基于多模态的三维内容生成方法、装置、设备及存储介质与流程
本发明涉及三维内容生成领域,特别是涉及一种基于多模态的三维内容生成方法,本发明还涉及一种基于多模态的三维内容生成装置、设备、服务器、服务器集群及计算机可读存储介质。
背景技术:
1、三维内容的生成技术已经应用于多个领域,例如零件、汽车、飞机以及建筑设计等领域,相关技术中在生成三维内容时,需要基于用户提供的文本数据生成对应的三维内容,但是也仅仅能够将文本数据转换为三维内容,也就是说,用户无法将除文本数据之外的其他模态的数据转换为三维内容,难以满足用户多样化的需求,降低了用户体验。
2、因此,如何提供一种解决上述技术问题的方案是本领域技术人员目前需要解决的问题。
技术实现思路
1、本发明的目的是提供一种基于多模态的三维内容生成方法,可以将目标模态数据位于目标语义空间的数据特征转换为三维内容,满足了用户将多模态数据转换为三维内容的需求,提升了用户体验;本发明的另一目的是提供一种基于多模态的三维内容生成装置、设备、服务器、服务器集群及计算机可读存储介质,可以将目标模态数据位于目标语义空间的数据特征转换为三维内容,满足了用户将多模态数据转换为三维内容的需求,提升了用户体验。
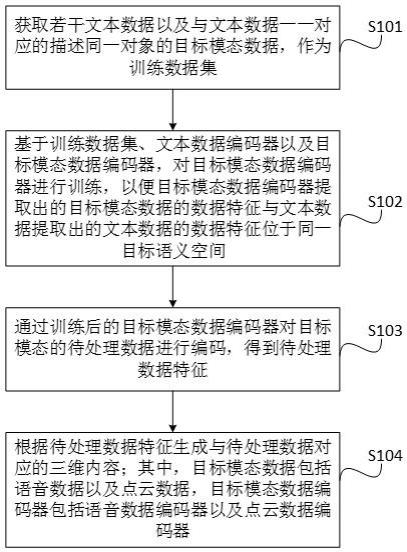
2、为解决上述技术问题,本发明提供了一种基于多模态的三维内容生成方法,包括:
3、获取若干文本数据以及与所述文本数据一一对应的描述同一对象的目标模态数据,作为训练数据集;
4、基于所述训练数据集、文本数据编码器以及目标模态数据编码器,对所述目标模态数据编码器进行训练,以便所述目标模态数据编码器提取出的目标模态数据的数据特征与所述文本数据提取出的文本数据的数据特征位于同一目标语义空间;
5、通过训练后的所述目标模态数据编码器对目标模态的待处理数据进行编码,得到待处理数据特征;
6、根据所述待处理数据特征生成与所述待处理数据对应的三维内容;
7、其中,所述目标模态数据包括语音数据以及点云数据,所述目标模态数据编码器包括语音数据编码器以及点云数据编码器。
8、另一方面,当所述目标模态数据为语音数据时,所述基于所述训练数据集、文本数据编码器以及目标模态数据编码器,对所述目标模态数据编码器进行训练具体为:
9、基于所述训练数据集、文本数据编码器以及语音数据编码器以及文本与语音模态的第一对比损失函数,对所述语音数据编码器进行训练;
10、当所述目标模态数据为点云数据时,所述基于所述训练数据集、文本数据编码器以及目标模态数据编码器,对所述目标模态数据编码器进行训练具体为:
11、将所述训练数据集中的目标文本数据输入文本编码器,得到所述文本数据对应的文本数据特征;
12、将所述训练数据集中与所述目标文本数据对应的目标点云数据输入点云数据编码器,得到所述目标点云数据对应的点云数据特征;
13、基于文本与点云模态的第二对比损失函数,通过所述目标点云数据对应的点云数据特征的自身内部对比,以及所述目标点云数据对应的点云数据特征与所述文本数据特征间的外部对比,对所述点云数据编码器进行训练。
14、另一方面,所述基于文本与点云模态的第二对比损失函数,通过所述目标点云数据对应的点云数据特征的自身内部对比,以及所述目标点云数据对应的点云数据特征与所述文本数据特征间的外部对比,对所述点云数据编码器进行训练包括:
15、通过多层感知器对所述目标点云数据对应的点云数据特征进行多次不同的信息丢弃,得到多个所述目标点云数据对应的经过不同信息丢弃的多个点云数据特征;
16、基于文本与点云模态的第二对比损失函数,通过所述目标点云数据对应的点云数据特征的自身内部对比,以及所述目标点云数据对应的点云数据特征与所述文本数据特征间的外部对比,对所述点云数据编码器进行训练;
17、其中,所述内部对比为:将同一所述目标点云数据对应的经过不同信息丢弃的多个点云数据特征作为正样本,将不同所述目标点云数据对应的所述点云数据特征作为负样本,对所述目标点云数据对应的点云数据特征的自身内部对比。
18、另一方面,所述第一对比损失函数包括:
19、;
20、其中,s表示文本模态,a表示语音模态,为文本模态与语音模态的数据对比损失,表示为文本模态的第i个样本提取的特征,表示语音模态的第 j个样本提取的特征,sim表示两个向量的cosine相似度,n为单一批次内的样本数量,τ为预定义的超参数,为语音模态的第i个样本提取的特征。
