一种基于对比学习联合优化的推荐方法、装置及设备
本发明涉及计算机,尤其涉及一种基于对比学习联合优化的推荐方法、装置及设备。
背景技术:
1、推荐系统已被广泛用于缓解现实世界应用(例如社交媒体、新闻、视频和电子商务)中的信息过载。它旨在根据用户的历史交互来估计用户是否会对某个物品表现出偏好。
2、图对比学习(graph contrastive learning,gcl)由于其简单的模型设计和在数据稀疏环境中的有效性,已经成为深度表征学习的一个突出研究领域。因此,越来越多的研究关注于利用gcl来提高推荐性能。一个典型的基于gcl的推荐模型如图2中子图(a)所示,该推荐模型通过应用结构扰动(例如,随机边缘丢弃)或嵌入扰动(例如,随机均匀噪声)产生两种不同的视图。最后,对比学习(cl)损失函数被用来增加目标节点和其正面样本之间的相似性,同时减少与负面样本的相似性,推荐损失函数用于修正推荐偏差,对比学习损失和推荐损失两者独立求取和应用。
3、现有技术中,公开号为cn 115659059 a的中国专利公开了基于图对比学习的推荐模型训练方法,该专利通过对初始图进行数据增强,生成不同的增强视图,通过对比学习从不同的增强视图中提取更多的信息,提升推荐模型对于用户和对象的向量表示的准确性,使推荐模型可以更加准确地挖掘用户对于对象的偏好,进而提高推荐模型向目标用户进行对象推荐的准确性。
4、尽管数据增强技术(如结构扰动和嵌入扰动)已作为gcl的重要工具,但本领域技术人员对它们在推荐领域内的作用一直存在怀疑,如现有论文(如junliang yu,hongzhiyin,xin xia,tong chen,lizhen cui,and quoc viet hung nguyen.2022.are graphaugmentations necessary simple graph contrastive learning forrecommendation.in proceedings of the 45th international acm sigir conferenceon research and development in information retrieval.1294-1303)中就认为结构扰动方式的增强技术对推荐性能没有发挥作用,但缺乏对特征增强有效性效果的考虑。本技术发明人在此基础上对结构扰动方式和嵌入方法对推荐性能的作用进一步进行了详细的实验验证,发现结构扰动和嵌入扰动都对推荐性能作用很小。此外,采用数据增强,还存在着会增加扰动操作,这样会降低推荐模型的训练速度,以及降低训练后的推荐模型的稳定度的问题。因此,在舍弃数据增强的影响后,对比学习任务将变得更加简单,如何在简化后的对比学习任务下,与推荐系统结合从而提高推荐模型的推荐性能、训练速度和稳定性是本技术要解决的技术问题。
技术实现思路
1、本发明旨在解决现有技术中存在的技术问题,提供了一种基于对比学习联合优化的推荐方法、装置及设备。
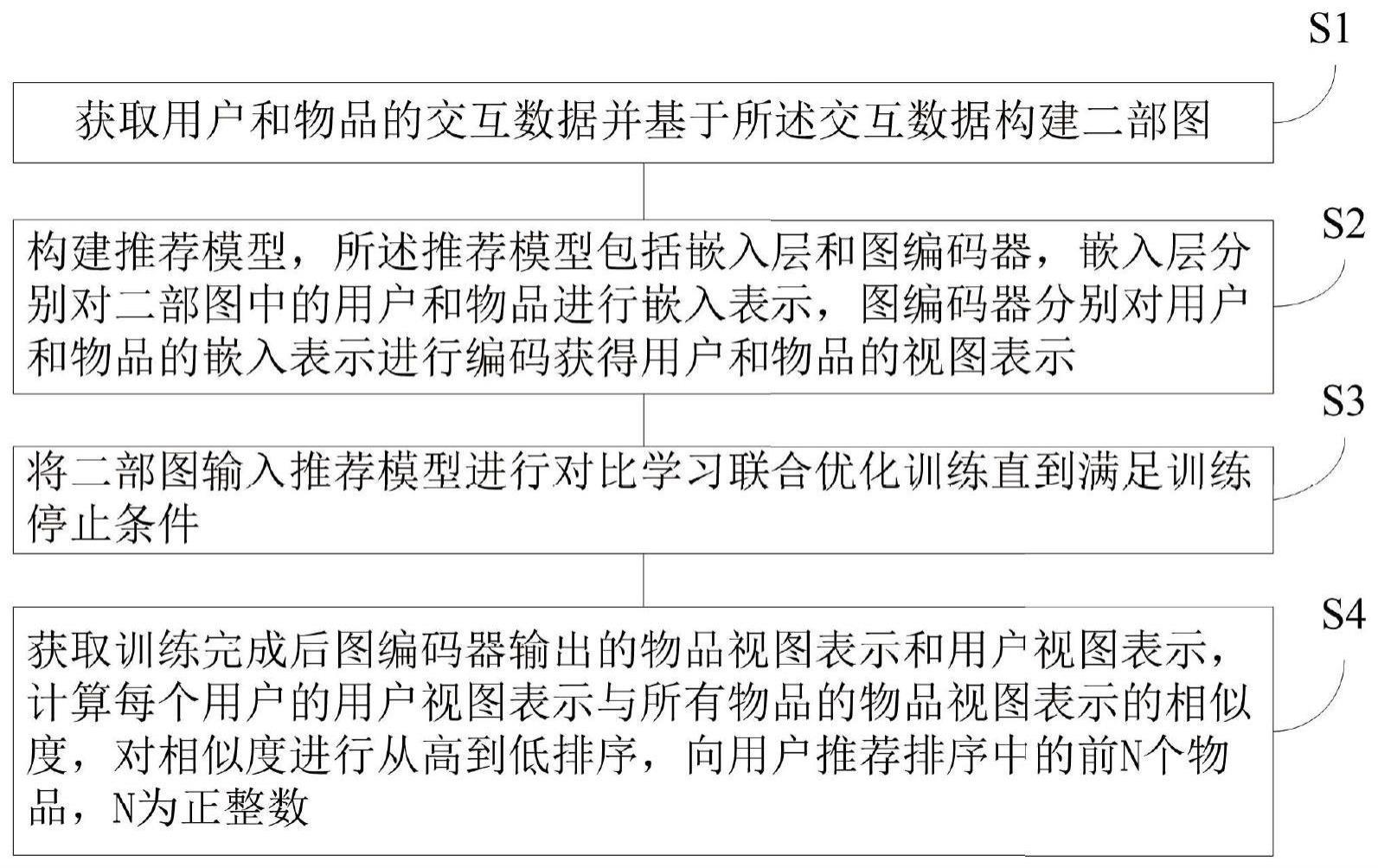
