一种针对预训练语言模型的跨语言模型迁移方法及系统
本技术涉及模型迁移,特别涉及一种针对预训练语言模型的跨语言模型迁移方法及系统。
背景技术:
1、预训练语言模型(pre-trained language model,prlm)极大地提高了自然语言处理(natural language processing,nlp)任务的性能,并
2、许自然语言处理的发展扩展到更多实际场景。尽管预训练语言模型性能强大且使用方便,但训练预训练语言模型目前需要消耗越来越多的资源和时间。除此之外,目前大多数预训练语言模型使用英文语料进行训练,这阻止了其他不同语言的用户享受大型预训练语言模型的成果。因此,将语言模型的知识从一种语言迁移到另一种语言是一项重要的任务,原因有以下两个。首先,许多语言没有英语用来训练如此庞大和依赖于数据的模型的数据资源,这导致了英语用户和其他语言用户可使用的模型质量上的差异。其次,不同语言之间有许多共同点,为了提高效率,在模型之间迁移知识而不是浪费资源来训练新的模型是更可取的。
3、多语言预训练语言模型(multilingual pre-trained language model,mprlm)旨在利用语言共享的共性,减少所需的语言模型的数量,但其是通过对多种语言进行预训练来实现这一点。这意味着当遇到新的语言时,其需要重新进行预训练,这将导致资源的浪费。这与使用跨语言模型迁移(cross-lingual transferring of language modeling,trelm)使模型适应新的语言不同,因为跨语言模型迁移放弃了大规模的预训练,而是提供了一种更轻量级的方法来传输预训练语言模型。
4、机器翻译自动将一种语言的文本转换为另一种语言的文本,是最常见的跨语言任务,机器翻译模型将由某种语言中的符号序列组成的输入转换为另一种语言中的符号序列,其遵循序列到序列的范式。语言被定义为“一种序列,它是符号的枚举集合,其中允许重复,顺序无关紧要”。从这个定义中可以推导出不同语言序列中的三个重要差异:符号集、符号顺序和序列长度,这也可以被视为机器翻译的三个挑战,同时也是在跨语言迁移预训练语言模型中需要解决的三个关键问题。
5、综上所述,如何实现一种针对预训练语言模型的跨语言模型迁移框架方法成为了一个亟待解决的问题。
技术实现思路
1、针对现有技术中存在的缺陷,本技术的目的在于提供一种针对预训练语言模型的跨语言模型迁移方法及系统,能够高效准确实现跨语言模型迁移。
