基于多尺度Transformer学习丰富视觉特征的人体姿态估计方法及系统
本发明属于人工智能及计算机视觉,尤其涉及一种基于多尺度transformer学习丰富视觉特征的人体姿态估计方法及系统。
背景技术:
1、人体姿态估计是计算机视觉领域的重要组成之一,其目的是在给定的二维图形中预测出人体的解剖学关键点,随着深度卷积神经神经网络的发展,姿态估计模型的性能取得了显著的进步,逐渐应用到更加复杂的场景,如运动分析、人机交互等领域。
2、目前,主流的姿态估计模型大多是以cnn为编码器来提取纹理特征,接着将特征图解码为较高分辨率的尺寸来通过热图法或直接回归关键点的方法来预测出最后的结果,这样的范式已经为本领域所熟知,在绝大部分姿态估计模型中得到了体现,如在[newell,alejandro,kaiyu yang,and jia deng.
3、"stacked hourglass networks for human pose estimation."computervision–eccv 2016:14th european conference,amsterdam,the netherlands,october11-14,2016,proceedings,part viii 14.springer international publishing,2016]中网络通过堆叠若干个hourglass模块,每个模块通过对称的上下采样过程并结合中继监督来生成高分辨率的特征图。而在[sun,ke,et al."deep high-resolution representationlearning for human pose estimation."proceedings of the ieee/cvf conference oncomputer vision and pattern recognition.2019]中对不同分辨率的特征映射进行并联,并始终保持了最高分辨率的分支。然而由于卷积核特性的影响,使的cnn具有局部卷积性,在有限的感受野中只能提取局部信息,不能很好的捕获全局依赖关系,同时cnn对于图像的纹理特征提取能力很强,但是会缺乏对于空间特征的学习能力,导致网络不能充分的学习到图片中包含的信息,造成在一些复杂场景中不能准确的定位出关键点,上述问题都极大了限制了cnn-base模型的上限。
4、近年来,[vaswani,ashish,et al."attention is all you need."advances inneural information processing systems30(2017)]在自然语言处理处理领域大放异彩,不断地刷新着各种榜单,由于transformer是一种sequence to sequence模型,因此网络对于序列之间的依赖性有着很强的建模能力,进而在视觉中transformer可以很好的捕捉图像的空间特征,在[dosovitskiy,alexey,et al."an image is worth 16x16 words:transformers for image recognition at scale."arxiv preprint arxiv:2010.11929(2020)]中首次提出将transformer引入到视觉领域,其通过将图片切分为较小的patch,并将patch展平为序列送入到transformer中训练,这种简单而有效的方法很快引起了众多研究者的关注,但是由于图像分辨率较高使得pure transformer方法需要很大的计算代价,于是cnn+transformer类型的网络逐渐兴起,其中最具代表性的就是[mao,weian,et al."tfpose:direct human pose estimation with transformers."arxiv preprint arxiv:2103.15320(2021)],作者先通过cnn为编码器,将提取出的特征沿着通道维度展平后送入到transformer中,最后通过回归方法预测出关键点。