一种基于多模态融合的前视道面障碍物检测方法
本发明涉及一种基于多模态融合的前视道面障碍物检测方法,属于激光点云与视觉图像的多层次特征融合及目标检测领域。
背景技术:
1、随着我国经济的发展,人们的生活水平不断提高,我国的汽车保有量也得到大幅提升。汽车保有量的上升是经济发展的积极信号,但随带之来的安全问题不可忽视,传统汽车被动安全技术已无法达到现代交通安全的标准,为了满足消费者对汽车安全性越来越高的期望,现阶段汽车安全辅助驾驶已经成为当今智能交通安全的重要发展方向。近年来,汽车智能化到了大力的推广和研究,市面上有越来越多的辅助驾驶系统出现。adas(advanceddriver assistance system)全称高级驾驶辅助系统,它通过安装在车上的各传感器来采集车辆自身与车辆周围行驶环境的数据,可以帮助驾驶员规避主动的驾驶失误,从而能够有效提升行驶安全。
2、激光雷达和相机是adas中的两种重要传感器,它们有着不同的特性,常被用于障碍物检测任务中。例如,相机能够采集到车辆行驶过程中的图像信息,从而可以根据这图像来进行障碍物识别与分类工作;激光雷达能够感知目标的距离信息,从而可以获取障碍物的外观尺寸、运动状态等。但是单一传感器的障碍物检测方案存在许多局限性,相机所采集到的图像数据是二维数据,不含深度信息,且容易受到外界光线影响;激光雷达采集到的点云数据包含了目标的三维坐标信息,但是没有颜色信息,能获取到障碍物的细节,在复杂场景下会带来障碍物分类不准确等问题。
3、因此基于激光雷达和相机传感器的信息融合方案越来越受到学者与厂商的关注,传感器信息融合能够结合各传感器的优势,弥补单一传感器的不足。通过对多传感器数据上的融合或对多个传感器测结果上的融合,能够更加准确地描述车辆周围的障碍物信息,为后续的控制层带来数据上的保障,从而提高行车安全。
4、在道面环境感知的诸多研究中,现有算法大都侧重于对人、车的检测和提取,缺乏对其他道面障碍物的检测。综上所述,激光雷达与视觉信息协同的环境感知在遥感遥测、无人驾驶等领域有着重要的应用前景,目前已成为国内外研究的热点。因此,开展与此紧密相关的基础理论及关键术研究迫在眉睫。
技术实现思路
1、本发明的目的在于:提供了一种基于多模态融合的道面障碍物检测方法,解决了道面障碍物检测方法难以对障碍物进行准确检测,以及检测鲁棒性差的问题。