2、第一方面,提供了一种针对预训练语言模型的跨语言模型迁移方法,包括:
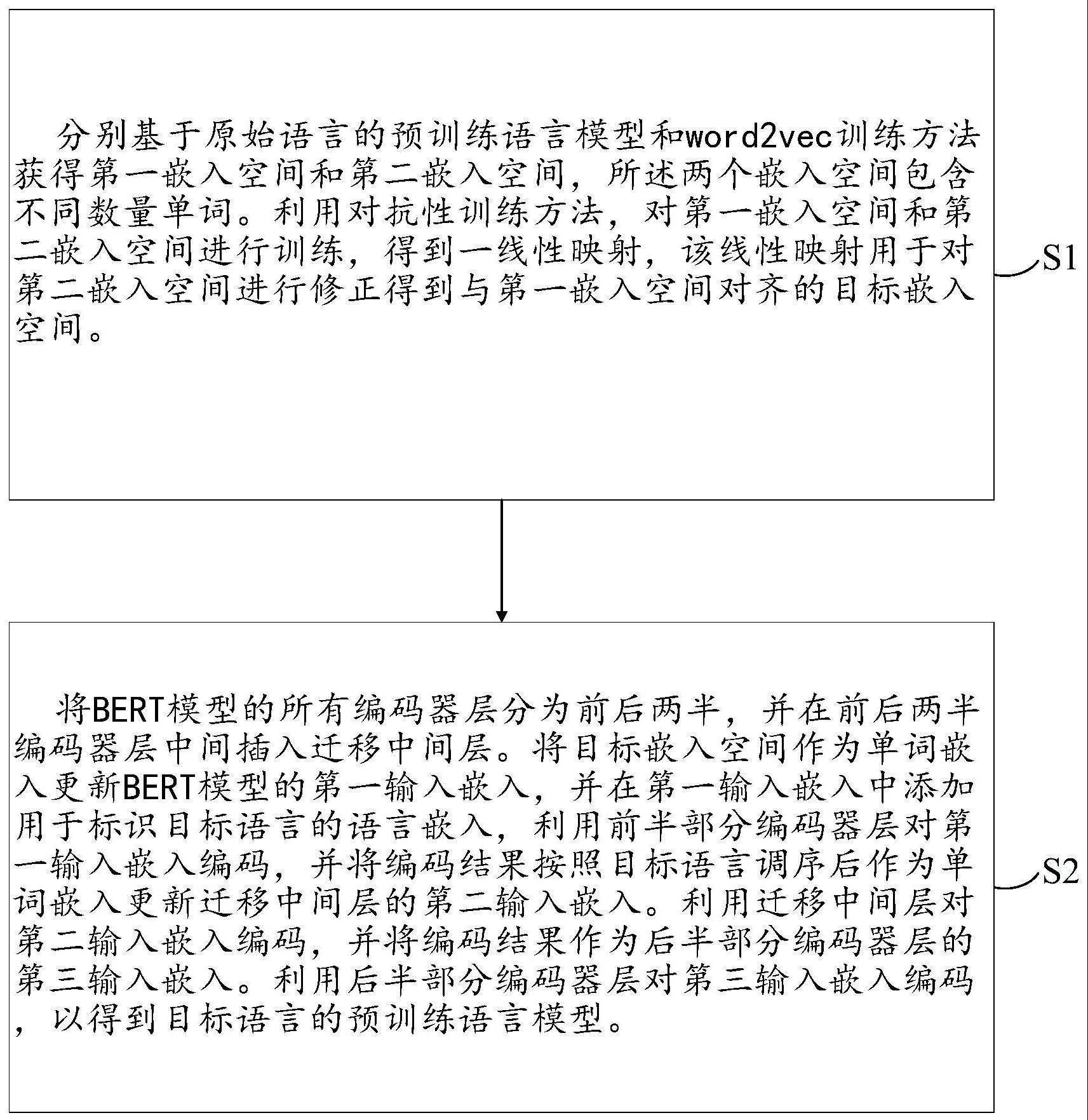
3、分别基于原始语言的预训练语言模型和word2vec训练方法获得第一嵌入空间和第二嵌入空间,所述两个嵌入空间包含不同数量单词;
4、利用对抗性训练方法,对第一嵌入空间和第二嵌入空间进行训练,得到一线性映射,该线性映射用于对第二嵌入空间进行修正得到与第一嵌入空间对齐的目标嵌入空间;
5、将bert模型的所有编码器层分为前后两半,并在前后两半编码器层中间插入迁移中间层;
6、将目标嵌入空间作为单词嵌入更新bert模型的第一输入嵌入,并在第一输入嵌入中添加用于标识目标语言的语言嵌入,利用前半部分编码器层对第一输入嵌入编码,并将编码结果按照目标语言调序后作为单词嵌入更新迁移中间层的第二输入嵌入;
7、利用迁移中间层对第二输入嵌入编码,并将编码结果作为后半部分编码器层的第三输入嵌入;
8、利用后半部分编码器层对第三输入嵌入编码,以得到目标语言的预训练语言模型。
9、一些实施例中,所述第一输入嵌入采用下述公式计算得到:
10、einp=ewrd+eseg+epos+elng
11、其中,
12、einp用于表示第一输入嵌入;
13、ewrd用于表示单词嵌入;
14、eseg用于表示分割嵌入;
15、epos用于表示位置嵌入;
16、elng用于表示语言嵌入。
17、一些实施例中,所述前半部分编码器采用下述公式对所述第一输入嵌入进行编码:
18、hi=transformeri(hi-1)
19、其中,
20、i用于表示编码器层的层数,i为正整数;
21、hi用于表示第i个编码器层的输出;
22、transformeri用于表示第i个编码器层。
23、一些实施例中,所述将编码结果按照目标语言调序,具体包括如下步骤:
24、根据源语言和目标语言的并行语料库得到目标语言的语序信息;
25、根据所述语序信息对编码结果进行调序,以使编码结果的语序符合目标语言的语序。
26、一些实施例中,所述利用后半部分编码器层对第三输入嵌入编码,以得到目标语言的预训练语言模型,具体包括如下步骤:
27、利用后半部分编码器层的编码结果计算bert模型的训练损失,根据该训练损失得到目标语言的预训练语言模型。
28、一种针对预训练语言模型的跨语言模型迁移框架系统,包括:
29、反向对齐模块,其用于分别基于原始语言的预训练语言模型和word2vec训练方法获得第一嵌入空间和第二嵌入空间,所述两个嵌入空间包含不同数量单词;还用于利用对抗性训练方法,对第一嵌入空间和第二嵌入空间进行训练,得到一线性映射,该线性映射用于对第二嵌入空间进行修正得到与第一嵌入空间对齐的目标嵌入空间;
30、模型生成模块,其用于将bert模型的所有编码器层分为前后两半,并在前后两半编码器层中间插入迁移中间层;还用于将目标嵌入空间作为单词嵌入更新bert模型的第一输入嵌入,并在第一输入嵌入中添加用于标识目标语言的语言嵌入,利用前半部分编码器层对第一输入嵌入编码,并将编码结果按照目标语言调序后作为单词嵌入更新迁移中间层的第二输入嵌入;利用迁移中间层对第二输入嵌入编码,并将编码结果作为后半部分编码器层的第三输入嵌入;还用于利用后半部分编码器层对第三输入嵌入编码,以得到目标语言的预训练语言模型。
31、一些实施例中,所述第一输入嵌入采用下述公式计算得到:
32、einp=ewrd+eseg+epos+elng
33、其中,
34、einp用于表示第一输入嵌入;
35、ewrd用于表示单词嵌入;
36、eseg用于表示分割嵌入;
37、epos用于表示位置嵌入;
38、elng用于表示语言嵌入。
39、一些实施例中,所述前半部分编码器采用下述公式对所述第一输入嵌入进行编码:
40、hi=transformeri(hi-1)
41、其中,
42、i用于表示编码器层的层数,i为正整数;
43、hi用于表示第i个编码器层的输出;
44、transformeri用于表示第i个编码器层。
45、一些实施例中,所述将编码结果按照目标语言调序,具体包括如下步骤:
46、根据源语言和目标语言的并行语料库得到目标语言的语序信息;
47、根据所述语序信息对编码结果进行调序,以使编码结果的语序符合目标语言的语序。
48、一些实施例中,所述利用后半部分编码器层对第三输入嵌入编码,以得到目标语言的预训练语言模型,具体包括如下步骤:
49、利用后半部分编码器层的编码结果计算bert模型的训练损失,根据该训练损失得到目标语言的预训练语言模型。
50、本技术提供的技术方案带来的有益效果包括:
51、(1)本发明提出的对抗性嵌入对齐可以充分利用语言之间的共性,利用源语言和目标语言共享的空间结构相似性,对源语言的嵌入空间与目标的嵌入空间进行线性对齐。
52、(2)本发明提出的跨语言建模和迁移中间层使得对现有的预训练语言模型进行尽可能少的更改即可实现跨语言模型迁移。
- 还没有人留言评论。精彩留言会获得点赞!