一种基于点标签学习的OCT图像积液分割方法
本发明涉及计算机辅助病理诊断,尤其涉及一种基于深度学习的弱监督领域的oct图像积液分割的方法。
背景技术:
1、视网膜积液可以根据积聚的位置分为三种类型:视网膜内积液,视网膜下积液和色素上皮脱离。这些液体是年龄相关性黄斑变性和视网膜静脉阻塞这两种严重眼病的重要生物标志物。眼科医生可以通过观察患者视网膜oct图像中积液的种类和面积的大小来判断病变,但无法准确量化积液并据此制定治疗方案。因此,一种能够自动分割积液区域的算法对于临床诊断尤为重要。早期的oct积液分割使用传统技术,它们依赖于手工设计的特征。然而,这些传统方法往往容易受到图像质量变化的影响,需要广泛的领域知识,并且缺乏泛化能力。相比于传统分割方法需要依赖于精心制作的手工特征,卷积神经网络具有自动学习和提取图像特征的能力。然而,基于卷积神经网络的方法需要大量数据,并且医学图像中手动标注数据是一个高度专业化且耗时的过程。在实践中,从医学专家那里获取大量标记清晰的数据往往是困难的,这使得训练准确、稳定的卷积神经网络模型用于医学图像分割具有挑战性。如果没有足够的清晰标记的像素级注释,基于卷积神经网络的数据匮乏的分割方法往往难以拟合,从而导致性能下降。一种可靠的解决办法是使用弱标签,而如何利用这些不完整的弱标记信息进行训练,并取得良好的预测结果对辅助诊断显得尤为重要。
技术实现思路
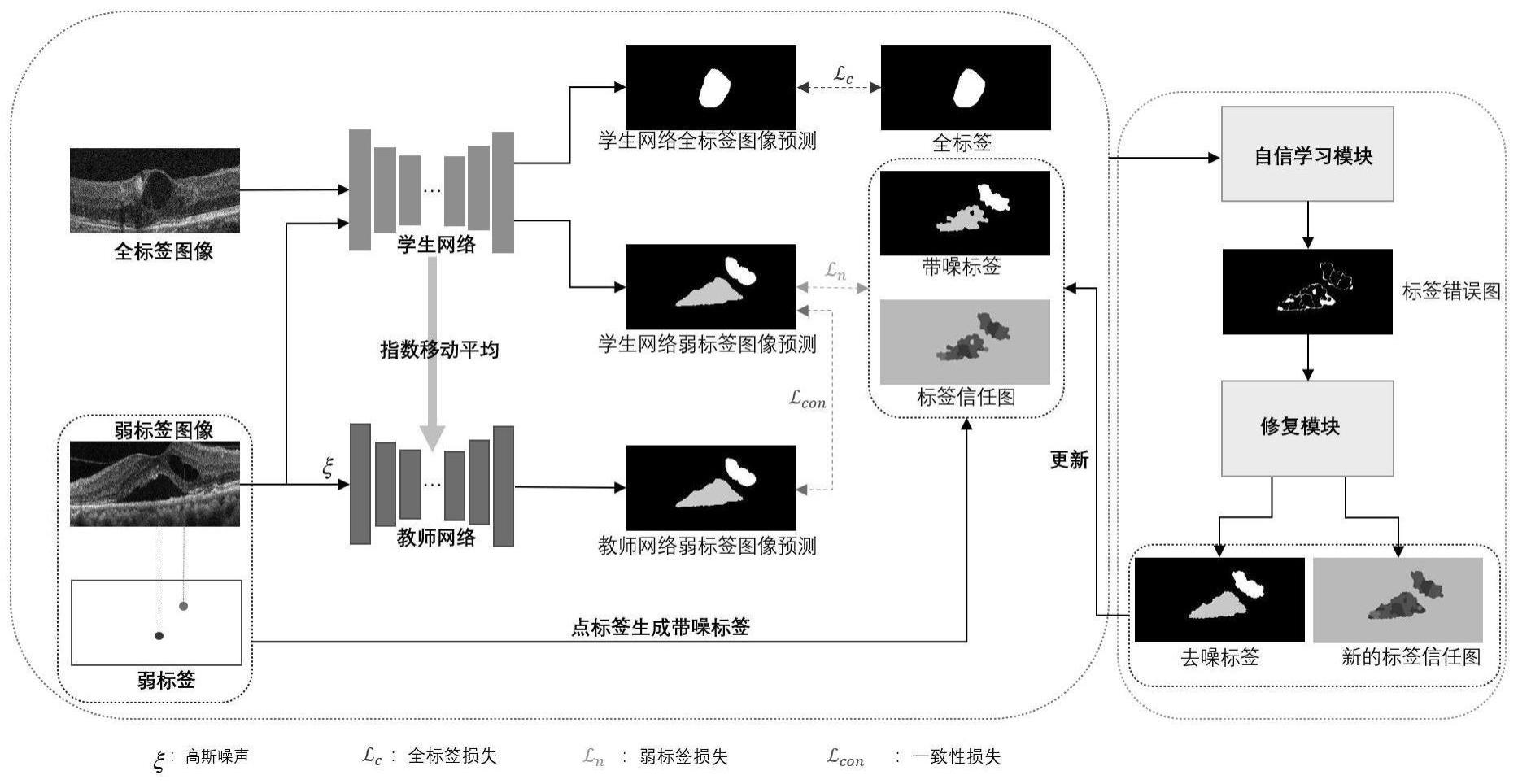
1、本发明针对现有方法的不足,提供一种基于点标签学习的oct图像积液分割方法。本发明主要由以下四部分构成分别是:通过超像素(achanta r,shaji a,smith k,etal.slic superpixels compared to state-of-the-art superpixel methods[j].ieeetransactions on pattern analysis and machine intelligence,2012,34(11):2274-2282.)算法,对点标注数据生成带噪标签;将少量有全标注数据的oct图像和大量有带噪标签的oct图像输入师生架构网络,训练得到带噪网络;采用自信学习(northcutt c,jiangl,chuang i.confident learning:estimating uncertainty in dataset labels[j].journal of artificial intelligence research,2021,70:1373-1411.)模块识别噪声和标签修复模块对带噪标签进行细化得到去噪标签;将少量有全标注数据的图像和大量有去噪标签的图像输入师生架构网络,训练得到去噪网络。这种两阶段的去噪方法可以使得最终的模型尽量避免学习到带噪标签中的噪声。本发明的一种基于点标签学习的oct图像分割方法通过以下技术特征实现的:
2、本发明的一种基于点标签学习的oct图像积液分割方法,具体包括以下步骤:
3、步骤1,构建oct图像积液分割数据集,并进行预处理;
4、从医院获取不同时期不同患者的数次oct检查采集的数据,构成oct图像积液分割数据集的原始oct图像。对所有的oct图像做全标注和点标注构建oct图像积液分割数据集。
5、步骤2,基于点标注生成带噪标签;
6、步骤3,构建oct图像积液分割模型,使用少量全标签数据和带噪标签数据训练师生架构网络,得到初步训练后的师生架构网络;
7、所述的oct图像积液分割模型包括师生架构网络、自信学习模块和标签修复模块。所述的师生架构网络包括学生网络、教师网络,学生网络通过梯度下降训练,教师网络则是通过学生网络参数迭代。学生网络和教师网络均使用unet作为骨干网络。
8、所述的自信学习模块通过对带噪标签进行置信度估计从而检测标签错误。标签修复模块将错误标签替换为预测的伪标签从而细化带噪标签。
9、步骤4,通过自信学习模块找到带噪标签的错误,通过标签修复模块对找到带噪标签的错误进行修复得到去噪标签;
10、步骤5,通过全标签数据和去噪标签数据对初步训练后的师生架构网络进行进一步训练,得到最终去噪网络。最后通过最终去噪网络完成oct图像积液分割。
11、进一步的,步骤1具体方法如下:
12、从医院获取包括不同时期不同患者的数次oct检查的oct图像。从每次oct检查获得的oct图像中选择包含丰富积液的oct图像构成oct图像积液分割数据集的原始oct图像。将所有图像中心裁剪,分辨率保存为600x250,输入网络时,所有的图像大小调整为256x128。同一患者的数据只能用于训练或测试。
13、对所有的oct图像做全标注和点标注构建oct图像积液分割数据集的掩膜。所述的全标注就是对积液区域做逐像素标记。点标注是指对于积液部分,用点标记积液(视网膜内积液和视网膜下积液)的中心,用线(多个点)标记色素上皮脱离的底部。
14、进一步的,所述的从点标注生成带噪标签,首先将原始oct图像超像素化得到超像素图。通过计算每个超像素块是否包含标注的点标签生成超像素标签。遍历每一个超像素标签中不为背景类别的超像素块作为初始超像素块定义为计算初始超像素块与其一个邻域超像素块定义为计算这两者包含的每个像素值对应像素点的个数:
15、
16、
17、其中和表示初始超像素块和邻域超像素块包含的每个像素值对应像素点的个数,符号表示正确返回1错误则返回0,j:sj=ms和j:sj=ns表示初始超像素块和邻域超像素块在原始图像中对应的像素点。随后,通过和计算两者余弦相似度:
18、
