一种基于语义分量的词向量学习方法
本发明涉及自然语言处理,具体是涉及一种基于语义分量的词向量学习方法。
背景技术:
1、自然语言处理是人工智能的一个重要分支,它的目标是让计算机理解人类的语言,有问答系统、机器翻译、命名实体识别等众多具体应用。近年来深度学习迅速崛起,对自然语言处理的大多数应用问题,基于深度学习的方法在处理效果上比以前的方法都有显著的提升。
2、词嵌入(word embedding),又称为词向量,是指把一个维数为所有词的个数的高维空间(称为one-hot向量)映射到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的一个向量。词嵌入是基于深度学习的自然语言处理的基石,在深度学习网络中人们首先把每个单词映射为各自对应的词向量。
3、one-hot向量非常直观,它将所有的词组成一个词表,行列都由词表的词组成。使用one-hot方法表示词会导致维度爆炸和数据稀疏问题,并忽略词语之间的语义关系,这是十分致命的。harris(harris z s.distributional stracture[j].word,1954,10(2—3):146-162.)在1954年提出分布式假说,认为上下文相近的词,其语义也相似。firth(firthj.asynopsis oflinguistic theory[z].1957.)在1957年对分布式假说做进一步说明:词的语义由其上下文决定。也就是说一个词的词义不应该仅仅只看这个词,而要联系这个词的上下文来确定这个词的词义。rumelhart(david e rumelhart,geoffrey e hinton,andronald j williams.learningrepresentations by backpropagating errors[c].cognitive modeling,1988:5(3):1.)在1988年提出分布式表示这一想法,把所有词语投射到一个连续的低维语义空间中,把每一个词都考虑成一个向量,就是现在所说的词嵌入。
4、生成连续低维词表示的方法有很多。有基于矩阵的矩阵分解法来获取连续的词表示。比如潜在语义分析(deerwester,s.,dumais,s.t.,furnas,g.w.,landauer,t.k.,&harshman,r.indexing by latent semantic analysis[c].journal of the americansociety for informationscience,1990:391-407.)用“词-文本”类型的矩阵分解语料库信息,这个方法能很好地收集每个词的统计信息,但却不能有效地捕捉上下文信息,也就是说该方法对语义的表达能力不够好。glove模型(jeffrey pennington,richard socher,and christopher d.manning.glove:globalvectors for word representation[j].inacl,2014.)利用“词-词”的全局共现矩阵,不仅具有每个词的全局统计信息,还能捕捉特定窗口大小词的共现频率信息,能将词的全局信息和“词-词”的局部信息有效地结合起来。
