一种对文言文机器翻译结果自动评估的方法和系统
本发明涉及自然语言处理,具体涉及一种对文言文机器翻译结果自动评估的方法和系统。
背景技术:
1、最早出现的翻译形式是人工翻译,但是由于效率低下、人力成本高昂等缺点,以及计算机的出现和计算机技术的发展,机器翻译逐渐受到人们的青睐。与人工翻译相比,高效且成本低的优势使机器翻译迅速发展。我国古代文献浩如烟海,此外,由于古汉语的语法和词义与现代汉语相比存在着差异,大多数现代人很难对古文进行深入研究。将古文翻译成人们熟知的现代文,更符合大多数人的需求。因此可以使用机器翻译对古文文本进行翻译。
2、然而构建古文机器翻译自动评价方法仍面料诸多问题,目前的机器翻译和自动评价方法主要都是用于双语翻译,关于古汉语到现代汉语的机器翻译和评价方法还比较缺乏。此外,古汉语到现代汉语之间的翻译与其他跨语言的翻译并不完全相同。现代汉语是由古汉语演变而来,二者有着相似性,古汉语中的一些信息可以直接应用于现代汉语之中。但是与现代汉语相比,古文翻译也具有三个鲜明特点:第一是部分概念已经消失的词语需要原样输出,分词的准确性非常重要;第二是古文和现代文的界限具有一定模糊性,但是本发明希望翻译模型能对古文进行充足的翻译,尽量减少原样输出;第三是古文具有高度凝练性,句子中存在大量省略现象,因此参考译文往往会对其进行补全,在对机器机器翻译的结果进行评价时需要考虑对这种补充的背景词信息。
3、为解决以上问题,常见的古文机器翻译自动评价方法包括人工评价和自动评价方法,人工评价可以更准确的反映出机器翻译的质量,但是也存在着诸多缺点:效率低下、耗费大量的时间和经济成本、结果不具有复用性、容易受到主观因素影响等。而自动评价方法只需要基于固定的算法,短时间就能对大量文本翻译结果进行评价并输出结果,能够及时对翻译模型的翻译质量做出评测与反馈,相比而言更具优势。因此,如何结合古文翻译的特点优化自动评价方法,使其更好地应用在任务中,是本领域技术人员亟待解决的技术问题。
技术实现思路
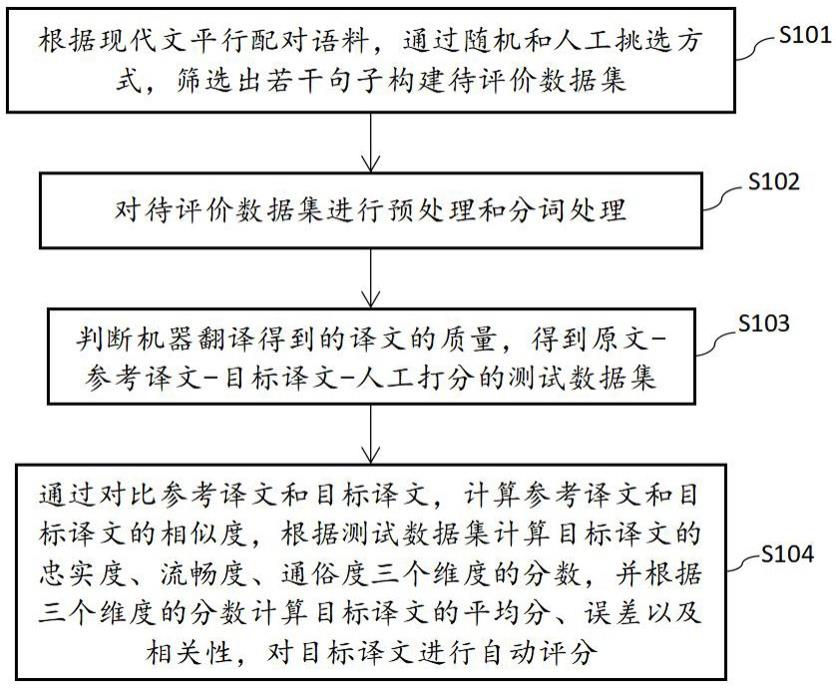
1、为了更好地指导古文机器翻译模型进行迭代优化,以及辅助人们判断当前古文机器翻译模型的质量以及不足。本发明基于忠实度、流畅度和通俗度三个维度,构建古文-参考译文-目标译文-人工评分数据集,并找到了较为合适的评价内部各个维度的方法,以达到直观地评价古文机器翻译结果质量和在迭代中优化古文翻译模型的目的,本技术提供了一种对文言文机器翻译结果自动评估的方法,包括:
2、步骤s101:根据现代文平行配对语料,通过随机和人工挑选方式,筛选出若干句子构建待评价数据集;
3、步骤s102:对所述待评价数据集进行预处理和分词处理;
4、步骤s103:从所述待评价数据集中获取训练语料的原文和参考译文,利用待评估的文言文机器翻译模型对所述原文进行翻译,再将得到的目标译文与参考译文和所述原文对比并进行人工分析,判断所述文言文机器翻译模型翻译的译文质量,并按照原文-参考译文-目标译文-人工打分的方式构建测试数据集;
5、步骤s104:通过对比所述参考译文和目标译文,计算所述参考译文和目标译文的相似度,根据所述测试数据集计算所述目标译文的忠实度、流畅度、通俗度三个维度的分数,并根据所述三个维度的分数计算目标译文的平均分、误差以及相关性,对所述目标译文进行自动评分。
6、在其中一些具体实施例中,步骤s102还包括:
7、统计进行分词处理后的词语,将所述词语按照人工分词、自动分词和按照字粒度进行分词的方式进行划分,并对人工分词、自动分词和按照字粒度进行分词的效果差异进行比较。
8、在其中一些具体实施例中,步骤s103还包括:
9、将所述参考译文中根据篇章信息补齐的成分处理为背景词,不作为评价所述目标译文的参考。
