一种基于大语言模型推理的医学疾病编码映射方法及装置与流程
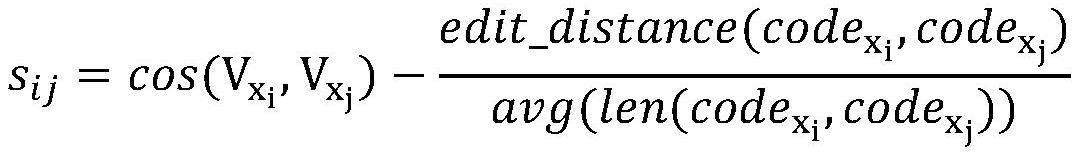
本发明属于神经网络编码映射,具体涉及一种基于大语言模型推理的医学疾病编码映射方法及装置。
背景技术:
1、在当今医疗健康信息化发展的背景下,医疗健康数据的收集和处理越来越受到关注。一方面,医疗健康数据是精准医疗、疾病预防和控制的重要基础,对于提高公众健康水平、降低医疗保健成本等方面具有重要意义。另一方面,由于医疗健康数据的特殊性和复杂性,其收集、处理和应用面临着巨大的挑战。
2、在这些挑战中,疾病编码映射问题尤为突出。在医疗健康领域,疾病编码是对疾病进行标准化分类和识别的重要工具,是精准医疗、疾病预防和控制、医疗服务质量评估等多个领域的关键技术基础。然而,目前在实际应用中存在一个严重问题,即各医院因地理、历史、管理等因素,会形成各自的疾病分类体系和编码方式,使得同一疾病在不同医院可能有不同的编码。这种情况严重影响了疾病编码的统一性和对疾病数据的有效管理。
3、例如,我国当前的标准疾病编码为“疾病分类代码国家临床版2.0”,它是经过精心设计和多年实践的标准化疾病分类系统。然而,很多医院仍然使用自己的分类体系和编码方式,这使得在管理众多医院的疾病数据时,面临着如何将不同医院的疾病编码对应到“疾病分类代码国家临床版2.0”的挑战。这种情况对于数据的统一处理和分析,以及更高层面的公共卫生决策等方面,都带来了极大的困扰。
4、因此,如何构建一种有效的疾病编码映射方法,将不同医院的疾病编码映射到统一的标准,是当前医疗健康数据管理的重要课题。
技术实现思路
1、为解决现有技术的不足,实现不同疾病编码统一的目的,本发明采用如下的技术方案:
2、一种基于模型推理的编码映射方法,包括如下步骤:
3、步骤s1:搭建标准文本编码的向量索引库,从标准文本中解析出文本描述及其对应的标准编码,并对文本描述向量化,构建向量索引库;
4、步骤s2:获取输入的文本信息,基于文本信息从向量库索引库中,召回与文本信息相关的一组文本描述及其对应的标准编码映射;
5、步骤s3:搭建基于神经网络模型的编码分析模块,将输入的文本信息与召回结果中的文本描述进行语义匹配,得到匹配的文本描述对应的标准编码。
6、进一步地,所述步骤s1中的文本描述向量化,是通过文本描述构建其正负样本对,将具有相同大类标准编码的文本描述作为正样本,非相同大类标准编码的文本描述作为负样本,基于对比学习微调预训练语言表征模型,以降低一对正样本生成向量的相似度,促使模型针对正样本拟合生成更相似的向量,增加一对正样本生成向量的相似度,促使模型针对负样本拟合生成更不相似的向量。
7、进一步地,所述样本的相似度,是基于样本对的编码距离与其编码长度平均值的比值,当样本对为一对正样本时,将该对正样本的余弦距离减去器对应的所述比值,当样本对为一对负样本时,将该对负样本的余弦距离加上其对应的所述比值。
8、进一步地,所述预训练语言表征模型,基于一对正样本和一个负样本的三元组,构建三元组损失函数:
9、l(xi,xj,xk)=max(0,sik-sij+margin)
10、其中,xi,xj表示一对正样本,xk表示负样本,sik表示一对负样本对应的所述比值,sij表示一对正样本对应的所述比值,margin表示超参数,用于拉开正负样本对之间的距离;
11、微调预训练语言表征模型,找出模型参数θ,以最小化所有样本对的损失函数的总和:
12、minθ∑(i,j,k)l(xi,xj,xk)
13、其中,θ表示预训练语言表征模型的参数。
14、进一步地,所述步骤s2中的召回包括倒排召回,召回步骤如下:
15、步骤s2.1.1:对向量索引库中的文本描述进行分词操作;
16、步骤s2.1.2:记录每个词项在所有文本描述中出现的位置,以此建立倒排索引;一方面倒排索引节省了存储空间,另一方面,倒排索引提高了对输入文本信息匹配的效率;
17、步骤s2.1.3:获取输入的文本信息,并提取其词项;
18、步骤s2.1.4:利用倒排索引,根据输入文本信息的词项,查找包含该词项的文本描述及其对应的标准编码,得到召回结果。倒排召回充分考虑了字词层面的相似性。
19、进一步地,所述步骤s1中的向量库,是基于文本描述生成哈希值,将哈希值作为唯一标识与文本描述对应的向量一起构建向量库;所述步骤s2.2中,倒排索引为一个哈希表,其键为词项,值是一个列表,列表中包含所有包含该此项的文本描述及其对应的标准编码;所述步骤s2.4中,在哈希表中查找输入文本信息的词项对应的文本描述及其标准编码。哈希表的而建立大大提高查找效率,同时也提高了数据传输的安全性,保障了用户隐私。
20、进一步地,所述步骤s2中的召回包括语义召回,召回步骤如下:
21、步骤s2.2.1:对输入的文本信息向量化,得到向量c;
22、步骤s2.2.2:从向量索引库中,查找与向量c距离最近的一组向量,并基于唯一标识,找到对应的文本描述及标准编码,得到召回结果。语义召回充分考虑了语义的相似性。
23、进一步地,所述步骤s3包括如下步骤:
24、步骤s3.1:整理和预处理训练数据,从标准文本中收集并标注一系列示例,示例为包含文本信息的提示字段及其对应的标准编码的答案字段,这些数据将被用于微调大语言模型,使其能够理解和解决我们的任务;
25、步骤s3.2:利用所述训练数据对模型进行微调,将训练数据中的提示字段作为输入,对应的答案字段作为输出;
26、步骤s3.3:模型推理;基于所述召回结果和输入的文本信息,构建提示字段,并输入微调后的模型,得到的答案字段即为映射的标准编码。
27、一种基于大语言模型推理的医学疾病编码映射方法,包括如下步骤:
28、步骤一:搭建标准疾病编码的向量索引库,从标准疾病编码文件中解析出疾病描述及其对应标准编码的键值对,并对疾病描述向量化;
29、步骤二:获取输入的疾病名称,基于疾病名称从向量库索引库中,召回与疾病名称相关的一组疾病描述及其对应的标准疾病编码映射;
30、步骤三:搭建基于大语言模型的编码分析模块,将输入的疾病名称与召回结果中的疾病描述进行语义匹配,得到匹配的疾病描述对应的标准疾病编码。
31、一种基于大语言模型推理的医学疾病编码映射装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现所述的一种基于大语言模型推理的医学疾病编码映射方法。
32、本发明的优势和有益效果在于:
33、本发明的一种基于大语言模型推理的医学疾病编码映射方法及装置,通过构建向量化的标准疾病编码库,在兼顾疾病信息的字词和语义,进行标准编码的匹配,使得采用不同编码方式的医院,也能够基于疾病信息匹配到统一的标准编码上,以便统一疾病编码,提高疾病数据的有效性,提高疾病标准化分类和识别的效率,同时,大幅减轻人工对齐的时间成本消耗,并且更加精确。
- 还没有人留言评论。精彩留言会获得点赞!