21、另一方面,所述第二对比损失函数包括:
22、;
23、;
24、;
25、其中,p代表点云模态,为文本模态与点云模态的数据对比损失,为所述目标点云数据对应的点云数据特征的自身内部对比的对比损失,为所述目标点云数据对应的点云数据特征与所述文本数据特征间的外部对比的对比损失,和是点云样本 i经过两次不同的信息丢弃得到的特征向量,和是点云样本j经过两次不同的信息丢弃得到的特征向量,表示为文本模态的第 i个样本提取的特征,λ为预设系数,n为单一批次内的样本数量,τ为预定义的超参数。
26、另一方面,所述文本数据编码器包括基于对比文本-图像对的预训练模型。
27、另一方面,所述语音数据编码器包括预训练的音频神经网络模型。
28、另一方面,所述通过训练后的所述目标模态数据编码器对目标模态的待处理数据进行编码,得到待处理数据特征之后,所述根据所述待处理数据特征生成与所述待处理数据对应的三维内容之前,该基于多模态的三维内容生成方法还包括:
29、将指定模态的待编码数据位于所述目标语义空间的数据特征作为输入,将与所述待编码数据描述同一对象的点云数据特征作为输出,通过指定模态特征与点云特征之间的第一损失函数,对第一目标扩散模型进行训练,以便将所述目标语义空间的数据特征直接映射至点云数据特征;
30、将所述待处理数据特征输入经过训练的所述第一目标扩散模型,得到位于所述目标语义空间的与所述待处理数据对应的目标点云特征;
31、所述根据所述待处理数据特征生成与所述待处理数据对应的三维内容包括:
32、根据所述目标点云特征生成与所述待处理数据对应的三维内容。
33、另一方面,所述将指定模态的待编码数据位于所述目标语义空间的数据特征作为输入,将与所述待编码数据描述同一对象的点云数据特征作为输出,通过指定模态特征与点云特征之间的第一损失函数,对第一目标扩散模型进行训练,以便将所述目标语义空间的数据特征直接映射至点云数据特征包括:
34、获取指定模态的待编码数据位于所述目标语义空间的数据特征、与所述待编码数据描述同一对象的点云数据特征以及与所述待编码数据描述同一对象的图像数据;
35、判断随机生成的随机概率是否大于预设阈值;
36、若大于,将所述指定模态的待编码数据位于所述目标语义空间的数据特征作为输入,将与所述待编码数据描述同一对象的点云数据特征作为输出;
37、若不大于,将与所述待编码数据描述同一对象的图像数据位于所述目标语义空间的数据特征,和所述指定模态的待编码数据位于所述目标语义空间的数据特征进行融合得到融合输入特征作为输入,将与所述待编码数据描述同一对象的点云数据特征作为输出;
38、根据确定出的输入以及输出对第一目标扩散模型进行训练,并根据指定模态特征与点云特征之间的第一损失函数判断是否所述第一目标扩散模型是否收敛;
39、若收敛,则训练完成;
40、若不收敛,执行所述获取指定模态的待编码数据位于所述目标语义空间的数据特征、与所述待编码数据描述同一对象的点云数据特征以及与所述待编码数据描述同一对象的图像数据的步骤。
41、另一方面,所述与所述待编码数据描述同一对象的图像数据包括:
42、与所述待编码数据描述同一对象的多个视角的图像数据。
43、另一方面,所述指定模态包括文本数据。
44、另一方面,所述第一损失函数包括:
45、;
46、其中, l p1为与所述待编码数据描述同一对象的点云数据特征与所述第一目标扩散模型预测的点云数据特征间的损失,t表示时间扩散第t步,et为第t个时间扩散步的期望,t为时间扩散步的总数预设值, fprior为第一目标扩散模型,ztext表示指定模态的待编码数据位于所述目标语义空间的数据特征,z f表示所述多视角图像对应的数据特征,zp表示与所述待编码数据描述同一对象的所述点云数据特征,表示第t个时间步加噪声的所述点云数据特征。
47、另一方面,所述根据所述目标点云特征生成与所述待处理数据对应的三维内容包括:
48、通过预先训练的点云生成网络,根据所述目标点云特征生成与所述待处理数据对应的三维内容;
49、其中,所述点云生成网络的预训练过程包括:
50、将基于训练后的所述第一目标扩散模型提取的点云特征、时间步特征以及带噪点的训练用点云特征作为输入,通过第二损失函数对第二目标扩散模型进行训练,得到点云生成网络。
51、另一方面,所述第二损失函数包括:
52、;
53、其中, l p2为所述训练用点云特征与所述第二目标扩散模型预测的点云数据特征间的损失,zg为基于训练后的所述第一目标扩散模型提取的点云特征,t为所述时间步特征,为所述训练用点云特征,为所述带噪点的所述训练用点云特征,t表示时间扩散第t步,concat()表示向量拼接操作,et为第t个时间扩散步的期望,t为时间扩散步的总数预设值,f为第二目标扩散模型。
54、另一方面,所述根据所述待处理数据特征生成与所述待处理数据对应的三维内容之后,该基于多模态的三维内容生成方法还包括:
55、通过上采样模型扩充得到的所述三维内容中的点云数量。
56、另一方面,所述根据所述目标点云特征生成与所述待处理数据对应的三维内容之后,该基于多模态的三维内容生成方法还包括:
57、将当前的所述目标点云特征记录为所述待处理数据对应的三维内容的历史点云特征;
58、响应于对于所述三维内容的修改指令,确定所述修改指令指定的补充数据;
59、基于经过训练的所述第一目标扩散模型,将所述补充数据位于所述目标语义空间的数据特征转换为点云数据特征;
60、根据所述补充数据对应的点云数据特征与所述三维内容的历史点云特征的融合数据特征,生成三维内容。
61、另一方面,所述响应于对于所述三维内容的修改指令,确定所述修改指令指定的补充数据包括:
62、响应于对于所述三维内容的修改指令,判断所述三维内容是否被锁定;
63、若未被锁定,则确定所述修改指令指定的补充数据;
64、若被锁定,控制提示器提示所述三维内容被锁定;
65、该基于多模态的三维内容生成方法还包括:
66、根据锁操作指令对所述三维内容进行锁定或解锁操作。
67、为解决上述技术问题,本发明还提供了一种基于多模态的三维内容生成装置,包括:
68、获取模块,用于获取若干文本数据以及与所述文本数据一一对应的描述同一对象的目标模态数据,作为训练数据集;
69、训练模块,用于基于所述训练数据集、文本数据编码器以及目标模态数据编码器,对所述目标模态数据编码器进行训练,以便所述目标模态数据编码器提取出的目标模态数据的数据特征与所述文本数据提取出的文本数据的数据特征位于同一目标语义空间;
70、编码模块,用于通过训练后的所述目标模态数据编码器对目标模态的待处理数据进行编码,得到待处理数据特征;
71、生成模块,用于根据所述待处理数据特征生成与所述待处理数据对应的三维内容;
72、其中,所述目标模态数据包括语音数据以及点云数据,所述目标模态数据编码器包括语音数据编码器以及点云数据编码器。
73、为解决上述技术问题,本发明还提供了一种基于多模态的三维内容生成设备,包括:
74、存储器,用于存储计算机程序;
75、处理器,用于执行所述计算机程序时实现如上所述基于多模态的三维内容生成方法的步骤。
76、为解决上述技术问题,本发明还提供了一种服务器,包括如上所述的基于多模态的三维内容生成设备。
77、为解决上述技术问题,本发明还提供了一种服务器集群,包括至少一台如上所述的服务器。
78、为解决上述技术问题,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上所述基于多模态的三维内容生成方法的步骤。
79、有益效果:本发明提供了一种基于多模态的三维内容生成方法,考虑到针对语音与点云模态的数据均容易得到对应的文本数据,因此本发明中可以预先获取若干文本数据以及与文本数据一一对应的描述同一对象的目标模态数据,作为训练数据集,然后基于训练数据集、文本数据编码器以及目标模态数据编码器,对目标模态数据编码器进行训练,使得目标模态数据编码器提取出的目标模态数据的数据特征与文本数据提取出的文本数据的数据特征位于同一目标语义空间,如此一来,便可以将目标模态数据位于目标语义空间的数据特征转换为三维内容,满足了用户将多模态数据转换为三维内容的需求,提升了用户体验。
80、本发明还提供了一种基于多模态的三维内容生成装置、设备、服务器、服务器集群以及计算机可读存储介质,具有如上基于多模态的三维内容生成方法相同的有益效果。
- 还没有人留言评论。精彩留言会获得点赞!