一种文书自动排版方法及系统与流程
本发明涉及数字处理,尤其涉及一种文书自动排版方法及系统。
背景技术:
1、现有技术中,文书文件只是文字符号的堆积,其本身不具有一定的编排格式,为了方便用户的阅读又或者使其具有一定的严肃性,需要对文书文件而进行一定的排版使其形成具有特定格式的文字材料,其有较强的规范性及表现形式,而所述排版过程往往需要对字符、段落和页面格式统一进行编辑排版,并且所述文书文件还可以存在图形、表格和图像等元素。
2、现有技术中对文书进行排版的方式包括两种类型,一种为人工排版,另一种为使用排版软件进行排版。其中,人工排版对用户的要求比较高,需要用户熟悉各类文件的排版要求并保持长时间的注意力集中,容易造成排版失误,同时使用人工排版往往需要不同的用户进行排版文件的复查,造成排版效率低下,而另一类使用排版软件进行排版需要用户提前在排版软件上设置排版参数,一是根据所述排版参数进行排版,往往造成若排版的文件类型不同,则需要用户不断地调式所述排版软件的设置参数,进而造成效率低下及精准度过低。
3、因此,现有技术中存在人工排版效率低下、软件排版中造成若排版的文件类型不同,而造成效率低下及精准度过低的技术问题,目前市面上亟需一种新的文书自动排版策略,以解决上述现有技术中的技术问题。
技术实现思路
1、本发明公开了一种文书自动排版方法及系统,基于深度学习模型学习不同类型的文书文件的排版规则,进而实现自动排版,提高排版的效率及准确度。
2、为了实现上述目的,本发明公开了一种文书自动排版方法,包括:
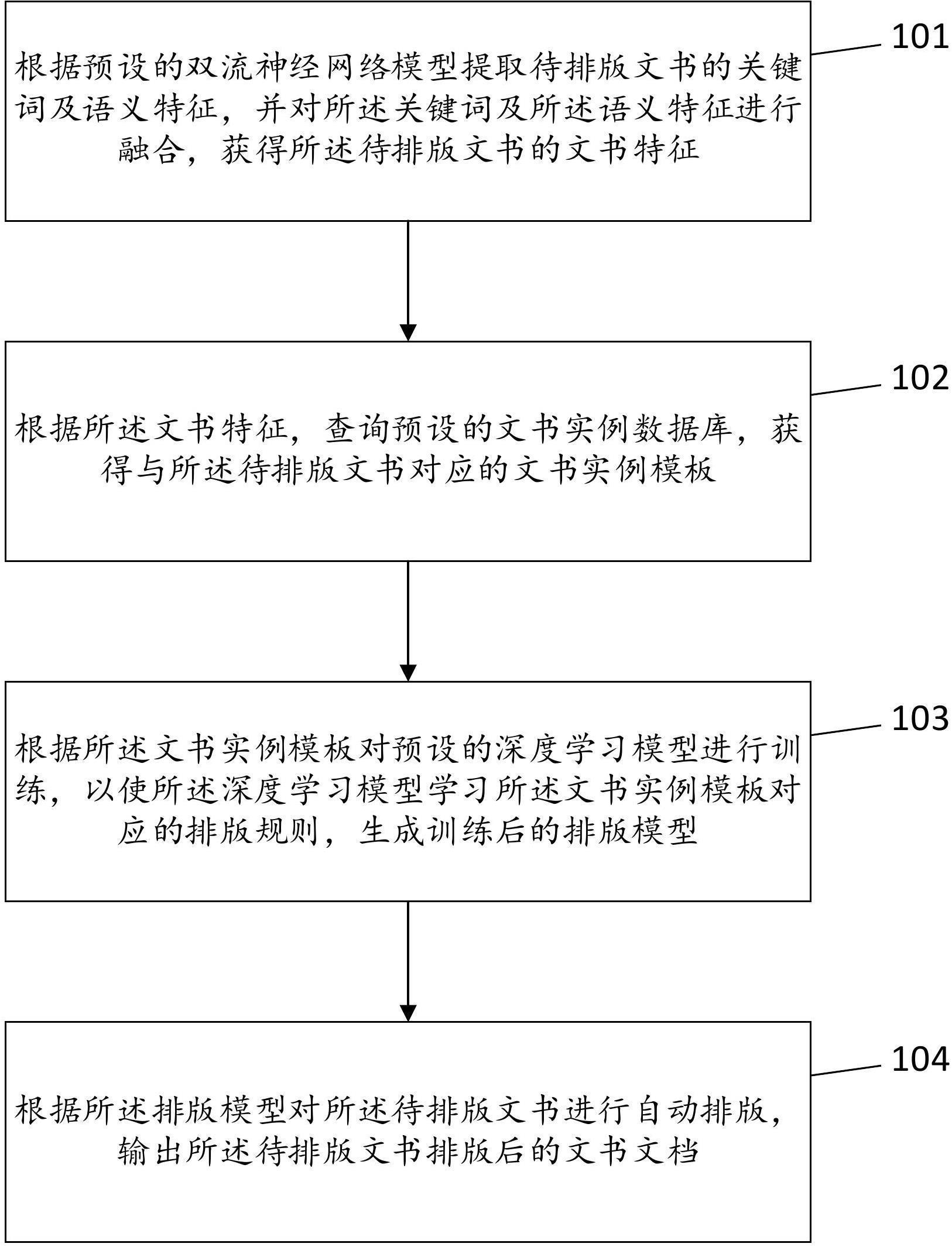
3、根据预设的双流神经网络模型提取待排版文书的关键词及语义特征,并对所述关键词及所述语义特征进行融合,获得所述待排版文书的文书特征;
4、根据所述文书特征,查询预设的文书实例数据库,获得与所述待排版文书对应的文书实例模板;
5、根据所述文书实例模板对预设的深度学习模型进行训练,以使所述深度学习模型学习所述文书实例模板对应的排版规则,生成训练后的排版模型;
6、根据所述排版模型对所述待排版文书进行自动排版,输出所述待排版文书排版后的文书文档。
7、本发明公开了一种文书自动排版方法,包括提取所述待排版文书的关键词及语义特征,并融合所述关键词及所述语义特征获得所述待排版文书的文书特征,以使得根据所述文书特征包含的关键词及语义特征同预设在文书实例数据库中的文书实例模板进行特征比对,以使精准的获得所述待排版文书对应的文书实例模板,进而提高所述待排版文书排版的准确度,接着利用预设的深度学习模型学习所述精准获得的文书实例模板的排版规则,并根据所述排版规则生成所述排版模型,以使得根据训练后的排版模型对所述待排版文书进行排版,本发明通过所述深度学习模型可以自动学习不同类型的文书实例模板的排版规则,进而形成不同类型文书的排版模型,以此避免了现有技术中用户不断调试不同的排版参数以适应不同类型文书而造成的效率低下,提高了文书的排版效率,同时本发明通过学习输入的待排版文书的对应的文书实例模板的排版规则对所述待排版文书进行排版,提高了文书排版的精准度。
8、作为优选例子,在所述通过预设的双流神经网络模型提取待排版文书的关键词及语义特征,并对所述关键词及所述语义特征进行融合,具体包括:
9、通过所述双流神经网络模型中的时间流的第一卷积层,提取所述待排版文书的语义特征数据,并对所述语义特征数据进行卷积处理,获得所述待排版文书的语义特征;
