能存在特征缺失的情况。由于不同模态的影像数据具有不同的特征,这种情况下,模型可能会将正常脑组织或其他病变区域错误地分割为胶质瘤,或者将胶质瘤错误地分割为正常脑组织或其他病变区域。这将导致严重的诊断错误和治疗错误,对患者的健康造成严重影响。因此,如何解决模型中的特征缺失问题是多模态分割胶质瘤研究中的一个重要问题。
4、为了解决这个问题,研究人员提出了一些方法。其中一种方法是使用注意力机制,它可以自适应地选择不同模态的特征,以提高模型的准确性。另一种方法是使用增强学习,它可以让模型自主地选择最有用的模态,以提高分割的准确性。另一种解决特征缺失问题的方法是通过迁移学习,它可以帮助填补从类似任务中学到的知识的空白。此外,一些研究人员还提出了使用深度生成模型来生成缺失的特征,以提高模型的预测能力,确保模型更流畅地处理某些特征。这些方法都可以在一定程度上解决特征缺失的问题,但仍需要进一步的研究和改进。
5、有鉴于此,本发明提出一种新的多模态图像分割方法,是一种基于空间注意力机制的多模态图像分割模型和方法,可以提高模型的性能,使模型聚焦更多关于重要区域,从而确保模型在分割过程中不会丢弃重要特征。
技术实现思路
1、本发明的目的在于提供一种基于空间注意力机制的多模态图像分割模型,解决了模型中的特征缺失问题,使模型聚焦更多关于重要区域,可以将正常脑组织或其他病变区域正确地分割,避免诊断错误和治疗错误。
2、为了实现上述目的,所采用的技术方案为:
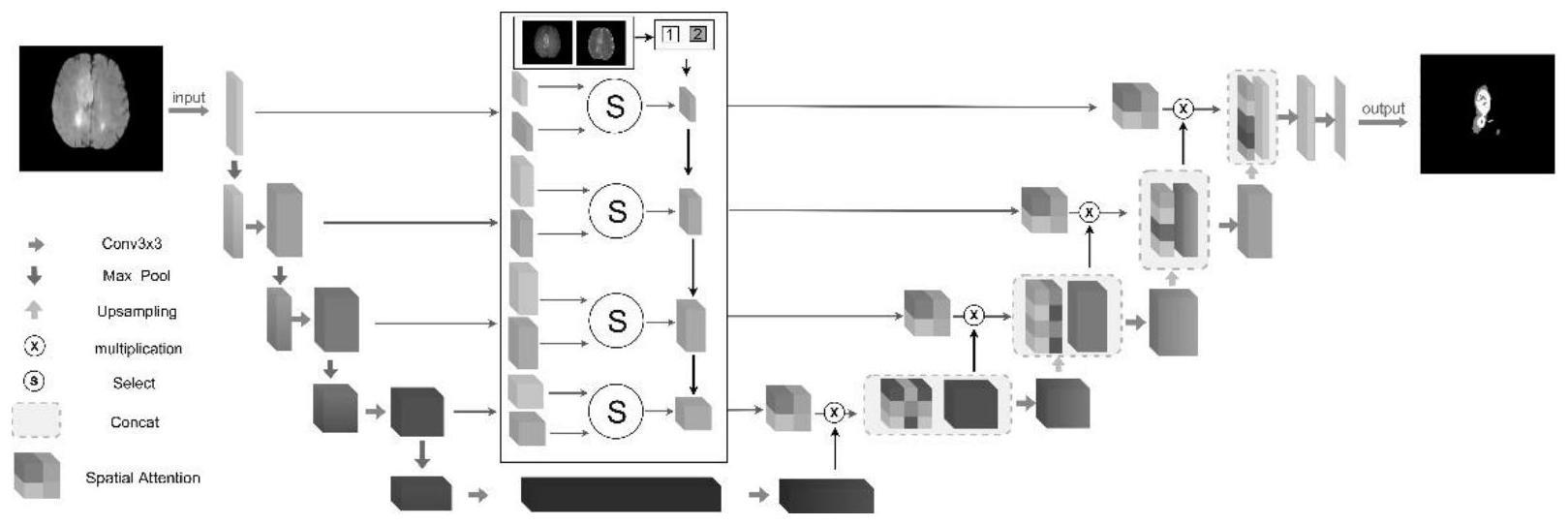
3、一种基于空间注意力机制的多模态图像分割模型,所述的多模态图像分割模型包括:编码器模块、解码器模块、跳跃连接模块、空间注意力模块和特征选择模块;
4、其中,所述的编码器模块对输入数据进行提取特征;
5、所述的特征选择模块在解码时,选择信息丰富的特征,补充输入数据中的缺失特征;
6、所述的空间注意力模块和跳跃连接模块分别处理数据流,减少数据特征缺失,并进一步提高特征区域的权重;
7、所述的解码器模块用于恢复图像。
8、进一步的,所述的特征选择模块采用欧几里得距离进行多模态特征选择,其公式如下:
9、
10、其中,xi和yi分别表示分割结果和标签在第i个像素位置的像素值,n表示图像中像素的总数。
11、进一步的,所述的空间注意力模块加强关注权重的过程为:先对图像进行池化,再对结果进行卷积和sigmoid计算,以获得用于对所选特征图进行加权的权重矩阵。
12、再进一步的,所述的对图像进行池化的过程为:对输入的特征图x进行平均池化和最大池化,得到两个特征图xavg和xmax;
13、所述的两个特征图xavg和xmax的公式如下:
14、
15、
16、其中,h、w、c分别表示为高度、宽度和通道数。