但是,虽然cnn+transformer是一种更优的解决方案,其充分利用了两种网络的优点,在速度和精度之间达到了平衡,但是由于主流的cnn+transformer类型的模型还处于初始阶段,对于两种网络的衔接处,以及最后的回归方式都有很大的探索空间,从而导致两者的性能不能充分的发挥。基于此,本发明提出了一种新的网络mstpose模型框架,将其应用于本领域,以解决上述问题。
技术实现思路
1、为解决现有技术存在的上述问题,本发明公开了一种基于多尺度transformer学习丰富视觉特征的人体姿态估计(mstpose)方法及系统。
2、本发明采取如下技术方案:
3、一种基于多尺度transformer学习丰富视觉特征的人体姿态估计方法,包括如下步骤:
4、(1)获取大量包含有多个人物的图片,并对图片中人物的关节点位置进行标注。
5、(2)将所有图片按比例划分成训练集和测试集;
6、(3)构建mstpose模型框架;
7、(4)将训练集图片及其标签信息输入至mstpose模型框架中进行训练,得到多人姿态估计模型;
8、(5)将测试集图片输入至训练好的多人姿态估计模型中,即可预测出该图片中人物各关节点的位置坐标。
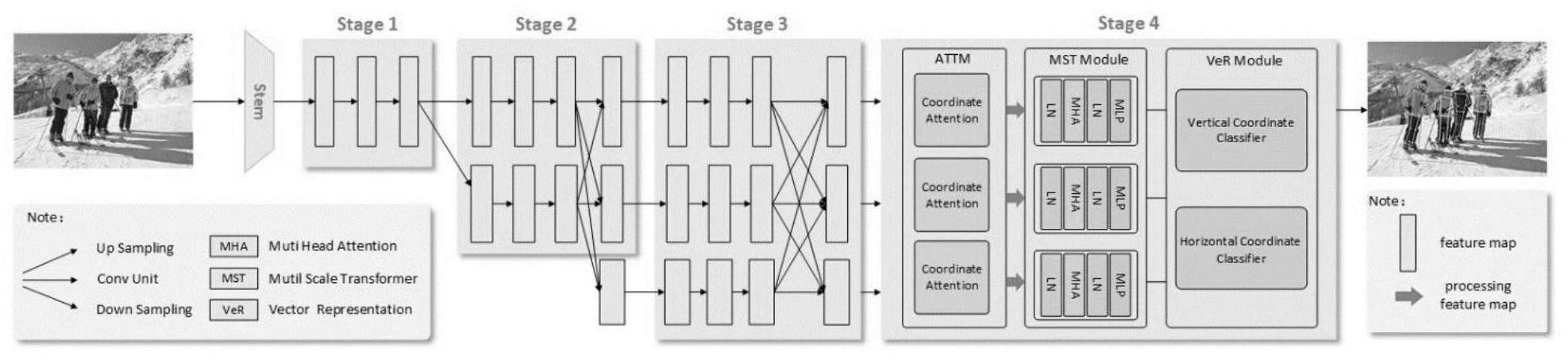
9、优选的,步骤(3)中,mstpose模型框架包括:
10、骨干网络:用于对输入的图片进行特征提取,输出三组特征图。
11、att模块:由三个并联的坐标注意力机制组成,目的是为了增强三个分支特征图的感知能力,生成位置敏感型的特征映射。
12、mst模块:由三个并联的transformer组成,其目的是为了充分的学习到特征间的空间依赖。
13、ver模块:对mst模块输出的一维序列进行处理,最后解码出所需要预测出的关键点。
14、优选的,所述的骨干网络只采用了hrnetw48四个阶段中的前三个阶段,并命名为hrnetw48-s,输入图片经过多层卷积神经网络特征提取后,输出三组特征图。
15、优选的,所述的att模块(attm)为三个并联结构的坐标注意力机制。对输入的特征图首先通过两个一维池化操作,分别沿着垂直方向和水平方向将输入的特征图聚合为两个单独的方向感知特征映射。这两个具有嵌入方向特定信息的特征映射随后分别编码为两个注意映射,每个注意映射捕获输入特征图沿着一个空间方向的远距离依赖关系。然后通过乘法将两个注意力映射引用于输入的特征映射,以此来获得方向感知和位置敏感型的特征图,有助于网络更准确的定位和感知感兴趣的对象。
16、更具体来说,通道注意力通常利用全局池来编码全局空间信息,将全局信息压缩为标量,这使得很难保存重要的空间细节。因此,首先对输入的特征图进行两次一维池化运算,公式如下:
17、
18、
19、其中,h,w为输入特征图的高和宽,为池化运算后垂直方向的输出,为池化运算后水平方向的输出,xc为输入的特征图,i表示输入特征的宽度方向上的索引,j表示输入特征的高度方向上的索引,h表示在水平方向上聚合特征后的输出的高度方向上的索引,w表示在垂直方向上聚合特征后的输出的宽度方向上的索引。
20、其中,特征图沿着垂直方向和水平方向分别聚合,从而产生两个不同的方向感知特征图。连接上述输出,并使用1x1卷积、批量归一化和非线性激活进行特征转换。
21、f=δ(f1([zh,zw]))
22、其中[.,.]代表了沿着空间维度进行拼接,δ表示非线性激活函数,f表示中间特征图,zh表示沿水平方向聚合的特征,zw表示沿垂直方向聚合的特征。
