一种基于类原型匹配软伪标签的半监督医学图像分类方法
本发明属于医学图像分类,具体涉及一种基于类原型匹配软伪标签的半监督医学图像分类方法。
背景技术:
1、医学图像分类是医学影像诊断领域中的一个重要任务,其目的是通过分析医学图像,诊断患者的病情。目前,基于深度学习的医学图像分类技术,通过对医学影像的定性定量分析,可以协助医生更快地发现隐藏病灶完成诊疗工作,降低人工漏诊率、误诊率以及诊断所需的成本。然而,由于医学图像数据集通常规模较小、标注成本高昂,传统的监督学习方法在医学图像分类任务中面临着数据不足、过拟合等问题。半监督学习技术可以在一定程度上缓解这些问题。现有的许多研究表明,用大量未标记数据来辅助少量的标记数据训练的半监督学习方法可以显著地提高模型分类的准确率,可以接近甚至达到完全使用大量标记数据训练的效果。此外,相比于有标签的医疗数据,无标签的医疗数据不仅能够更容易地从临床实践中收集,还节省了数据标注的成本。因此,研究基于半监督学习的医学图像分类方法是一项非常有意义的工作,可以有效提高深度学习模型的泛化性和鲁棒性,有助于缓解有标签的数据集稀缺的问题,同时改善海量无标签的临床医疗数据未被有效利用的现状,能够降低医疗成本,具有重要的研究价值以及广阔的应用前景。
2、在医学图像领域,关于半监督学习的方法人们已经进行了长期的研究与探索,目前主流的方法为一致性正则化方法和伪标签方法。一致性正则化方法基于平滑性假设,通过在不同扰动下,通过约束未标记数据的输出来提高模型的分类性能和泛化能力。此类方法有效利用了未标记数据的信息,且方法简单易于实现。然而,一致性正则化方法也存在一些缺陷。首先,一致性正则化方法会约束未标记数据的输出,但未标记数据中可能会包含一些噪声,这些噪声会影响模型的性能。因此,一致性正则化方法可能会对噪声敏感。其次,此类方法严重依赖于扰动函数需要适应每种新的医学图像,因此泛化能力较弱。伪标签方法通过利用标记数据训练出的模型对未标记数据进行预测,并将预测结果作为伪标签加入到训练集中,以增加训练数据量从而提高模型的性能。伪标签方法简单易用,不需要额外的工作量,只需要将未标记的数据加入到训练集中即可,因此能够处理大规模的未标记数据。然而,伪标签方法也存在相应的缺陷。首先,由于未标记数据的标签是未知的,如果预测错误,就会将错误的标签加入到训练数据中,会导致模型性能下降。