一种增强大语言模型问答特定领域问题能力的方法及系统与流程
本技术涉及药物筛选,尤其涉及一种增强大语言模型问答特定领域问题能力的方法及系统。
背景技术:
1、g蛋白偶联受体(gpcrs)超家族是人类和其他生物中最重要的蛋白质家族之一,包含800多种七跨膜(7tm)蛋白质。gpcrs的主要功能是通过检测信号分子(如5-羟色胺、乙酰胆碱等)并通过构象变化激活细胞内反应,进一步将信号从细胞外传递到细胞内。由于它们的重要功能,gpcrs已成为研究人员最受欢迎的药物靶点之一,约有40%的上市药物以这些受体为靶点。然而,由于gpcrs形成的信号网络复杂,设计针对gpcrs的药物并不容易。gpcrs的细胞外和跨膜结构域可以结合各种信号分子,以感知外部环境的变化。其下游合作伙伴包括g蛋白和g蛋白耦合受体激酶(grks)等,它们结合到gpcrs的细胞内结构域。根据gα亚单位的序列,g蛋白可以进一步分为gs、gi/o、gq/11和g12/13四类。因此,阐明gpcr信号传导网络将有助于理解它们的功能,并促进药物的发现研究。
2、近年来,大型语言模型(llms),也称为预训练语言模型(plms),已经在自然语言处理领域取得重大突破。例如bert、gpt-3和chatgpt等模型显著提高了nlp的能力。然而,llms也存在一些局限性,包括生成偏见或误导性内容,引发人们对其在各种应用中使用的担忧。此外,像chatgpt这样的大型语言模型在回答与gpcrs相关的问题时常常提供不正确或不足的领域知识。
技术实现思路
1、为了解决现有技术中的不足,本技术旨在提供一种增强大语言模型问答特定领域问题能力的方法及系统。本技术利用知识图谱可以准确查询信息的能力,将用户在知识图谱中查询到的信息作为提示语句,增强大语言模型在g蛋白偶联受体领域问答能力。
2、为实现上述目的,本技术采取的技术方案为:
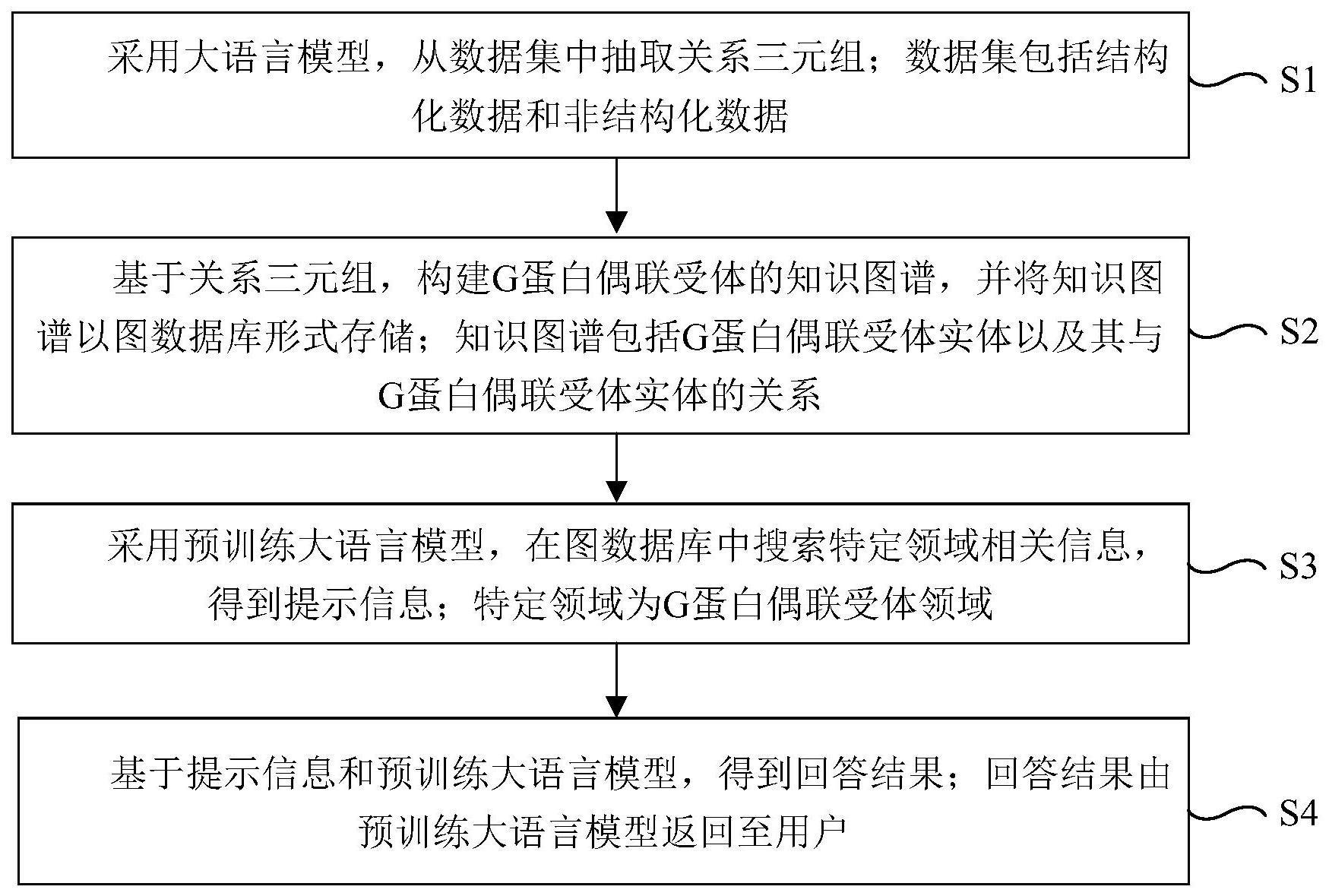
3、第一方面,本技术提供一种增强大语言模型问答特定领域问题能力的方法,包括以下步骤:首先,采用大语言模型,从数据集中抽取关系三元组;数据集包括结构化数据和非结构化数据;然后,基于关系三元组,构建g蛋白偶联受体的知识图谱,并将知识图谱以图数据库形式存储;知识图谱包括g蛋白偶联受体实体以及其与g蛋白偶联受体实体的关系;接下来,采用预训练大语言模型,在图数据库中搜索特定领域相关信息,得到提示信息;特定领域为g蛋白偶联受体领域;最后,基于提示信息和预训练大语言模型,得到回答结果;回答结果由预训练大语言模型返回至用户。