23、然后,使用额外的两个1x1卷积和sigmoid函数将f划分为两个独立的特征进行特征变换,确保其维数与输入大小的维数匹配。
24、gh=σ(fh(fh))
25、gw=σ(fw(fw))
26、其中,σ为激活函数。gh表示沿垂直方向的注意力权重,gw表示沿水平方向的注意力权重,fh表示沿水平方向的特征,fw表示沿垂直方向的特征,fh表示将fh进行1×1卷积变换的权重矩阵,fw表示将fw进行1×1卷积变换的权重矩阵。
27、每个注意力图捕捉沿着输入特征图的空间方向的长程依赖关系。然后通过乘法将注意力图应用于输入特征图,从而产生方向感知和位置敏感的特征图。
28、
29、yc(i,j)表示输出特征图y中位置(i,j)处的像素值;
30、xc(i,j)表示输入特征图x中位置(i,j)处的像素值;
31、表示沿水平方向的注意力权重;
32、表示沿垂直方向的注意力权重。
33、优选的,所述的mst模块由三个并联结构的transformer组成,将attm模块的输出送入到mst module(mst模块)中,具体来说,由于transformer是序列型网络,因此需要先将输入特征图映射为一维序列,由于视觉特征包含了纹理特征和空间特征,为了让网络能充分的捕捉到视觉信息,对输入特征图分别从空间维度以及通道维度进行展开分别生成channel tokens(通道令牌)与spatial tokens(空间令牌),与此同时mstpose模型框架会随机初始化生成可学习的关键点向量keypoints tokens(关键点令牌)。
34、接着对channel tokens和spatial tokens进行位置编码,具体来说,将每个位置记为pei,并对每个序列进行位置编码{channel tokens,
35、其中xc,1,j表示通道令牌在第一个分支上的第j个特征图,xs,1,j表示空间令牌在第一个分支的第j个特征图,同理,2,3,则表示第二个分支以及第三个分支。编码完后,将三种token进行拼接共同送入到transformer中进行特征学习。
36、优选的,所述的ver模块采用一维向量回归法,对于transformer输出的一维序列,直接对其进行处理,以最大程度的保留其细粒度信息。具体来说,首先对三个分支输出的一维序列进行特征融合,接着将其分别送入到x和y向量分类器中,生成xx,xy序列,由于比例因子k的存在,生成的xx,xy序列的长度也将会大于原图的长和宽,从而实现亚像素级别的定位,接着对xx,xy进行解码,从而生成预测出的坐标。
37、本发明还公开了一种基于多尺度transformer学习丰富视觉特征的人体姿态估计系统,用于执行上述方法,其包括如下模块:
38、图片获取及标注模块:获取多张包含人物的图片,并对图片中人物的关节点位置进行标注;
39、图片分类模块:将所有图片按比例划分成训练集和测试集;
40、mstpose模型框架构建模块:构建mstpose模型框架;
41、训练模块:将训练集图片及其标签信息输入至mst pose模型框架中进行训练,得到多人姿态估计模型;
42、估计模块:将测试集图片输入至训练好的多人姿态估计模型中,预测出该图片中人物各关节点的位置坐标。
43、综上,本发明公开了一种基于多尺度transformer学习丰富视觉特征的人体姿态估计方法及系统,本发明先通过高分辨cnn网络来提取图像的纹理信息,对于骨干网络输出的三个不同尺度分支的特征图,首先对每个分支输出的特征图做坐标注意力操作,接着将特征图分别从通道维度和空间维度进行展开处理,并结合上随机初始化生成的keypointtoken,将其共同送入到并联结构的transformer中以此来学习特征之间的空间依赖性,由于transformer输出为一维序列特征,因此,在网络的最后,本发明摒弃掉主流的二维热图法,而是采用一维的坐标向量回归法来预测关键点,准确率高。
- 还没有人留言评论。精彩留言会获得点赞!