2、本发明采用的技术方案如下:
3、一种基于多模态融合的前视道面障碍物检测方法,包括如下步骤:
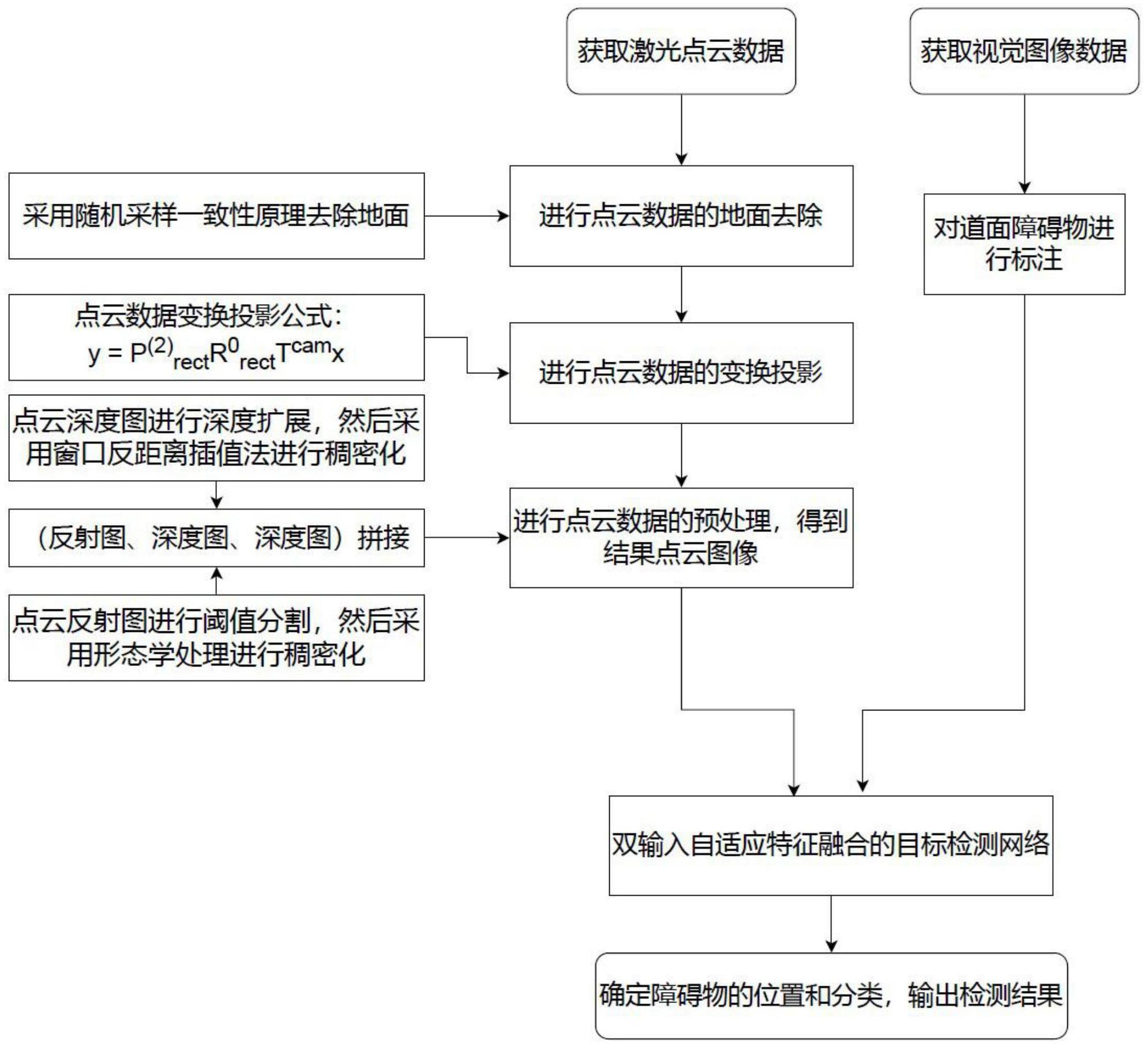
4、步骤1:获取k幅大小为m×n的视觉图像f(x,y)和对应的点云数据v0(x,y,z);
5、步骤2:根据视觉图像f(x,y),对道面障碍物进行标注,;
6、步骤3:对点云数据v0(x,y,z)进行地面去除,得到无地面的点云数据v1(x,y,z);
7、步骤4:根据步骤3的结果,利用坐标变换矩阵,把点云数据v1(x,y,z)从三维变换投影到与视觉图像匹配的二维范围内,得到稀疏的点云深度图像l0(x,y)和稀疏的点云反射图像r0(x,y);
8、步骤5:根据步骤4的结果,对深度图像l0(x,y)和反射图像r0(x,y)进行预处理,得到目标增强后的深度图像l1(x,y)和反射图像r1(x,y),并将其按照(r1(x,y),l1(x,y),l1(x,y))进行拼接,得到点云图像u(x,y);
9、步骤6:根据步骤5的结果,利用双输入自适应特征融合障碍物检测网络,将点云图像u(x,y)和视觉图像f(x,y)输入到网络中进行训练,得到分类结果和目标框,并输出结果;
10、步骤2的具体步骤如下:
11、步骤2.1:在得到点云数据及图像数据后,结合具体路况,将道面障碍物一共分为六大类,分别为小汽车、自行车、行人、有轨电车、交通锥桶、贴有警示条的障碍物;
12、步骤3的具体步骤如下:
13、步骤3.1:利用随机采样一致性原理进行点云数据集的地面模型估计,对点云数据中的地面进行三维拟合,地面模型为平面,平面在三维空间中的结构为:
14、z=ax+by+c
15、其中x,y,z为三维坐标系的坐标轴,a,b,c为坐标轴系数和常数项系数;
16、步骤3.2:平面拟合的过程为在总的点云数据集中随机筛选出一个子集作为内点,并以内点进行平面的拟合;
17、步骤3.3:在步骤3.2得到的结果去测试其他的点云数据,将测定垂直距离与设定的阈值进行对比,若符合条件则为内点,否则为外点;
18、步骤3.4:继续步骤3.2的过程,测试新的模型,对比旧模型的训练结果若有更多的内点,则保存新的模型,否则继续保存旧模型;
19、步骤3.5:重复步骤3.2,步骤3.3,步骤3.4的过程,直到满足迭代条件或者满足迭代次数;