4、在一些示例性实施例中,采用大语言模型,从数据集中抽取关系三元组,包括:采用大语言模型,从所述数据集的非结构化数据中抽取结构化关系三元组,并将所述数据集的结构化数据中存储的与g蛋白偶联受体相关的信息转换为关系三元组;其中,非结构化数据、所述结构化数据分别通过从非结构的文本、结构化数据库中提取数据得到;非结构的文本包括期刊、专利、网页、书籍中的段落,以及图片中的文字信息;结构化数据库包括g蛋白偶联受体特异的数据库和非g蛋白偶联受体特异的数据库;其中,g蛋白偶联受体特异的数据库是专为存储g蛋白偶联受体信息构建的数据库;非g蛋白偶联受体特异的数据库是并非为存储g蛋白偶联受体信息构建的数据库。
5、在一些示例性实施例中,结构化数据包括:uniprot编码、chembl编码、受体名称、分类信息、下游信使、相关疾病、内源性配体以及上市药物;关系三元组包括g蛋白偶联受体在功能、信号通路、配体、疾病以及属性方面的性质。
6、在一些示例性实施例中,所述大语言模型、所述预训练大语言模型均为经过设计与训练、且与人类反馈充分对齐的语言模型;大语言模型与所述预训练大语言模型相同,或所述大语言模型与所述预训练大语言模型不同;大语言模型为开源大语言模型、非开源大语言模型中的一种或多种。
7、在一些示例性实施例中,知识图谱通过neo4j软件以图数据库的形式存储。
8、在一些示例性实施例中,大语言模型、所述预训练大语言模型均采用生成式预训练变换器chatgpt。
9、在一些示例性实施例中,采用预训练大语言模型,通过cypher语言在所述图数据库中直接查询特定领域相关信息,得到提示信息;或通过python、java编程语言与所述图数据库进行交互;提示信息为所述知识图谱根据搜索的内容返回的信息。
10、第二方面,本技术还提供了一种增强大语言模型问答特定领域问题能力的系统,包括依次连接的数据获取模块、知识图谱构建模块以及交互模块;数据获取模块用于采用大语言模型,从数据集中抽取关系三元组;数据集包括结构化数据和非结构化数据;知识图谱构建模块用于根据所述关系三元组,构建g蛋白偶联受体的知识图谱,并将所述知识图谱以图数据库形式存储;所述知识图谱包括g蛋白偶联受体实体以及其与g蛋白偶联受体实体的关系;交互模块用于采用预训练大语言模型,在所述图数据库中搜索特定领域相关信息,得到提示信息;所述特定领域为g蛋白偶联受体领域;并基于所述提示信息和预训练大语言模型,得到回答结果;所述回答结果由所述预训练大语言模型返回至用户。