5、上述是基于矩阵的方法获取词向量,还有些方法是使用神经网络来获取词向量。比如bengio(yoshua bengio,rejean ducharme,pascal vincent,and christianjanvin.a neuralprobabilistic language model[c].jmlr,2003,3:1137-1155.)在2003年提出一个神经语言模型,该模型解决的是在给定已出现词语的文本中预测下一个单词的任务。该模型使用神经网络模型参数量很大,运行效率较低,论文中使用并行的方式来提高效率。mikolov(tomas mikolov,kai chen,greg corrado,and jeffrey dean.efficientestimation of word representations in vectorspace[j].in iclr workshop papers,2013a.)在2013年提出cbow和skip-gram两个模型,cbow模型的目标是在给定其上下文的情况下预测单词,skip-gram模型的目标是在给定单词本身的情况下预测单词的上下文。这两个模型使用负样本的方式大大降低神经网络模型的参数量,在效率和性能上取得较好平衡。
6、上述的一些模型都忽视一个问题,那就是这些模型参数的初始化都是随机的。这有可能使得语义相近的词的词向量距离很远,而语义相差很多的词的词向量距离很近,与本发明的训练目标相反,从而需要更多的训练才能收敛。
技术实现思路
1、本发明的目的在于针对“模型初始化是随机的”而产生的上述技术问题,提供一种基于语义分量的词向量学习方法。在词向量训练的初始化中,本发明不仅让语义相近的词的词向量距离较近,让语义相差很多的词的词向量距离较远,而且在词向量中注入人工知识,从而能加快词向量的训练过程,而且词向量具有更多的语义信息。
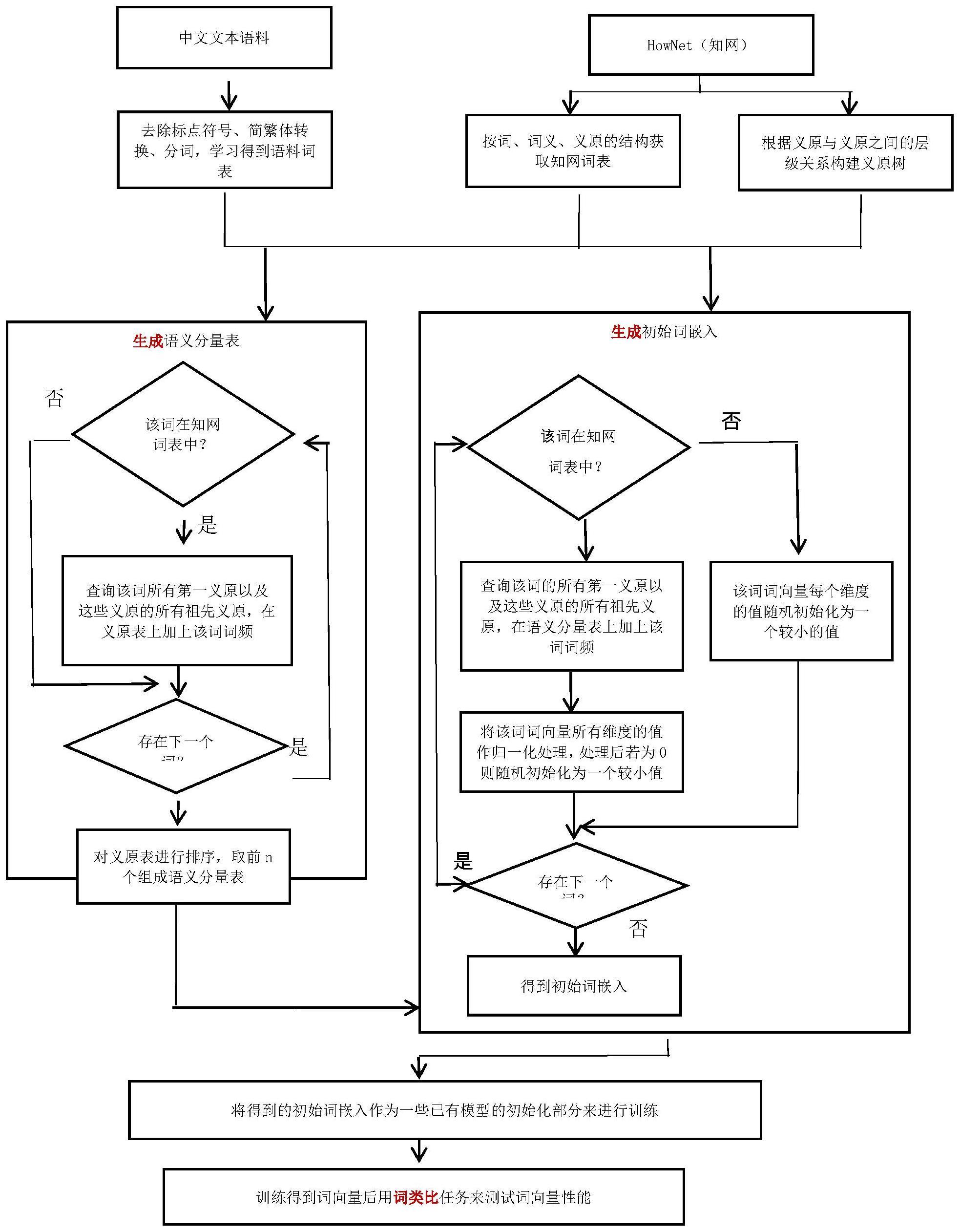
2、本发明包括以下步骤:
3、a.准备大规模无标注的中文文本语料和知网(hownet)知识库;
4、b.对文本语料和hownet进行处理,得到文本语料词表、知网词表和义原树;
5、c.利用hownet中词、词义和义原的关系以及义原之间的层级关系结合语料词表和词频信息生成语义分量表;
6、d.根据步骤c所得语义分量表,结合知网词表中每个词所含义原以及义原之间的层级关系生成初始词嵌入;
7、e.将生成的初始词嵌入作为一些已有模型的初始化部分来进行训练,例如作为cbow、skip-gram和glove等几个经典模型的初始化部分来训练词向量。
8、在步骤a中,所述中文文本语料使用的是sogout网页语料,该语料由搜狐公司提供,包括来自互联网各种类型的1.3亿个原始网页,压缩前的大小超过5tb;知网(hownet)知识库是董振东和董强父子创建的基于义原的知识库,可以从公司hownet technology inc.获取该知识库。
9、在步骤b中,所述对文本语料和知网处理进一步包括以下子步骤:
10、b1.对文本语料进行去除标点符号、简繁体转换和分词等处理,得到语料词表并按词频排序。
11、b2.将hownet知识库按词、词义、义原的结构进行结构化处理,得到知网词表。
12、b3.根据义原之间的层级关系构建义原树。
13、在步骤c中,所述生成语义分量表进一步包括以下子步骤:
14、c1.遍历语料词表中的词:判断语料词表中的当前词是否在知网词表中,若在则执行步骤c2,若不在则取语料词表中的下一个词并继续步骤c1的判断。
15、c2.查询该词的所有词义的第一义原并通过义原树查询这些义原的所有祖先义原,在义原表中将这些义原以及这些义原的所有祖先义原的频数加上该词在语料中的词频。
16、词义的第一义原指的是该词义在hownet中的def的从左到右的第一个义原,该义原是该词义的类;例如,“儿童”词义的第一义原是“human|人”。
17、义原表中的每个义原的频数的初始值为0。
18、c3.执行完步骤c1之后,将义原表按义原的频数排序,取前n个义原表示的语义生成语义分量表g{x1,x2,…,xn},其中x1,x2,…,xn是n个义原,n为词向量维度大小。