10、在其中一些具体实施例中,步骤s104还包括:
11、步骤s1041:对所述参考译文和目标译文中的词两两计算相似度,设定判断同义词的阈值,将相似度高于或者等于该阈值的词语对视为近义词;再分别计算参考译文的匹配得分scoreref和目标译文的匹配得分scoretar;使用召回率作为是否丢失原文信息的判别依据并计算忠诚度,所述忠诚度的计算公式如下:
12、;
13、;
14、;
15、;
16、其中,simmax为取参考译文或目标译文中按照义原计算的最大相似度,nr为参考译文中词的个数,nt为目标译文中词的个数,scoreref为参考译文对每个词最大的相似度求和后得到的句子相似度,scoretar为目标译文对每个词最大的相似度求和后得到的句子相似度,scorematch为参考译文和目标译文的相似度得分,scorezhong为忠实度得分;
17、步骤s1042:通过最长连续公共子序列来计算文言文的流畅度,所述流畅度的计算公式如下:
18、;
19、;
20、其中,pen为计算流畅度过程中的惩罚项,#chunks in target sentence为根据动态规划计算出最长连续子序列的数量,#words in target sentence为句子中义原的数量,β为惩罚系数,γ为惩罚指数项;
21、步骤s1043:通过如下公式计算所述通俗度:
22、;
23、;
24、;
25、;
26、其中,#insertiontar和#insertionref分别为计算目标译文和参考译文的编辑次数时需要插入词的个数,#substitutiontar和#substitutionref分别为计算目标译文和参考译文的编辑次数时需要替换词的个数,#deletiontar和#deletionref分别为计算目标译文和参考译文的编辑次数时需要删除词的个数,edittar为目标译文到原文的编辑次数,editref为参考译文到原文的编辑次数,scorecon为参考译文编辑次数和目标译文编辑次数的比率,scoretong为通俗度得分。
27、在其中一些具体实施例中,步骤s104还包括:相似度根据如下公式确定:
28、;
29、其中,sims表示所述目标译文和参考译文的相似度得分,s1和s2分别表示各自待评价的两个概念,structsim表示通过openhownet调用的结构相似度计算函数,simdef表示通过openhownet调用的义原相似度计算函数,βstruct为structsim函数的权重参数,βdef为simdef函数的权重参数。
30、为实现上述目的,本技术还提供了一种对文言文机器翻译结果自动评估的系统,包括:
31、数据构建模块:用于根据现代文平行配对语料,通过随机和人工挑选方式,筛选出若干句子构建待评价数据集;
32、预处理模块:用于对所述待评价数据集进行预处理和分词处理;
33、测试集构建模块:用于从所述待评价数据集中获取训练语料的原文和参考译文,利用待评估的文言文机器翻译模型对所述原文进行翻译,再将得到的目标译文与参考译文和所述原文对比并进行人工分析,判断所述文言文机器翻译模型翻译的译文质量,并按照原文-参考译文-目标译文-人工打分的方式构建测试数据集;
34、评分模块:用于通过对比所述参考译文和目标译文,计算所述参考译文和目标译文的相似度,根据所述测试数据集计算所述目标译文的忠实度、流畅度、通俗度三个维度的分数,并根据所述三个维度的分数计算目标译文的平均分、误差以及相关性,对所述目标译文进行自动评分。
35、在其中一些具体实施例中,预处理模块还包括:
36、统计进行分词处理后的词语,将所述词语按照人工分词、自动分词和按照字粒度进行分词的方式进行划分,并对人工分词、自动分词和按照字粒度进行分词的效果差异进行比较。