11、在一些示例性实施例中,所述数据获取模块包括关系三元组抽取单元以及关系三元组转换单元;其中,关系三元组抽取单元用于采用大语言模型,从所述数据集的非结构化数据中抽取结构化关系三元组;关系三元组转换单元用于采用大语言模型,将所述数据集的结构化数据中存储的与g蛋白偶联受体相关的信息转换为关系三元组;其中,非结构化数据、所述结构化数据分别通过从非结构的文本、结构化数据库中提取数据得到;非结构的文本包括期刊、专利、网页、书籍中的段落,以及图片中的文字信息;结构化数据库包括g蛋白偶联受体特异的数据库和非g蛋白偶联受体特异的数据库;其中,g蛋白偶联受体特异的数据库是专为存储g蛋白偶联受体信息构建的数据库;非g蛋白偶联受体特异的数据库是并非为存储g蛋白偶联受体信息构建的数据库。
12、在一些示例性实施例中,采用大语言模型,从结构化数据库中提取数据得到结构化数据;结构化数据包括:uniprot编码、chembl编码、受体名称、分类信息、下游信使、相关疾病、内源性配体以及上市药物。
13、上述技术方案具有如下优点或者有益效果:
14、本技术提供了一种增强大语言模型问答特定领域问题能力的方法及系统,该方法包括以下步骤:首先,采用大语言模型,从数据集中抽取关系三元组;数据集包括结构化数据和非结构化数据;然后,基于关系三元组,构建g蛋白偶联受体的知识图谱,并将知识图谱以图数据库形式存储;知识图谱包括g蛋白偶联受体实体以及其与g蛋白偶联受体实体的关系;接下来,采用预训练大语言模型,在图数据库中搜索特定领域相关信息,得到提示信息;特定领域为g蛋白偶联受体领域;最后,基于提示信息和预训练大语言模型,得到回答结果;回答结果由预训练大语言模型返回至用户。
15、本技术针对“现有的大语言模型在回答与gpcrs相关的问题时常常提供不正确或不足的领域知识”的技术问题,提供一种增强大语言模型问答特定领域问题能力的方法及系统,该方法首先利用大语言模型,在非结构数据抽取结构化关系三元组,以及将结构数据中存储的gpcrs的相关信息转换关系三元组,并将二者结合用于知识图谱构建,然后将构建好的知识图谱存储在图数据库中。在生产环境中,用户提出的问题用来在知识图谱中搜索相关知识,并且将这些知识作为提示语句,增强大语言模型在回答g蛋白偶联受体领域问答能力的方法。本技术充分发挥了知识图谱存储和查询准确信息的能力、大语言模型文本总结和推理的优势,以及大语言模型充分与人类对齐的特点,生成准确并且可以被人类理解和阅读的答案。本技术通过构建了高质量gpcrs领域知识图谱,知识图谱赋予大语言模型模型准确、实时的gpcrs领域知识,增强其回答g蛋白偶联受体领域问题的能力产生专业领域准确回复,克服了大语言模型在gpcrs领域生成错误答案的缺点,有利于用户迅速了解特定的gpcrs。
- 还没有人留言评论。精彩留言会获得点赞!