一种多尺度高维特征分析无监督学习视频异常检测方法
本发明涉及异常检测,尤其是涉及一种多尺度高维特征分析无监督学习视频异常检测方法。
背景技术:
1、视频异常检测是指在视频中检测异常事件的任务这项任务在学术界有着深远的研究目标,在工业界具有重要的应用价值。由于异常事件在不同场景下的定义方式不同,所有不符合正常逻辑行为的事件都可以被视为异常行为。并且处理视频的方法困难且复杂,所以视频异常检测任务是极具挑战性的。该任务无法收集到所有包含异常事件的准确定义数据集,因此无法通过标准的分类方法来解决这个问题。现有的工作研究通常使用训练正常数据模型来学习正常行为的分布,在测试期间模型比对给定测试样本与训练样本的分布差距对异常进行判定分类。
2、近年来,基于卷积神经网络的方法广泛应用于视频异常检测的auto-encoder(ae)模型中,这主要归功于卷积操作,卷积操作以分层方式捕捉局部特征作为有效的图像表示,尽管在局部特征提取方面具有优势,但卷积神经网络难以捕捉视频的全局特征,例如视频连续帧之间的时空关系特征,视频正样本数据之间的特征依赖等。随着基于自注意力机制的vision transformer架构在计算机视觉领域有了很好的表现性能,越来越多的方法将自注意力方法应用在图像分类等视觉领域。借助于自注意力机制和多层感知器结构,visiontransformer展现出复杂的空间序列关系和长距离特征依赖,从而构造出全局表示特征,与卷积神经网络相比,vision transformer对于归纳偏置的限制较少,虽然卷积核是为了捕捉短距离时空信息而设计的,但它们无法对超出感受野的依赖关系进行建模。虽然卷积的深度堆叠操作可以扩张感受野,但这些方法在通过聚合较短范围的手段来捕捉远程依赖关系方面存在一定的局限性。相反,通过直接比对所有时空位置的特征信息,应用注意力机制来捕捉全局的依赖关系,就可以超出传统卷积滤波方法的感受范围。但是,visiontransformer忽略了局部特征细节,导致transformer在处理帧序列这种图像类型方面无法对视频中的弱变化作出敏感特征关注。
技术实现思路
1、本发明的目的是提供一种多尺度高维特征分析无监督学习视频异常检测方法,提高视频帧预测的精度、增强了训练正常样本特征信息的多样性,提高了视频异常检测的异常分数评估。
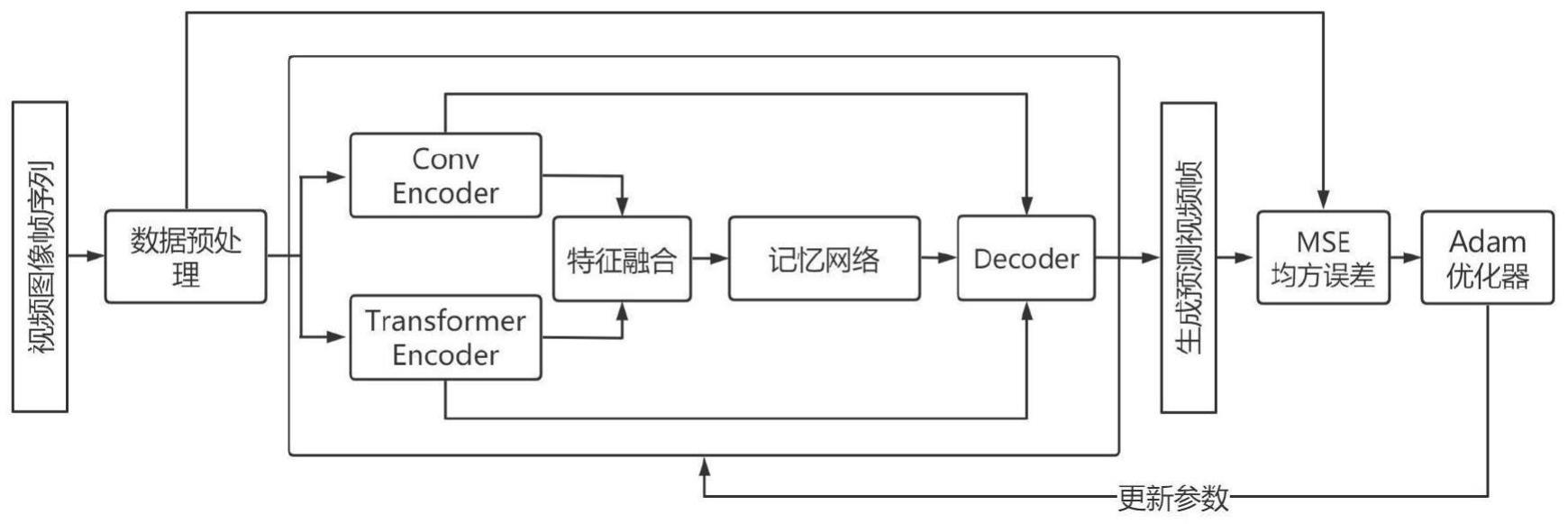
2、为实现上述目的,本发明提供了一种多尺度高维特征分析无监督学习视频异常检测方法,包括以下步骤:
3、步骤s1:数据预处理,分割测试集与训练集视频为图像帧;
4、步骤s2:根据步骤s1得到的训练数据集,将训练集数据进行批处理传入自编码器模型中,每组数据中包含5张连续视频帧;
5、步骤s3:将数据分别传入卷积通道和transformer通道编码器(encoder),将两者特征进行融合作为表现特征和时空特征;
6、步骤s4:将特征输入记忆网络(memory network)中,通过softmax函数计算对步骤s3得到的特征进行正态样本特征记忆存储及更新,得到多样化的正常事件数据;
7、步骤s5:将更新存储后的视频特征传入解码器(decoder)中,生成预测帧数据;
8、步骤s6:计算步骤s5得到的生成预测帧与真实之间的均方误差(mse),进行反向传播,更新网络参数,得到训练好的自编码器模型;
9、步骤s7:通过验证数据集对自编码器模型进行测试;
10、步骤s8:计算基于验证数据集生成的预测帧与真实预测帧之间的均方误差(mse),求得所有组数据的均方误差(mse)后求均值,得到训练数据集的mse误差;
11、步骤s9:重复步骤s2至步骤s8,直至步骤s8得到的均方误差(mse)下降幅度减小;
12、步骤s10:将训练任务中的网络参数模型加载至测试任务中,并将测试数据集数据传入模型中进行异常分数计算,最后通过计算roc曲线下面积auc得到评估分数。
13、优选的,步骤s2具体包括:
14、步骤s21:根据需求设定每组图像尺寸,数据序列长度,对应每组图像宽高数据和序列步长;
15、步骤s22:采用滑动窗口机制进行分组,窗口长度为序列长度,每次窗口移动一位;
16、步骤s23:完成训练数据分组后,对测试集数据进行相同滑动窗口数据处理。
17、优选的,步骤s3所述的端到端自编码器模型由卷积通道编码器、transformer通道编码器、特征融合模块、记忆网络和解码器decoder构成。
18、优选的,步骤s3具体方法如下:
19、编码器中分为卷积通道编码器模块和transformer通道编码器模块;
20、卷积通道编码器的核心模块是卷积神经网络,使用n层卷积操作对图像进行特征提取处理,卷积通道编码器模块公式如下:
21、
22、
23、其中f表示输入训练样本;表示通过卷积提取到的表示特征,其中i表示第i层的卷积特征提取,bn为特征归一化函数,relu为激活函数;为降低分辨率后的特征,maxpool函数为最大池化函数;
24、transformer通道编码器的核心模块是自注意力机制计算,首先将视频序列帧按帧分割为n×n个图像块,并且对其进行layernorm(ln)归一化,通过序列注意力(sequential attention,sa)提取序列特征,通过layernorm(ln)和多层感知机(mlp)进行维度变换,接着进行帧全局特征自注意力提取(attention,at),最后拼接输出,整体公式如下:
25、f1...p={f1...fp}=patch(f)
26、fsa=mlp(ln(sa(ln(f1...p)))
27、
28、其中,f1...p表示f分割后的图像块,fsa表示序列注意力计算后的特征结果,ft表示通过自注意力计算和序列注意力计算后连接的时空特征,表示连接符号;
29、卷积操作与transformer的特征维度并不相同,transformer中图像块尺度是(1+l)×e,其中1、l分别为标识位置信息与图像块的数量,e表示嵌入维度;
30、在卷积中,特征维度为h×w×c,对应为高度、宽度和通道数,因此在transformer通道中首先使用1×1卷积,将特征信息进行与卷积层对应阶段对齐空间尺度,再使用batchnorm(bn)对其进行正则化处理,最后使用interpolate操作将特征还原为对应的特征分辨率,而在卷积通道中通过每个卷积块捕捉到的特征信息,使用平均池化操作对其降维,再通过特征维度转化与layernorm(ln)正则化的方式使其与transformer通道中的特征维度相同,整体转化公式如下:
31、f′c=interpolate(conv(reshape(ft)))
32、
33、其中ft表示从transformer通道中获取到的时空特征,f′c为转化后的卷积格式特征,fct表示编码器最终得到的特征数据,其中reshape操作表示特征格式转化,conv操作为了整合特征格式,interpolate操作采样输入到给定的尺寸比例,concat为拼接函数。
34、优选的,步骤s4所述的记忆网络模块具体方法如下:
35、在记忆网络中,包含m个用于记录各项数据的原型特征,定义每一项为mt,在视频帧通过encoder输出到记忆网络中传入decoder过程中,使用softmax操作获得中包含了mt与编码器特征fct之间的关系,整体公式如下:
36、
37、优选的,步骤s6中均方误差(mse)公式如下:
38、
39、其中为预测帧,f为真实帧,n表示视频序列长度。
40、因此,本发明采用上述的一种多尺度高维特征分析无监督学习视频异常检测方法,具有以下有益效果:
41、(1)提取视频序列图像的表示特征和时空特征,提升了预测帧精度,增强了模型的正样本特征信息;
42、(2)利用时空特征与表示特征提高对视频图像的序列波动的拟合能力,并且增加了模型的异常检测分数,大大提升了模型在视频异常检测上的效果。
43、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!