19、倘若余弦相似度大于阈值,将初始超像素块的标签赋值给邻域超像素块,并将该邻域超像素块的邻域超像素块也视为初始超像素块的邻域超像素块,直到所有的邻域超像素块与初始超像素块的余弦相似度都小于阈值。遍历每一个超像素标签中不为背景类别的超像素块作为初始超像素块。所有不为背景的初始超像素块处理完毕后,将超像素标签转化为带噪标签。并且生成额外像素级标签权重图,初始的标签权重图的值设置为0.5,随后把值1.0分配给初始超像素块对应的像素点,当余弦相似度大于阈值时更新信任值,每相差两个超像素块的实际距离就在1的基础上减少0.1分配给邻域超像素块对应的像素点。
20、进一步的,使用少量全标签数据和带噪标签数据训练师生架构网络,具体方法如下:
21、所述的师生架构的学生网络和教师网络结构基于unet网络。网络的输入数据包含两部分:10%全标签数据和90%的带噪标签数据;全标签数据输入师生架构的学生网络,带噪标签数据输入学生网络和教师网络;
22、全标注数据的交叉熵损失:
23、
24、其中表示全标签的学生网络的预测概率图,表示对应的全标签,n表示一张oct图像总的像素个数,lce表示交叉熵损失;
25、点标签损失受约束的交叉熵损失:
26、
27、其中表示带噪标签原始图像输入学生网络得到的预测概率图,表示对应的带噪标签;
28、一致性损失:
29、
30、其中表示带噪标签原始图像输入教师网络得到的预测概率图,lmse表示均方误差损失。
31、总的损失函数为三者的相加:
32、
33、其中α,β,λ为损失函数的超参数。
34、控制学生网络并沿着随机梯度下降的方向更新,教师网络通过指数移动平均更新参数,当训练迭代4000次终止保存模型参数并且取学生网络作为带噪网络。
35、进一步地,步骤4具体实现方法如下:
36、首先将带噪标签的原始oct图像输入带噪网络得到预测概率图根据预测概率图计算得到预测标签:
37、
38、其中c表示总的分割类别,n表示输出的维度。将预测概率图和带噪标签输入自信学习模块得到估算误差图xerr。然后根据估算误差图xerr用于标签修复模块得到修复后的去噪标签
39、
40、其中表示带噪标签,表示去噪标签。并且得到修改后的标签权重图
41、
42、其中ui表示初始的标签权重图,δ是权重值设置为1.0。
43、本发明相比于现有技术而言,具有以下有益效果:
44、1)本发明的模型采用大量的点标注数据进行模型训练。节省了人力标注的成本和时间消耗。
45、2)本发明采用点标签学习方法用于oct图像积液分割,其中带噪标签由点标注生成,并且额外生成标签权重图来表示带噪标签的信任度,约束网络过度学习噪声。
46、3)本发明采用两阶段去噪方法并结合了师生架构和自信学习模块可以从小部分全标注数据和大部分点标注数据学习oct图像积液分割。
- 还没有人留言评论。精彩留言会获得点赞!