37、在其中一些具体实施例中,测试集构建模块还包括:
38、将所述参考译文中根据篇章信息补齐的成分处理为背景词,不作为评价所述目标译文的参考。
39、在其中一些具体实施例中,评分模块还包括:
40、忠诚度计算单元:对所述参考译文和目标译文中的词两两计算相似度,设定判断同义词的阈值,将相似度高于或者等于该阈值的词语对视为近义词;再分别计算参考译文的匹配得分scoreref和目标译文的匹配得分scoretar;使用召回率作为是否丢失原文信息的判别依据并计算忠诚度,所述忠诚度的计算公式如下:
41、;
42、;
43、;
44、;
45、其中,simmax为取参考译文或目标译文中按照义原计算的最大相似度,nr为参考译文中词的个数,nt为目标译文中词的个数,scoreref为参考译文对每个词最大的相似度求和后得到的句子相似度,scoretar为目标译文对每个词最大的相似度求和后得到的句子相似度,scorematch为参考译文和目标译文的相似度得分,scorezhong为忠实度得分;
46、流畅度计算单元:通过最长连续公共子序列来计算文言文的流畅度,所述流畅度的计算公式如下:
47、;
48、;
49、其中,pen为计算流畅度过程中的惩罚项,#chunks in target sentence为根据动态规划计算出最长连续子序列的数量,#words in target sentence为句子中义原的数量,β为惩罚系数,γ为惩罚指数项;
50、通俗度计算单元:通过如下公式计算所述通俗度:
51、;
52、;
53、;
54、;
55、其中,#insertiontar和#insertionref分别为计算目标译文和参考译文的编辑次数时需要插入词的个数,#substitutiontar和#substitutionref分别为计算目标译文和参考译文的编辑次数时需要替换词的个数,#deletiontar和#deletionref分别为计算目标译文和参考译文的编辑次数时需要删除词的个数,edittar为目标译文到原文的编辑次数,editref为参考译文到原文的编辑次数,scorecon为参考译文编辑次数和目标译文编辑次数的比率,scoretong为通俗度得分。
56、在其中一些具体实施例中,相似度根据如下公式确定:
57、;
58、其中,sims表示所述目标译文和参考译文的相似度得分,s1和s2分别表示待比较概念,structsim表示通过openhownet调用的结构相似度计算函数,simdef表示通过openhownet调用的义原相似度计算函数,βstruct为structsim函数的权重参数,βdef为simdef函数的权重参数。
59、上述技术方案的有益效果:
60、(1)本技术针对机器翻译输出的古文目标译文,在评价时融入词义信息,在传统的忠实度(翻译的结果要忠实于原文的信息)、流畅度(翻译得到的目标译文要流畅自然,符合目标语言的表达习惯)的评价维度之外增加了通俗度(译文是否对原文进行了充分的翻译)的评价维度,提高了评价方法的有效性。
61、(2)与人工分词相比,自动分词切分得更细,将很多能成为词的词语变成单字词,极大降低了知网中未登录词的比例。因此,采用自动分词方法能够获得更多词义方面的信息,计算忠实度时能使大多数的词都具有词义,方便进行比较,使得本发明提出的评价方法得到的评价结果和人类评分的相关性更高。
62、(3)本技术以字为忠实度的基本粒度,相比以词为忠实度的基本粒度,无论是在忠实度单个维度来评价,还是加上流畅度和通俗度两个维度进行评价,得到的结果在与人类评分结果的相关性上都更高。并且在评价方法中加入通俗度维度后,无论以什么方法进行流畅度的评价,获得的评价结果与人类评分的相关性都有了较大的提升。
- 还没有人留言评论。精彩留言会获得点赞!