一种基于图模型的视频显著性目标检测方法
本发明属于计算机视觉领域,视频显著性目标检测旨在通过利用隐藏在视频序列中的空间线索和时间线索来定位和分割最吸引注意力的对象。该任务源于认知研究中人类的视觉注意力行为,即快速的将注意力转移到视觉场景中最具信息量的区域。
背景技术:
1、人类通过视觉感知系统捕获客观世界中的重要物体和场景信息,如景深、外貌、颜色、形状等属性。无论置身于简单场景或是复杂环境,人类都可以迅速定位场景中的感兴趣区域,抓住关键信息,快速、有效地完成信息的处理和整合。为使计算机系统也具备快速定位重要目标、感知场景重要信息的功能,视觉显著检测任务应运而生。场景的显著区域通常包含了人类感兴趣的重要目标或最能表达图像的内容,是能够在较短时间内吸引人的视觉注意力的区域,而显著目标检测就是找出这些感兴趣目标或区域的过程。显著目标检测作为一种有效的预处理技术已被广泛应用于检索、识别、分割、重定向、增强、行人检测、评价、压缩等众多计算机视觉任务。
2、随着大数据时代的来临,数据形式发生了翻天覆地的变化,传统的图像数据已不足以满足人们日益增长的感官需求,视频数据量呈现出井喷式的增长,如何准确、一致地提取视频数据中的显著目标成为亟待解决的新课题。鉴于视频显著目标检测技术良好的可扩展性,已被广泛应用于视频目标检测、视频摘要、基于内容的视频检索等领域。不同于图像显著目标检测,视频显著目标检测需要同时结合时间信息和空间信息,连续地定位视频序列中与运动相关的显著目标。与协同显著目标检测相比,视频显著目标检测还需考虑运动信息和时序特性,而且具有“相邻视频帧间相关性较大”的先验。因此,如何充分挖掘视频序列的运动信息和时序关系成为视频显著目标检测研究的关键。由于视频数据量大、场景变化明显、目标大小不一致等问题,使得视频显著目标检测研究难度较大,算法性能整体较低。近年来,视频显著目标检测方向发展迅速,新算法层出不穷,算法性能不断被刷新。
3、根据是否需要对模型进行训练学习,可将现有的视频显著目标检测方法分为两大类,即基于底层线索的方法和基于学习的方法。其中,基于底层的方法包含基于变换分析的方法、基于信息论的方法、基于稀疏表示的方法、基于视觉先验的方法等;基于学习的方法包含基于传统学习的方法和基于深度学习的方法。
4、基于传统学习的方法
5、liu等[1]提出基于超像素分割的视频显著性检测模型,通过计算运动、颜色直方图感知运动信息。wang等[2]提出无监督的基于测地距离的视频显著对象分割模型,提取超像素区域边界和帧间运动边界,并使用测地距离得到显著性图。liu等[3]提出基于超像素级图与时空域传播的视频显著性检测模型。lee等[4]提出利用低层和高层视觉特征结合机器学习算法进行视频显著性检测。ren等[5]提出基于稀疏表示的视频显著性检测模型。
6、基于深度学习的方法
7、近年来,随着深度学习的蓬勃发展,基于深度学习的视频显著目标检测算法展现出巨大潜力。基于深度学习的视频显著目标检测需要充分挖掘视频序列的时空信息,同时将跨模态的两种信息在不引入噪声的前提下,充分互补的融合,以获取准确、一致的视频显著目标。总结现有的方法,根据框架结构可划分为基于3d卷积融合时空特征的、使用长短时记忆网络挖掘时序特征的、引入光流图形成双流结构的、采用其他结构的。