其次,伪标签方法对未标记数据的利用存在局限性。由于此类方法只能利用未标记数据的预测结果,而未标记数据中可能存在一些有用的信息,如特征、类别之间的关系等,但这些信息并未得到利用。再者,伪标签方法通常是通过预先设定一个固定的阈值来筛选出高质量(置信度高于阈值)的未标记样本。尽管这类方法可以有效提高伪标签的质量,但存在一个明显的弊端,即过滤掉了大量低于设定阈值的数据,使得未标记数据的利用率降低。尤其在早期训练阶段,只有少数未标记样本参与训练,使得模型整体性能不佳。
技术实现思路
1、为了克服上述现有技术的不足,本发明的目的在于提供一种基于类原型匹配软伪标签的半监督医学图像分类方法。相比于传统的监督方法,本发明只需要人为对一部分医学图像进行标记即可得到具有良好分类能力的分类器,能够有效节省人工标记图像所花费的时间,同时显著降低医疗成本以及缓解有标签的医疗数据集稀缺的问题,具有分类精度高、泛化性强等优点。
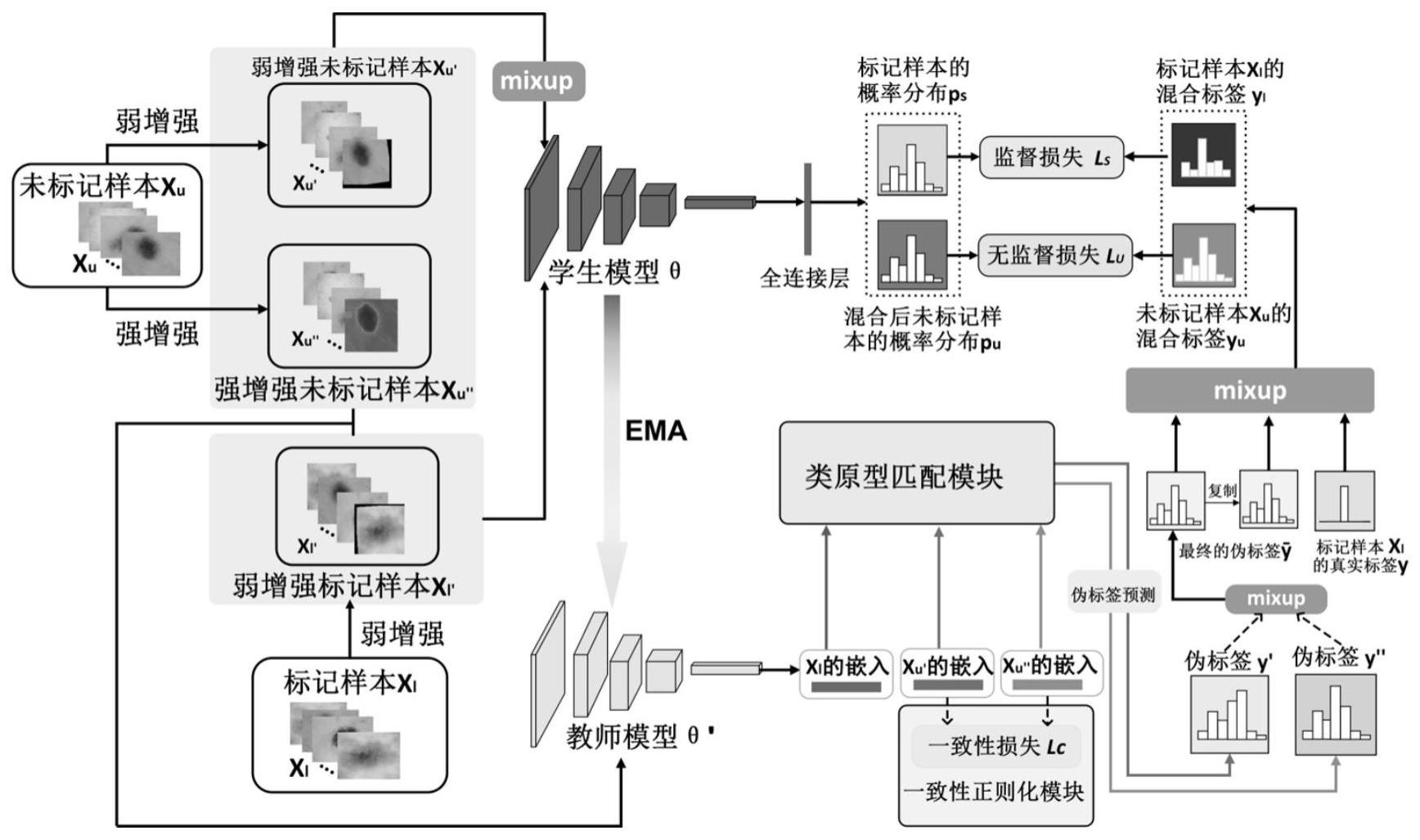
2、为实现上述目的,本发明提供如下技术方案:一种基于类原型匹配软伪标签的半监督医学图像分类方法,包括以下步骤:
3、步骤一、将公开医学图像分类数据集进行划分,分为训练集、测试集以及验证集,并在训练集中划分标记数据集和未标记数据集,对所有图像及对应的标签数据进行预处理;
4、步骤二、构建医学图像分类网络模型fθ(·),包括:输入层、深层卷积层、降采样层、输出层;
5、步骤三、构建标记缓存队列q;
6、步骤四、基于步骤二和步骤三中构建的医学图像分类网络模型fθ(·)和标记缓存队列q设计损失函数,其中包括:有监督损失无监督损失以及未标记数据之间的一致性损失
7、步骤五、以一定批次数量采样所述步骤一中标记数据集和未标记数据集;
8、步骤六、对所述步骤五中的标记图像进行弱增强,对所述步骤五中的未标记图像进行弱增强和强增强;
9、步骤七、将所述步骤六中获得的弱增强后的标记图像,弱增强和强增强后的未标记图像分别输入医学图像分类网络模型,并获得对应的嵌入;
10、步骤八、缓存队列以动态更新的方式为将当前批次经过弱增强后的标记数据的嵌入和标签入队列,队满以后从缓存空间中删除最早入队列的嵌入和对应的标签,再让新的标记数据的嵌入和标签入队列;
11、步骤九、根据所述步骤八中的标记缓存队列,根据有标签样本嵌入的均值,计算不同类别的原型;