17、再进一步的,所述的对图像进行池化之后的过程为:
18、a:将所述的两个特征图xavg和xmax进行拼接,得到特征图xcat;再对所述的xcat进行卷积操作,得到特征图xconv;
19、所述的特征图xconv的公式如下:
20、xconv(i,j,k)=σ(w2δ(w1xcat(i,j,:)));
21、其中,w1∈r1×1×2c×c和w2∈r1×1×c×c分别表示两个卷积层的权重,δ表示卷积操作,σ表示为sigmod函数;
22、b:获得权重矩阵a,其公式如下:
23、a(i,j,k)=xconv(i,j,k);
24、c:所述的权重矩阵a与输入的特征图x相乘,就得到了经过空间注意力加强的特征图xatt,其公式如下:
25、xatt(i,j,k)=a(i,j,k)×x(i,j,k)。
26、进一步的,所述的多模态图像分割模型还包括损失函数模块,由内容损失和边界损失组成。
27、再进一步的,所述的损失函数模块使用二元交叉熵损失函数来计算模型预测结果与真实标签之间的差异,其公式如下:
28、l=αlcontent+βlboundary;
29、其中,lcontent表示为内容损失,lboundary表示边界损失,α和β分别表示内容损失和边界损失的权重。
30、再进一步的,所述的内容损失和边界损失计算公式如下所示:
31、
32、
33、其中,n表示样本数量,yij表示真实标签中第i个样本的第j个通道的值,表示模型预测结果中第i个样本的第j个通道的值。
34、本发明还有一个目的在于提供一种基于空间注意力机制的多模态图像分割方法,采用上述的模型进行图像分割,确保模型在分割过程中不会丢弃重要特征,从而具有更高的分割准确性。
35、与现有技术相比,本发明的有益效果在于:
36、本发明所述的一种基于空间注意力机制的多模态图像分割模型和方法,提出了一种分割模型sel-net,它可以自适应地选择最优的特征图片进行拼接,同时利用空间注意力机制加强关注权重,进一步提高模型的性能,使模型聚焦更多关于重要区域,从而确保模型在分割过程中不会丢弃重要特征。从而具有以下优势:
37、(1)本发明的技术方案中,采用了‘自适应选择’的多模态分割模型sel-net。sel-net可以自适应地选择不同的特征,以适应不同的数据集和任务需求,从而具有更广泛的适用性和灵活性。
38、(2)本发明的技术方案中,采用了欧几里得距离作为选择最具代表性特征的指标。可以更加客观地评估不同特征组合的相似度和差异性,从而提高了特征选择的准确性和可靠性。
39、(3)本发明的技术方案中,引用了内容与边界的加权损失函数,可以更好地平衡分割结果的内容和边界信息,从而避免了过度关注某些局部细节或者忽略了整体结构的问题。
- 还没有人留言评论。精彩留言会获得点赞!