19、语义分量表g可以形式化地表示如下:
20、语义分量表g{x1,x2,…,xn}表示频数最高的前n个义原,这里n与词向量维度大小一致,
21、
22、其中,义原xi'∈x,x表示义原集合,w表示知网词表,wi和wj均表示词,f(xi')表示义原xi'的频数,f(wi)表示词wi的频数,ch(xi')表示义原xi'的子孙义原集合,s(wi)表示词wi的每个词义的第一义原所构成的集合;该公式的含义是一个义原xi'的频数是所有以该义原为第一义原的词的频数之和加上所有以该义原的子孙义原为第一义原的词的频数之和。将所有义原根据义原的频数大小进行排序,取前n个频数最高的义原可以得到语义分量表g,语义分量表g的大小与词向量维度大小一致,且g的每个义原与词向量的维度一一对应;
23、通过上述算法,得到与语料库单词最相关的最重要的义原,这些义原构成语义分量表g;语义分量表g{x1,x2,…,xn}中,n与词向量维度大小一致,每个义原xi与词向量的第i维对应。
24、在步骤d中,所述生成初始词嵌入进一步包括以下子步骤:
25、d1.判断语料词表中的词是否在知网词表中,若不在则该词的词向量(也称为词嵌入)每一个分量(即维度)都随机初始化为一个较小的值。若在,则进行步骤d2和d3。
26、d2.判断该词wi的所有词义的第一义原及这些义原的祖先义原是否出现在语义分量表中。若出现,则每出现一次就在词嵌入对应的分量(即维度)上累加上一次该词的词频。若同一个义原出现多次,就要加多次。若不出现,则不处理该义原。
27、d3.该词wi的所有词义的第一义原及这些义原的祖先义原若出现在语义分量表中,则对该词的词嵌入中对应的分量上累加的词频归一化。该词的词嵌入中没有归一化的分量,则随机初始化为一个较小的值。
28、可以用以下公式形式化地表示每个词wi的初始词向量
29、
30、其中:
31、
32、rand(-a,a)是产生一个(-a,a)的随机实数,a取较小值;g表示语义分量表g{x1,x2,...,xn}。i'表示某个语义分量的下标,xi'表示某个语义分量。s(wi)表示单词wi的每个词义的第一义原所构成的集合,该集合中同一个元素可以重复多次;an(s(wi))表示s(wi)中的所有义原的所有祖先义原构成的集合,该集合中同一个元素可以重复多次。表示单词wi的词向量,表示的第i'个分量的值。若语义分量表的第i'个分量是该词的词义的第一义原或这些义原的祖先义原,则该分量所表示的维度的值为该处的频数与该词的所有词义的第一义原以及这些义原的祖先义原的频数之和的比值,否则使用随机值rand(-a,a)来初始化。
33、使用语义分量初始化词嵌入有助于提升词嵌入的训练,因为语义相近的词拥有相似的语义分量,所以使用语义分量去初始化词嵌入,语义相近的词的初始嵌入在空间上是相近的,这与训练词嵌入的目标“两个词的语义相近,那么它们的嵌入也是相近的。”是一致的;而随机初始化词嵌入,语义相近的词的词嵌入不一定是相近的。另外,单词拥有的语义分量是该单词的语义,使用语义分量去初始化词嵌入,词向量具有更多的语义信息。
34、本发明从文本语料中统计出语料词表和词频,利用知网(hownet)知识库中词、词义和义原的关系以及义原之间的层级关系结合语料词表和词频信息得到语义分量表;然后根据语义分量表再结合词表中每个词所含义原以及义原之间的层级关系得到初始词嵌入;最后将得到的初始词嵌入作为一些已有的经典模型的初始化部分进行训练,完成词向量(也称词嵌入)的学习,最终用学习到的词向量进行词类比测试。实验证明,在词类比任务中本发明的模型对比基线模型准确率高出1~5个百分点。
- 还没有人留言评论。精彩留言会获得点赞!