12、步骤十、根据所述步骤七中的弱增强未标记图像的嵌入与强增强未标记图像的嵌入以及步骤九中的各类别原型,预测未标记图像的伪标签,得到弱增强伪标签y′与强增强伪标签y″;
13、步骤十一、根据所述步骤十得到的弱增强伪标签y′与强增强伪标签y″,将两者混合后得到的作为所有未标记数据的真实标签;
14、步骤十一、将批次大小为b的强增强和弱增强后的未标记数据记为χu集合和批次大小同样也为b的弱增强后的标记数据集χl利用concat(·)函数合并之后,再使用shuffle(·)函数随机打乱后的混合数据记为w;
15、步骤十二、将弱增强后的标记数据χl与混合数据w中的未标记样本以及它们对应的真实标签和伪标签输入mixup模块进行线性混合,利用不断更新损失的混合数据对网络进行训练;
16、步骤十三、计算有监督损失
17、步骤十四、计算无监督损失
18、步骤十五、计算无标记数据的一致性损失
19、步骤十六、反向传播更新医学图像分类模型参数,并保存最佳的医学图像分类模型;
20、步骤十七、使用测试集中的图像对所述步骤十六的最佳的医学图像分类模型进行分类性能测试,并最后得到对所有测试医学图像的平均auc、敏感度、特异度、准确率和f1-score。
21、与现有技术相比,本发明的有益效果是:
22、1)本发明提出了一种适用于医学图像分类的类原型匹配的软伪标签与一致性正则化的半监督深度学习方法。该算法使用类原型匹配模块(cpm)预测未标记数据的软伪标签,该模块根据未标记数据局部邻域内标记数据的类原型相似度来自适应地预测其对应的软伪标签;
23、2)本发明设计了一个动态且无偏更新的缓存队列来存储预测正确的标记数据的标签和嵌入,并将缓存队列中属于同一类别的多个标记数据嵌入的均值作为该类的原型,使得类原型更加接近于真实特征中心,从而为训练提供强有力的监督信息,以提高预测的伪标签的准确性;
24、3)本发明使用mixup增强方法来混合标记数据和未标记数据及其对应的标签,以增强模型学习类内和类间特征的能力,并在未标记数据两种不同类型的增强之间添加了一个额外的正则化项,以提高模型的预测能力。在两个基准数据集isic2018数据集和chexpert数据集上的实验结果表明,本发明有效地结合了伪标签和一致性正则化方法,在医学图像分类任务上的分类性能和泛化能力优于其他最先进的半监督分类方法。
- 还没有人留言评论。精彩留言会获得点赞!