10、利用所述双流神经网络模型的空间流中预设的文本关键词提取算法,提取所述待排版文书的关键词数据,并对所述关键词数据进行卷积处理,获得所述待排版文书的关键词;
11、根据所述关键词及所述语义特征,通过所述双流神经网络模型的全连接层中预设的融合公式,对所述语义特征及所述关键词进行线性组合,获得所述待排版文书的文书特征。
12、本发明利用改进的双流神经网络模型的空间流及时间流,分别提取所述待排版文书的关键词数据及语义特征数据,并利用所述神经网络模型中的卷积层对所述提取的关键词数据及语义特征数据进行进一步的处理,以使提高所述关键词及所述语义特征的精确度,在获得所述关键词及所述语义特征后,利用预设在所述双流神经网络模型的全连接层中的融合方式对所述关键词及所述语义特征进行融合,以使提高所述文书特征的定向性,以使提高后续匹配文书实例模板的准确度。
13、作为优选例子,在所述根据所述文书特征,查询预设的文书实例数据库,获得与所述待排版文书对应的文书实例模板,具体包括:
14、根据所述文书特征,查询所述文书实例数据库设置的实例特征表,并通过预设的特征匹配算法分别计算所述文书特征与预设在所述实例特征表中若干个实例特征的相似度,获得若干个文本特征相似度;
15、通过对所述若干个文本特征相似度分别进行比较,获得所述文本特征相似度最高的第一实例特征,并根据所述第一实例特征获得对应的文书实例模板。
16、本发明通过计算所述待排版文书的文书特征与实例特征表中的若干个实例特征的若干个相似度,避免了现有技术中文书与文书之间进行匹配造成的计算量过大的技术问题,降低了计算量,提高了匹配效率,同时通过对所述若干个相似度之间进行一一比较,选择出相似度最高的第一实例特征,再获得所述第一实例特征对应的文书实例模板,进而为所述待排版文书提供了一个精确的排版模板,提高了排版的精确度。
17、作为优选例子,所述通过预设的特征匹配算法分别计算所述文书特征与预设在所述实例特征表中若干个实例特征的相似度的步骤,具体包括:
18、对所述文书特征进行二进制转换,得到第一数列;
19、分别对提取得到的若干个实例特征进行二进制转换,得到多个第二数列;
20、将所述第一数列分别与所有的第二数列进行空间距离计算,得到对应的相似值作为所述文书特征分别与所述实例特征的相似度;
21、将所述相似值最大的第二数列所对应的实例特征作为相似度最高的实例特征并获取对应的文书实例模板。
22、作为优选例子,在所述深度学习模型学习所述文书实例模板对应的排版规则,生成训练后的排版模型,具体包括:
23、通过将所述文书实例模板作为所述深度学习模型的训练数据,以使所述深度学习模型提取所述文书实例模板的排版规则;
24、根据所述排版规则,通过预设的监督学习方法对所述深度学习模型不断训练,生成所述排版模型。
25、本发明利用预设的深度学习模型可以自动学习不同类型的文书实例模板的不同排版规则,并根据所述排版规则及预设的监督学习方法对所述深度学习模型不断训练,生成不同文书类型对应的不同的排版模型,以此解决了现有技术中人工调整排版参数而造成的效率低下,利用深度学习模型自动学习的特性,提高了文书排版的效率。
26、作为优选例子,在所述排版模型对所述待排版文书进行自动排版,输出所述待排版文书排版后的文书文档,具体包括:
27、根据所述排版模型中预设的卷积层对所述待排版文书进行逻辑划分,生成若干个第一段落文本片,并分别提取所述若干个第一段落文本片的特殊字段以使根据所述特殊字段分别匹配所述若干个第一段落文本片对应处理的池化层;