2、为了实现本发明的上述目的,根据本发明的第一个方面,本发明提供了一种基于对比学习联合优化的推荐方法,包括:获取用户和物品的交互数据并基于所述交互数据构建二部图;构建推荐模型,所述推荐模型包括嵌入层和图编码器,嵌入层分别对二部图中的用户和物品进行嵌入表示,图编码器分别对用户和物品的嵌入表示进行编码获得用户和物品的视图表示;将二部图输入推荐模型进行对比学习联合优化训练直到满足训练停止条件;获取训练完成后图编码器输出的物品视图表示和用户视图表示,计算每个用户的用户视图表示与所有物品的物品视图表示的相似度,对相似度进行从高到低排序,向用户推荐排序中的前n个物品,n为正整数。
3、上述技术方案:构建了一种精简的推荐模型结构,取消了传统图对比学习gcl中的数据增强部分,消除了对数据增强的需求,降低了训练计算成本,提高了训练效率,通过对比学习将影响推荐性能的关键因素对比学习损失和推荐损失融合为统一损失,提高了推荐模型的推荐精度和推荐稳定性,具有抑制推荐热门物品的能力。
4、在本发明的一种优选实施方式中,在推荐模型的每次训练中,按照预先构建的模型损失函数计算损失,基于所述损失调整推荐模型的参数;所述模型损失函数与负样本对的余弦相似度正相关,与正样本对的余弦相似度负相关。
5、上述技术方案:不再像传统的gcl那样,设置两个独立的对比学习损失函数和推荐损失函数,精简整合为一个损失函数,即模型损失函数,减小计算量的同事,还在于增大正样本对表征的相似性,减小负样本对表征的相似性,进而提高推荐精度。负样本对中两个样本的索引包含正样本对中用户索引和物品索引,与传统对比学习分别处理用户集合和物品集合相比,将批量训练批量b内的节点视为负样本,不区分节点类型,因此,该学习框架第可以以更加简洁的方式联合处理推荐任务中用户和物品的关系,对比学习任务中用户之间和物品之间的关系。
6、在本发明的一种优选实施方式中,所述模型损失函数为:
7、其中,b表示训练批量,u和i分别表示正样本对中的用户索引和物品索引,zu表示用户u的视图表示,zi表示用户i的视图表示,n和n′分别表示负样本对中两个样本的索引,λ表示损失权重系数,τ表示温度系数,zn表示用户n的视图表示,zn′表示用户n′的视图表示。
8、上述技术方案:采用了一种精简和统一的方法进行优化,将影响推荐性能的关键因素对比学习损失和推荐损失融合,将负样本对(用户-用户对、用户-物品对和物品-物品对)的损失纳入模型损失函数,大大加速了推荐模型的训练效率;并且模型损失函数中采用余弦相似度度量,余弦相似度度量对于模型损失函数具有巨大优势,它可以保持二部图中节点嵌入模长的集中分布,并实现去流行度的效果,n可以取值为正样本对中的索引u和i,与传统对比学习分别处理用户集合和物品集合相比,将训练批量b内的节点视为负样本,不区分节点类型。因此,该学习框架第可以以更加简洁的方式联合处理推荐任务中用户和物品的关系,对比学习任务中用户之间和物品之间的关系。
9、在本发明的一种优选实施方式中,所述模型损失函数还与用户视图表示的模长分布和物品视图表示的模长分布有关。
