一种基于上下文聚合和边界生成的时序行为检测方法
本发明属于计算机视觉和模式识别,具体涉及一种基于上下文聚合和边界生成的时序行为检测方法。
背景技术:
1、近年来,随着科技与互联网的发展,人们通过视频传递信息变得越来越普遍,通过手机、电脑、监控都能够方便快速的录制视频,使得视频的数量呈现出爆炸式的增长趋势。因此,如何从海量视频中准确挖掘到所需要的信息成为当前视频理解的重要问题。时序行为检测任务的目的是在原始视频中定位出人们感兴趣的行为时间边界,并对该动作进行分类。该项技术可以广泛应用于视频监控、视频搜索与检索、自动驾驶、人机交互、视频内容推荐等,具有极大的研究意义和极高的实用价值。在社会安全方面,时序行为检测技术可以自动检测异常行为片段,使得能够及时发现并制止,减少人员伤亡和社会财产损失,大大减少警察工作量并提高效率。在视频检索方面,时序行为检测技术可以从海量视频中找到特定行为,智能生成精彩内容集锦,提高用户体验。此外,在互联网上每天都有海量视频被上传或转发,时序行为检测可以自动检索出暴力视频并及时删除,恢复和净化网络环境,避免未成年人被误导。
2、时序行为检测方法分为两个步骤:首先生成时序行为提名,然后再对提名进行分类。目前,现阶段主流的时序行为提名生成方法主要有两类:采用“自上而下”的方式和“自下而上”的方式。
3、其中,“自上而下”的方式是通过使用滑动窗口或均匀分布的锚点密集的生成大量的行为提名,但是,该方式由于固定长度段,在处理具有不同持续时间的行为实例时存在限制,缺乏灵活性。“自下而上”的方式是指基于边界的方法,首先对视频序列中每个时间位置的潜在行为概率进行评估,然后将其匹配以形成候选提名。但是该方式存在的问题是:1、基于局部信息提取时序特征,缺乏对全局和长期时序关系的建模以获取覆盖不同持续时间的行为实例特征。2、它主要依赖边界周围的浅层局部特征来预测行为边界,忽略了深层语义特征的捕获,导致生成的行为边界不够精确,限制了性能的提升。3、它在置信度评估中未考虑提名与提名之间的关系,无法获得足够的语义补充,从而导致性能低。
技术实现思路
1、本发明针对现有技术没有充分利用时序上下文特征,缺乏对全局和长期时序关系的建模,边界检测中缺乏深层语义特征捕获以及置信度评估中未考虑提名与提名之间关系,导致行为检测性能不够理想的问题,本发明提供了一种基于上下文聚合和边界生成的时序行为检测方法。
2、为实现上述目的,本发明的技术方案如下:一种基于上下文聚合和边界生成的时序行为检测方法,包括以下步骤:
3、步骤1、数据准备:数据集来源于通用时序行为检测数据集activitynet1.3和thumos14数据集;
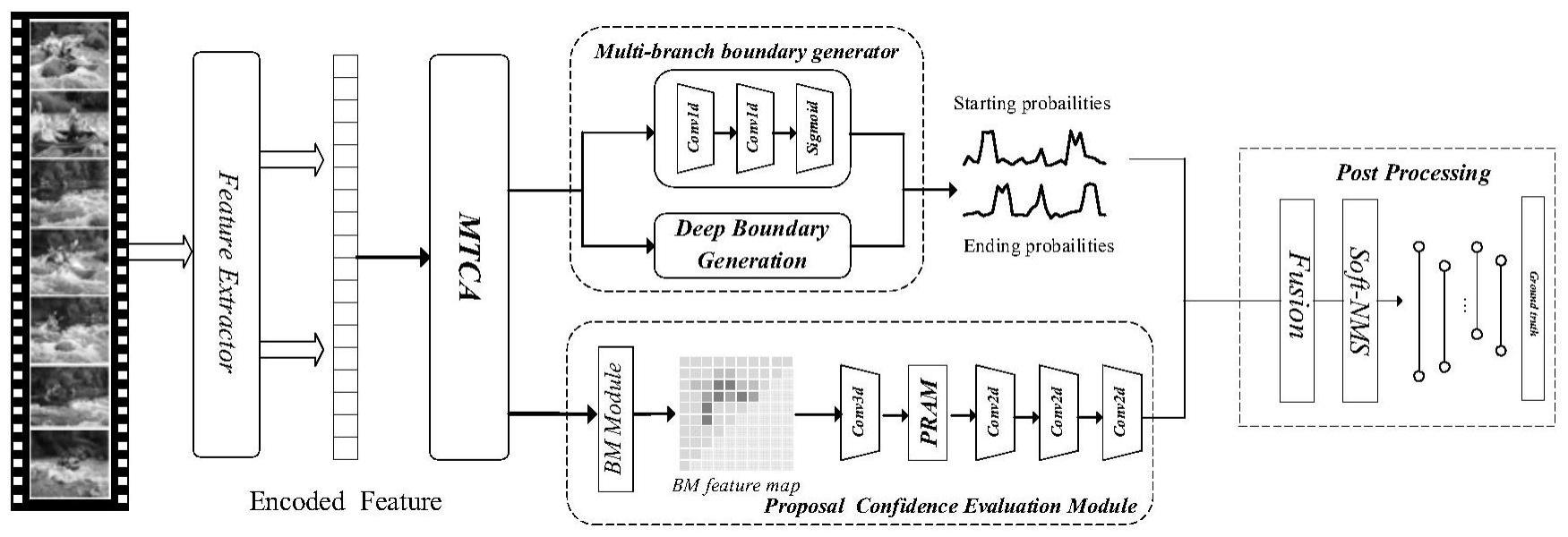
4、步骤2、特征编码:采用two-stream网络提取输入视频的时空特征,生成rgb特征和光流特征,作为视频特征序列f;
5、步骤3、视频特征序列f输入到多路径时序上下文特征聚合模块,分别通过:
6、时间全局相关结构在整个视频输入特征上构建丰富的全局上下文信息,生成时间全局特征a;
7、长范围时间特征相关结构考虑长距离上下文特征的聚合,生成长范围时序特征b;
8、局部特征结构,通过卷积运算,生成局部特征c;
9、最后将3个特征进行融合,得到多路径时序上下文特征d;
10、步骤4、将多路径时序上下文特征d输入到多分支边界生成器中,分别通过多分支边界生成器中的浅层边界生成器和深层边界生成器生成两组边界概率序列p′s,p′e和p″s,p″e,融合生成最终的提名边界概率ps和pe;
11、步骤5、提名评估:将步骤3中多路径时序上下文特征d输入到提名评估模块中,生成提名匹配置信图,为密集分布的提名框提供置信度分数;
12、步骤6、后处理:融合步骤4生成的提名边界概率ps、pe和步骤5生成的提名匹配置信图,生成最终置信度分数,并基于最终的置信度分数采用soft-nms算法抑制冗余提名。
13、进一步的,上述步骤3中:
14、
15、ms(fc)=σ(f([avgpool(fc);maxpool(fc)])) (2)
16、