28、通过所述池化层分别对所述若干个第一段落文本片进行字体设置及段落设置,生成若干个第二段落文本片;所述段落设置包括存储样式,对齐方式、左右缩进、行距、首行缩进类型;所述字体设置包括存储样式,字体、字号、样式、颜色及字符间距;
29、通过所述排版模型中预设的编码器定义所述若干个第二段落文本片的上下文关系,并通过所述排版模型中预设的解码器根据所述上下文关系对所述若干个第二段落文本片进行文本组合,输出所述待排版文书排版后的文书文档。
30、本发明根据所述深度学习模型学习文本实例模板的逻辑关系、段落设置及字体设置以及上下文关系,获得排版规则,再根据所述逻辑关系、段落设置及字体设置以及上下文关系对所述待排版文书进行段落拆分,文字排版,进而生成排版后的文书文档,提高排版的效率及准确度。
31、另一方面,本发明公开了一种文书自动排版系统,包括特征提取模块、文书匹配模块、模型训练模块及文书排版模块。
32、所述特征提取模块用于根据预设的双流神经网络模型提取待排版文书的关键词及语义特征,并对所述关键词及所述语义特征进行融合,获得所述待排版文书的文书特征;
33、所述文书匹配模块用于根据所述文书特征,查询预设的文书实例数据库,获得与所述待排版文书对应的文书实例模板;
34、所述模型训练模块用于根据所述文书实例模板对预设的深度学习模型进行训练,以使所述深度学习模型学习所述文书实例模板对应的排版规则,生成训练后的排版模型;
35、所述文书排版模块用于根据所述排版模型对所述待排版文书进行自动排版,输出所述待排版文书排版后的文书文档。
36、本发明公开的一种文书自动排版系统,包括提取所述待排版文书的关键词及语义特征,并融合所述关键词及所述语义特征获得所述待排版文书的文书特征,以使得根据所述文书特征包含的关键词及语义特征同预设在文书实例数据库中的文书实例模板进行特征比对,以使精准的获得所述待排版文书对应的文书实例模板,进而提高所述待排版文书排版的准确度,接着利用预设的深度学习模型学习所述精准获得的文书实例模板的排版规则,并根据所述排版规则生成所述排版模型,以使得根据训练后的排版模型对所述待排版文书进行排版,本发明通过所述深度学习模型可以自动学习不同类型的文书实例模板的排版规则,进而形成不同类型文书的排版模型,以此避免了现有技术中用户不断调试不同的排版参数以适应不同类型文书而造成的效率低下,提高了文书的排版效率,同时本发明通过学习输入的待排版文书的对应的文书实例模板的排版规则对所述待排版文书进行排版,提高了文书排版的精准度。
37、作为优选例子,所述特征提取模块包括提取单元及融合单元;
38、所述提取单元用于通过所述双流神经网络模型中的时间流的第一卷积层,提取所述待排版文书的语义特征数据,并对所述语义特征数据进行卷积处理,获得所述待排版文书的语义特征;利用所述双流神经网络模型的空间流中预设的文本关键词提取算法,提取所述待排版文书的关键词数据,并对所述关键词数据进行卷积处理,获得所述待排版文书的关键词;
39、所述融合单元用于根据所述关键词及所述语义特征,通过所述双流神经网络模型的全连接层中预设的融合公式,对所述语义特征及所述关键词进行线性组合,获得所述待排版文书的文书特征。
40、本发明利用改进的双流神经网络模型的空间流及时间流,分别提取所述待排版文书的关键词数据及语义特征数据,并利用所述神经网络模型中的卷积层对所述提取的关键词数据及语义特征数据进行进一步的处理,以使提高所述关键词及所述语义特征的精确度,在获得所述关键词及所述语义特征后,利用预设在所述双流神经网络模型的全连接层中的融合方式对所述关键词及所述语义特征进行融合,以使提高所述文书特征的定向性,以使提高后续匹配文书实例模板的准确度。