10、上述技术方案:发明人通过实验和分析发现,模型损失函数学习出来的用户嵌入和物品嵌入具有集中的嵌入模长分布,即嵌入的长度大多数集中分布在某一个值附近,从而具有不错的去流行度能力。在进一步探究嵌入模长分布和推荐模型的去流行度能力的相关性后,将节点的模长分布纳入模型损失函数进一步促进节点模型的集中分布,进而提高推荐模型的去流行度能力和稳定性。
11、在本发明的一种优选实施方式中,所述模型损失函数为:
12、
13、其中,b表示训练批量,u和i分别表示正样本对中的用户索引和物品索引,zu表示用户u的视图表示,zi表示用户i的视图表示,n和n′分别表示负样本对中两个样本的索引,α表示第一损失权重系数,τ表示温度系数,zn表示用户n的视图表示,zn′表示用户n′的视图表示,β表示第二损失权重系数,||zu||2表示所有用户视图表示的模长分布,||zi||2表示所有物品视图表示的模长分布,var(||zu||2)表示求取||zu||2的方差,var(||zi||2)表示求取||zi||2的方差。
14、上述技术方案:将节点的模长分布加入模型损失函数,直接显示地控制节点模长的分布集中程度,加强本技术推荐模型的模长分布优势,导致推荐热门物品的频率大大降低。
15、为了实现本发明的上述目的,根据本发明的第二个方面,本发明提供了一种物品推荐装置,用于实现本发明第一方面所述的基于对比学习联合优化的推荐方法,包括:获取模块,用于获取用户和物品的交互数据;建图模块,基于所述交互数据构建二部图;推荐模型构建模块,构建推荐模型,所述推荐模型包括嵌入层和图编码器,嵌入层分别对二部图中的用户和物品进行嵌入表示,图编码器分别对用户和物品的嵌入表示进行编码获得用户和物品的视图表示;对比学习联合优化训练模块,将二部图输入推荐模型进行对比学习联合优化训练直到满足训练停止条件;推荐模块,获取训练完成后图编码器输出的物品视图表示和用户视图表示,计算每个用户的用户视图表示与所有物品的物品视图表示的相似度,对相似度进行从高到低排序,向用户推荐排序中的前n个物品,n为正整数。
16、上述技术方案:具有本发明第一方面基于对比学习联合优化的推荐方法的有益技术效果。
17、为了实现本发明的上述目的,根据本发明的第三个方面,本发明提供了一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现本发明第一方面所述的基于对比学习联合优化的推荐方法。
18、上述技术方案:具有本发明第一方面基于对比学习联合优化的推荐方法的有益技术效果。
19、为了实现本发明的上述目的,根据本发明的第四个方面,本发明提供了一种电子设备,所述电子设备包括:至少一个处理器;以及,与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的计算机程序,所述计算机程序被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明第一方面所述的基于对比学习联合优化的推荐方法。
20、上述技术方案:具有本发明第一方面基于对比学习联合优化的推荐方法的有益技术效果。
- 还没有人留言评论。精彩留言会获得点赞!