20、步骤3.6:将满足条件的模型及内点在点云数据去除,留下去除路面的点云数据;
21、步骤3.7:重复步骤3.2,步骤3.3,步骤3.4,步骤3.5的过程,得到去除路面和去除人行道的点云数据;
22、步骤4的具体步骤如下:
23、步骤4.1:提取kitti数据集中的calib文件用于点云数据与图像数据的校准,根据calib文件中的数据,将点云数据从雷达三维坐标系变换到2号相机二维坐标系,2号相机为左侧彩色相机,变换投影公式为:
24、
25、其中,y为点云数据变换到2号相机的二维坐标值,x为点云数据的雷达三维坐标值,为0号相机坐标系到2号相机的像素坐标系的转换参数,0号相机为左侧灰度相机,为0号相机的修正矩阵,为0号相机的外参矩阵,用于将数据从雷达坐标系转换到0号相机坐标系;
26、步骤4.2:将点云进行数据匹配后,删除超过视觉图像范围的点云数据,与视觉图像内容保持一致;
27、步骤4.3:对4.2的处理结果上,保留点云数据的深度信息,得到稀疏的点云深度图像l0(x,y);
28、步骤4.4:对4.2的处理结果上,保留点云数据的反射强度信息,得到稀疏的点云反射图像r0(x,y)。
29、综上所述,由于采用了上述技术方案,本发明的有益效果是:
30、1、一种基于多模态融合的前视道面障碍物检测方法,考虑到现实道面中的情况,道面大部分由车行道和人行道构成,并且人行道于车行道具有一定的高度差,采用一次ransac原理去除地面仅能去除掉车行道地面,而人行道地面也对目标检测有一定的影响,因此采用两次ransac原理去除地面,充分利用地面与目标的特性及差异,减弱了地面点云的干扰,提高了算法的鲁棒性;
31、2、早期的目标检测算法中仅仅利用的点云的深度信息,本发明中在点云预处理中引入反射强度信息,有效的增强了反射强度强的障碍物,例如交通锥桶、贴有警示条的障碍物等,充分利用点云的特性,提升了障碍物检测的精度。
32、3、采用深度学习的目标检测方式,将传统的单输入目标检测修改为结合点云的双输入目标检测方法,将点云图像和视觉图像分别经过backbone,将两者的多层特征进行自适应特征融合,有效加强的障碍物检测中的视觉鲁棒性,尤其是在晚上、曝光等环境下,结合激光点云的数据特征能够有效提升障碍物的目标检测效果,即使在视觉环境理想的情况下检测效果也有着一定的提升,从而提高了检测准确度和检测鲁棒性;
- 还没有人留言评论。精彩留言会获得点赞!