41、作为优选例子,所述文书匹配模块包括计算单元及选择单元;
42、所述计算单元用于根据所述文书特征,查询所述文书实例数据库设置的实例特征表,并通过预设的特征匹配算法分别计算所述文书特征与预设在所述实例特征表中若干个实例特征的相似度,获得若干个文本特征相似度;其中,所述通过预设的特征匹配算法分别计算所述文书特征与预设在所述实例特征表中若干个实例特征的相似度的步骤,具体包括:对所述文书特征进行二进制转换,得到第一数列;分别对提取得到的若干个实例特征进行二进制转换,得到多个第二数列;将所述第一数列分别与所有的第二数列进行空间距离计算,得到对应的相似值作为所述文书特征分别与所述实例特征的相似度;将所述相似值最大的第二数列所对应的实例特征作为相似度最高的实例特征并获取对应的文书实例模板。
43、所述选择单元用于通过对所述若干个文本特征相似度分别进行比较,获得所述文本特征相似度最高的第一实例特征,并根据所述第一实例特征获得对应的文书实例模板。
44、本发明通过计算所述待排版文书的文书特征与实例特征表中的若干个实例特征的若干个相似度,避免了现有技术中文书与文书之间进行匹配造成的计算量过大的技术问题,降低了计算量,提高了匹配效率,同时通过对所述若干个相似度之间进行一一比较,选择出相似度最高的第一实例特征,再获得所述第一实例特征对应的文书实例模板,进而为所述待排版文书提供了一个精确的排版模板,提高了排版的精确度。
45、作为优选例子,所述模型训练模块包括学习单元及训练单元;
46、所述学习单元用于通过将所述文书实例模板作为所述深度学习模型的训练数据,以使所述深度学习模型提取所述文书实例模板的排版规则;
47、所述训练单元用于根据所述排版规则,通过预设的监督学习方法对所述深度学习模型不断训练,生成所述排版模型。
48、本发明利用预设的深度学习模型可以自动学习不同类型的文书实例模板的不同排版规则,并根据所述排版规则及预设的监督学习方法对所述深度学习模型不断训练,生成不同文书类型对应的不同的排版模型,以此解决了现有技术中人工调整排版参数而造成的效率低下,利用深度学习模型自动学习的特性,提高了文书排版的效率。
49、作为优选例子,所述文书排版模块包括划分单元、设置单元及组合单元;
50、所述划分单元用于根据所述排版模型中预设的卷积层对所述待排版文书进行逻辑划分,生成若干个第一段落文本片,并分别提取所述若干个第一段落文本片的特殊字段以使根据所述特殊字段分别匹配所述若干个第一段落文本片对应处理的池化层;
51、所述设置单元用于通过所述池化层分别对所述若干个第一段落文本片进行字体设置及段落设置,生成若干个第二段落文本片;所述段落设置包括存储样式,对齐方式、左右缩进、行距、首行缩进类型;所述字体设置包括存储样式,字体、字号、样式、颜色及字符间距;
52、所述组合单元用于通过所述排版模型中预设的编码器定义所述若干个第二段落文本片的上下文关系,并通过所述排版模型中预设的解码器根据所述上下文关系对所述若干个第二段落文本片进行文本组合,输出所述待排版文书排版后的文书文档。
53、本发明根据所述深度学习模型学习文本实例模板的逻辑关系、段落设置及字体设置以及上下文关系,获得排版规则,再根据所述逻辑关系、段落设置及字体设置以及上下文关系对所述待排版文书进行段落拆分,文字排版,进而生成排版后的文书文档,提高排版的效率及准确度。
- 还没有人留言评论。精彩留言会获得点赞!