8、le等[6]提出了一种端到端3d全卷积网络,采用unet[7]的拓扑结构,通过跳跃连接增强上下文信息,丰富各层级的显著特征;cheng等[8]提出基于3d卷积的时间单元的解码器提高对运动信息的感知能力,该结构单元的设计在保持轻量级的同时不降低对是信息的感知能力。
9、fan等[9]提出一种面向显著性转移的长短时记忆卷积网络(ssav)。创新性的将传统的长短时记忆卷积网络(convlstm)与显著性转移感知注意力机制相结合,同时考虑了时序变化和显著性转移从而得到准确的视频显著目标检测。song等[10]提出一种基于递归网络结构的快速视频显著性目标检测模型,引入金字塔扩张卷积和双向的convlstm模块以学习多尺度的时空信息。
10、li等[11]提出了一个基于运动信息引导的视频显著目标检测网络,利用flownet2生成光流图像,设计一个支流用于提取光流图像中体现的运动特征,因此光流图的质量将不可避免的对结果产生影响。xu等[12]提出了一种基于图卷积的多支流注意力网络,在静态支流和运动支流处,分别构建图模型,利用图卷积提取特征,但以超体素作为节点并进行预测难免导致最终预测图的块状效应。ji等[13]提出了一种简单而高效的引导与教学网络架构,分别在编码层和解码层让运动特征隐式和显式指导外观特征的学习。
11、此外,gu等[14]提出了一种基于自注意力机制的视频显著目标检测网络,设计了一种约束自注意操作来捕获局部的运动线索,以此阻止学习与运动无关的上下文信息并且减少计算量和存储成本。zhang等[15]提出一种动态上下文敏感过滤网络,其中上下文敏感过滤模块通过估计与位置相关的亲和权值,动态生成上下文敏感的卷积核,从而提高模型对不断变化场景的适应性。
技术实现思路
1、本发明的目的在于提供一种基于图模型的视频显著性目标检测方法。该方法涉及了一个基于图卷积网络的视频显著目标检测模型。
2、本发明解决其技术问题所采用的技术方案如下:
3、(1)提出基于图卷积网络的视频显著目标检测模型,用于充分挖掘空间信息和时间信息,考虑跨模态和跨层级特征之间的融合互补特性。
4、(2)设计基于图卷积的层级间交互模块,将不同层级的时空特征作为图节点,依据跨模态特征和跨层级特征间的距离信息构建边,通过图卷积更新图节点的特征,并在通道维度上融合跨模态特征和跨层级特征,从而生成时空深度特征。
5、(3)设计基于图卷积的特征自校正模块,将时空深度特征在空间维度上进行映射,对应若干图节点表征相应空间区域,通过图卷积更新图节点的特征,从而建模了空间上的语义关系,加强显著区域间的联系,完整突出显著目标。
6、进一步的,步骤(1)具体实现如下:
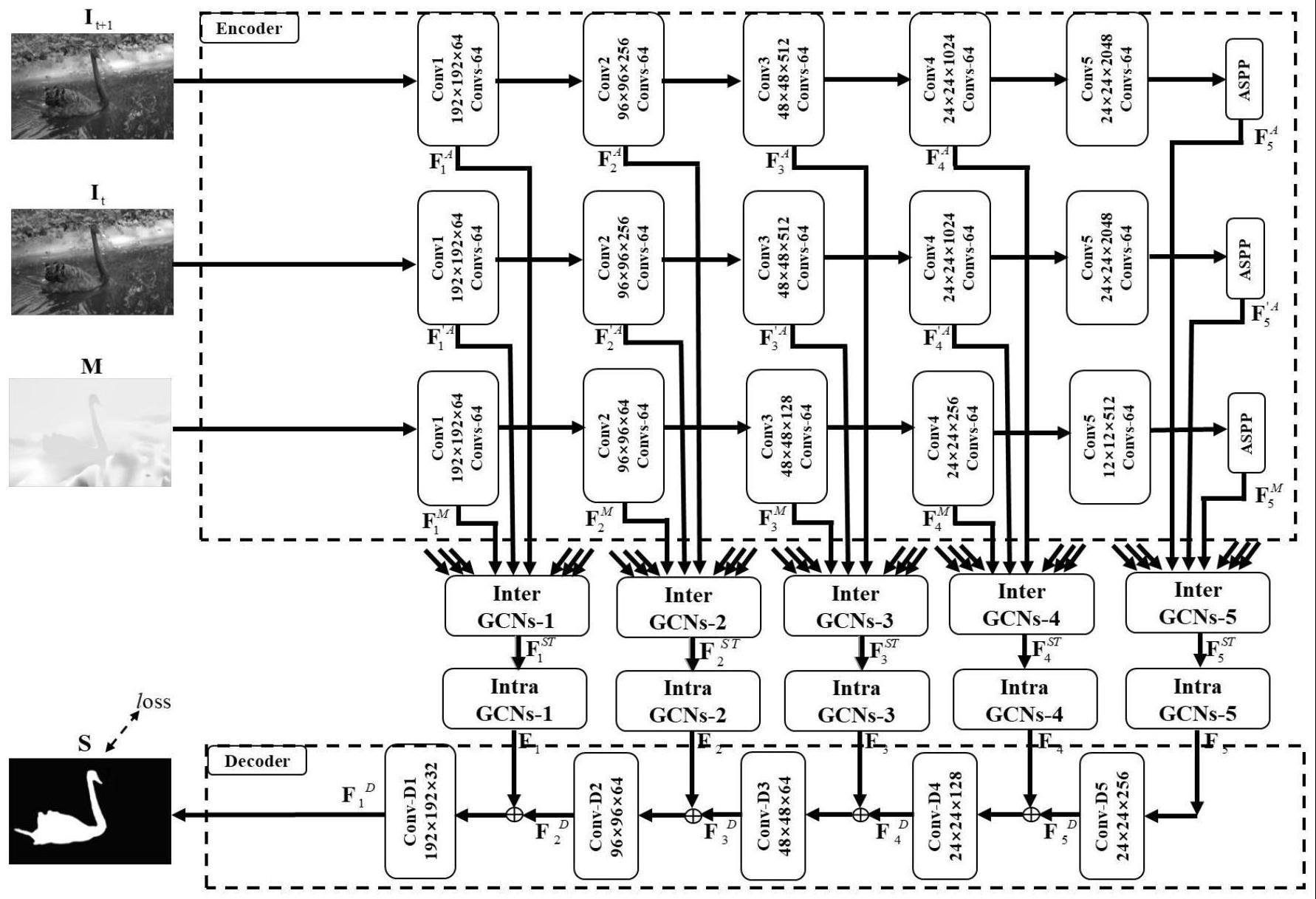