17、b=activation(fdilated-causal(f)+conv1d(f)) (4)
18、c=conv(conv(f)) (5)
19、进一步的,上述步骤4,具体为:浅层边界生成器由两个conv1d卷积层组成,并使用sigmoid函数激活输出特征以生成开始点的概率p′s和结束点概率p′e;深层边界生成器设计为编码器-解码器u型结构,通过组合多尺度特征来生成精确的动作边界,并通过一系列的密集卷积块以跳跃连接方式融合相同尺度的编码器和解码器特征,最终使用sigmoid函数激活输出特征以生成开始点的概率p″s″和结束点概率p″e″,融合生成最终的提名边界概率ps和pe的公式为(7):
20、
21、进一步的,上述步骤5中,对于输入的多路径时序上下文特征d,首先将其转化为边界匹配特征图,然后对其进行采样操作以获得提名匹配特征图p,之后通过提名评估中的提名关系感知模块融合相邻提名特征,最终采用sigmoid函数得到提名匹配置信度图,分别用来分类和回归。
22、进一步的,提名关系感知模块是一种具有压缩激励块的残差模块变体,对于输入的特征图p首先通过输入特征层进行全局平均池化操作,然后,使用两个全连接层捕获通道之间的关系,在两个全连接之间设置gelu层,之后执行sigmoid以将值固定在[0,1],获得输入特征层的每个通道的权重值,最后与输入特征图p相叠加得到最后的输出特征图。
23、与现有技术相比,本发明的有益效果:
24、1、本发明设计了一个多路径时序上下文特征聚合模块,用于有效的聚合长期和短期时间上下文信息,从而增强行为事件的上下文表示。具体为:1)由于时间全局信息与行为的类别有关,所以适应于行为分类的特征应该是具有判别性的,因此设计了一个时间全局相关结构,通过在整个视频输入特征上构建丰富的全局上下文信息,生成全局特征;2)对于长视频来说,长期的时间建模必不可少。为了使边界位置能够专注于聚合其所属的行为实例信息,并且同时考虑到长距离上下文的聚合,设计了一个长范围时间特征相关结构,用来捕获视频的长距离上下文,生成长范围时序特征;3)对于检测时间较短的视频来说,局部信息更为有效,设计了一个局部特征结构,通过卷积运算,生成局部特征。最终,将三种特征相结合,实现了对于持续时间长和持续时间短的视频都能有效检测的目的。
25、2、本发明设计了一个多分支时间边界检测器,由浅层和深层时间边界检测器组成,浅层时间边界生成器由卷积层组成,将深层时间边界生成器设计为u型结构。融入深层时间边界生成器后能够解决浅层时间边界生成器仅关注局部突变,而导致生成的行为边界具有较高召回率,但是精度不高的问题。同时,利用两个时间边界检测器之间的互补关系优化预测结果,判断两组开始关键点和结束关键点是否同时处于阈值或峰值处,将起点和终点配对以生成提名,从而实现对行为边界的高召回率和高精度捕捉。
26、3、本发明设计的深层时间边界生成器,是一个编码器—解码器的u型结构,包含编码器(下采样)、解码器(上采样)和跳跃连接。由于时间卷积层平均的处理每个通道中的特征,所以并非编码器所获得的所有特征都对边界概率预测有效,因此,在编码器中的每个时间卷积层后连接了一个自适应通道注意力模块,以增强在当前时间尺度上捕获关键特征的能力。此外,在解码器过程中,会丢失部分信息,为了解决此问题,我们连接了解码器的多尺度特征,以捕获细粒度细节和粗粒度语义,有效的提取更多信息,从而生成精确的行为边界。
27、4、本发明设计了一个提名关系感知模块,通过全局相关性进行提名关系建模,聚合相邻提名的上下文信息,同时区分稀疏提名之间的语义信息,有效地解决了现有方法通过卷积运算融合相邻提名,而导致融合后的提名缺乏区分性和丰富性的问题,增强了提名上下文的表达性和鲁棒性。
28、5、在两个通用时序行为提名生成和检测的大型数据集:activitynet1.3和thumos14数据集上进行了综合实验,本发明有效的提高了时序行为提名生成的性能,可以生成具有高精度和召回率的行为提名,进一步结合现有的动作分类器,也可以实现较好的时序行为检测性能,与目前先进的方法相比具有优越性。
- 还没有人留言评论。精彩留言会获得点赞!