7、所述的视频显著目标检测模型的基本框架如图1所示。在结构上,依照编码器-解码器的结构。编码部分的输入为三张图像,分别是当前帧rgb图像、下一帧rgb图像和当前帧对应的光流图。编码部分由三个主干网络组成,分别提取三张图像对应的特征;其中,两个resnet-50主干网络分别用于提取当前帧rgb图像特征和下一帧rgb图像特征,resnet-34主干网络用于提取当前帧对应的光流图特征。之所以这样设置是因为光流图在生成时已经提取到部分信息,采用结构简单的主干网络就足以提取到与显著性相关的信息且能降低模型的复杂度。此外,有别于双流结构,这里的输入选择了三条支路,考虑到当光流图质量不佳时模型只能依赖于静态的图像来判断显著目标,这样容易使得模型片面的关注图像中的显著目标而忽视视频中的运动信息,因此加入相邻下一帧rgb图像作为运动信息的补充。为了降低计算量,各层级特征在经由主干网络初步提取后,经过一个由3×3的卷积层、bn层、relu激活层组成的降维度模块,将特征通道数均降至64。对于主干网络的第五层(主干网络的最后一层)的深度特征,将其与aspp模块(由多个具有不同采样率的并行空洞卷积层组成,用于获取多尺度的物体信息)相连接,以此融合丰富的多尺度特征。至此通过编码部分分别获得当前帧rgb图像、下一帧rgb图像和当前帧对应的光流图对应的特征fia、其中i是主干网络的层数,取值为1~5。
8、进一步的,步骤(2)具体实现如下:
9、通过基于图卷积的层级间交互模块将主干网络提取到的相邻层级的时空特征融合生成时空深度特征。具体地,输入为fia、输出为
10、对于第一层的特征:由于其不存在相邻的浅层特征,因此在输入inter gcns时,重复输入第一层特征,即f1a、f1a、
11、对于第二层的特征:输入为f1a、同理对于第三层的特征和第四层的特征
12、对于第五层的特征:由于其不存在相邻的深层特征,因此在输入inter gcns时,重复输入第五层特征,即
13、然后,考虑到显著目标之间或内部不同空间区域的关系依赖,采用了基于图卷积的特征自校正模块增强时空深度特征,使特征内部在空间维度上互相增强,互相补充,自我校正。最后,通过简单的逐层解码结构获得最终的显著预测图。
14、本发明有益效果如下:
15、本发明一方面,采用基于图卷积的层级间交互模块,将不同层级的时空特征作为图节点,依据跨模态特征和跨层级特征间的距离信息构建边,通过图卷积网络更新节点特征,生成时空深度特征,在通道维度上融合了跨模态、跨层级特征。另一方面,采用基于图卷积的特征自校正模块,将时空深度特征在空间维度上进行映射,对应若干节点表征相应空间区域,通过图卷积网络更新节点特征,建模空间上的语义关系,加强显著区域间的联系,完整凸显显著目标。
16、基于图卷积网络的视频显著目标检测模型引入了图卷积网络作为提取特征的一环,推理了特征图中的显著区域,实现了多个显著目标之间的相互增强,突出显著区域,抑制背景区域,提升了模型性能。因此,在视频显著目标检测中,在特征融合和特征增强步骤中引入gcn。具体地,一方面让inter gcns促进不同层级间和不同模态(时域和空域)之间特征的融合,突出时空特征图之间共同强调的显著目标,抑制共同弱化的背景和遮挡物,一方面让intra gcns对特征自身进行修正增强,对于深层的解码特征修正显著目标的定位信息,对于浅层的解码特征细化显著目标的边缘特征。
- 还没有人留言评论。精彩留言会获得点赞!