一种端到端的多任务联合篇章级事件抽取方法及系统
本发明涉及一种端到端的多任务联合篇章级事件抽取方法及系统,属于自然语言处理。
背景技术:
1、篇章事件抽取(document event extraction,dee)是信息抽取的一个重要研究方向,旨在从非结构文本中抽取结构化事件类型和事件要素。
2、dee包含事件检测和论元识别两个子任务,在事件检测阶段,之前的工作将此任务建模为触发词分类任务,预测给定句子中的每个单词是否是事件触发器以及所触发的事件类型。基于触发词的事件检测依赖于对触发词的识别,然而,触发词的识别并不是事件检测的目的,另外,相较于句子级的事件检测来说,文档的篇幅大,对于触发词的标注是耗时耗力的,于是出现了无触发词的事件检测。
3、在论元识别阶段,一个篇章存在多种事件类型的多个事件,可能是同一种事件类型下有多个事件,或者是不同的事件类型还存在多个事件;另外,还会存在同一个论元会充当多个事件的论元角色,这就是论元重叠问题。那么,对于论元属于哪个事件什么事件类型的哪种论元角色来说,论元的分配就变得尤其困难。已有的大多数篇章级事件抽取方法使用深度学习和联合学习进行特征交互,通过图构建的方式捕获事件类型和论元之间的关系,但是针对篇章事件中的论元重叠问题还是不能很好的解决。
4、另外,事件检测和论元识别并不是两个孤立的过程,对于在事件检测阶段获取到的具有上下文语义信息的伪触发词和在实体识别阶段得到的候选论元来说,如果它们属于同一事件的事件要素来说,它们的关系是紧密的,如果它们不属于同一事件要素来说,它们的关系是相对疏远的。基于此,我们将候选论元特征与伪触发词特征融合,采用多标签分类方法,预测事件论元及论元角色的关系,缓解论元重叠问题。
技术实现思路
1、针对上述问题,本发明提供了一种端到端的多任务联合篇章级事件抽取方法及系统,本发明在没有标注触发词的情况下,通过对文档的编码获取具有上下文语义信息的词,从而完成事件类型的检测、事件数量的预测和伪触发词的识别;将候选论元特征与伪触发词特征融合,采用多标签分类方法,预测事件论元及论元角色的关系,缓解论元重叠问题。
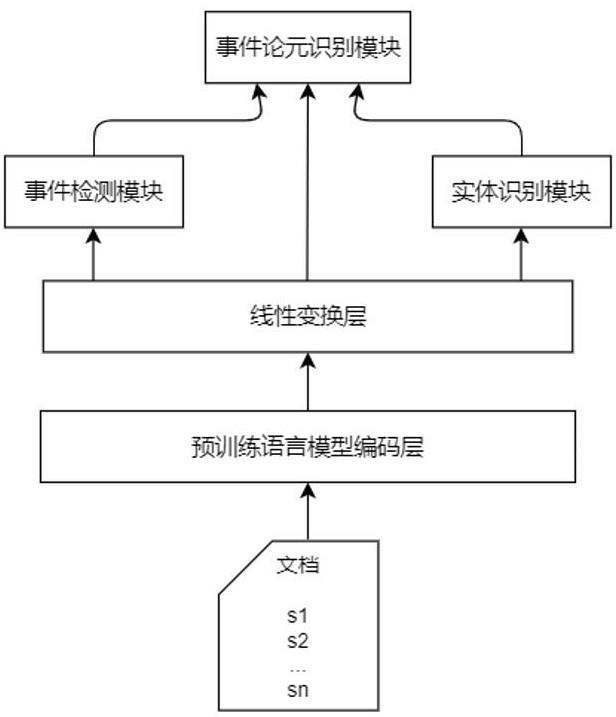
2、本发明的技术方案是:第一方面,本发明提供一种端到端的多任务联合篇章级事件抽取方法,所述方法的具体步骤如下:
3、步骤1:使用预训练语言模型对文本进行编码,得到每个句子的特征表示,然后经过线性变换获取事件检测特征、实体识别特征、事件论元识别特征三组特征分别作为事件检测,实体识别和事件论元识别三个模块的输入;
4、步骤2:在事件检测模块中,将事件检测看作多分类任务,使用从预训练语言模型获取具有上下文语义信息的词,并筛选出对某种事件类型来说贡献最大的词作为伪触发词,来完成无触发词的事件检测;同时,通过回归的方式对每种类型的事件数量做出预测;另外,对于多个事件来说,针对每个事件及每种事件类型选出得分最高的词作为伪触发词,作为论元识别的最终的伪触发词特征;
5、步骤3:在实体识别模块中,利用片段打分方式识别文档中的实体作为候选论元;
6、步骤4:在事件论元识别模块中,将候选论元特征与最终的伪触发词特征融合,采用多标签分类方法,预测事件论元及论元角色的关系;
7、步骤5:将事件检测、实体识别、事件论元识别三个模块通过现有的多任务联合学习方式进行联合优化训练,用训练好的模型实现端到端的篇章级事件抽取。
8、作为本发明的进一步方案,所述步骤1中包含以下步骤:
9、步骤1.1:对输入的文档d进行分句预处理操作,得到n个句子的文档:
10、<mi>d=[</mi><msub><mi>s</mi><mn>1</mn></msub><msub><mi>,s</mi><mn>2</mn></msub><mi>,...,</mi><msub><mi>s</mi><mi>n</mi></msub><mi>]</mi>;
11、使用预训练语言模型plm分词器对句子进行分词处理,每个句子表示为:
12、<msub><mi>s</mi><mi>i</mi></msub><mi>=[</mi><msub><mi>ω</mi><mi>i,1</mi></msub><mi>,</mi><msub><mi>ω</mi><mi>i,2</mi></msub><mi>,...</mi><msub><mi>,ω</mi><mi>i,l</mi></msub><mi>],</mi><msub><mi>ω</mi><mi>i,j</mi></msub><mi>∈</mi><msup><mi>r</mi><msub><mi>d</mi><mi>ω</mi></msub></msup><mi>,</mi><mi>i</mi><mi>∈[1,n]</mi>;
13、其中,n代表文档的句子数,l代表句子切分项token的数量,代表token的特征维度;
14、步骤1.2:将文档的n个句子经过预训练语言模型plm编码后,得到每个句子的向量序列:
15、;
16、于是文档表示为:<mi>c=[</mi><msub><mi>c</mi><mn>1</mn></msub><mi>,</mi><msub><mi>c</mi><mn>2</mn></msub><mi>,...,</mi><msub><mi>c</mi><mi>n</mi></msub><mi>]</mi>,其中,;
17、然后,针对事件检测模块、实体识别模块、事件论元识别模块,对句子向量进行三组线性变换,分别得到事件检测特征、实体识别特征、事件论元识别特征:
18、事件检测特征:;
19、实体识别特征:;
20、论元识别特征:;
21、其中,代表进行线性变换后的新的token特征维度。
22、作为本发明的进一步方案,所述步骤2中包含以下步骤:
23、步骤2.1:在事件检测模块中,将得到的事件检测特征再次进行两个线性变换得到两组特征:和:
24、;
25、;
26、其中,代表进行两个线性变换后的新的token特征维度;用作事件类型和事件数量的预测,用作伪触发词的识别;token代表句子切分项;
27、步骤2.2:将中所有句子的隐状态拼成一个长序列,,其中,n代表文档中的token数;
28、步骤2.3:将通过层归一化和线性层后得到文档中所有token对于每种事件类型的分数:
29、;
30、其中,n代表文档中的token数,m代表事件类型数;
31、步骤2.4:对于事件类型的预测,将事件类型的预测看作多分类任务,对于每一种事件类型取文档中所有token对于每种事件类型的分数最大的值作为对应事件类型的得分:
32、;
33、对文档的事件类型标签]和所得事件类型得分,采用交叉熵损失计算事件类型损失:
34、;
35、均分别表示事件类型标签中的其中一个事件类型;
36、步骤2.5:对于事件数量的预测,将其看作回归任务,对每一种事件类型,将文档中所有token对于每种事件类型的分数经过sigmoid激活函数后取和作为每类事件的事件数量:
37、;
38、对文档的每种事件类型对应的事件数量标签<msub><mrow><msub><mi>d</mi><mi>num</mi></msub><mi>=[n</mi></mrow><msub><mi>m</mi><mn>1</mn></msub></msub><msub><mi>,n</mi><msub><mi>m</mi><mn>2</mn></msub></msub><msub><mi>,n</mi><msub><mi>m</mi><mn>3</mn></msub></msub><msub><mi>,n</mi><msub><mi>m</mi><mn>4</mn></msub></msub><msub><mi>,n</mi><msub><mi>m</mi><mn>5</mn></msub></msub><mi>]</mi>和所得每类事件的事件数量,采用均方误差损失计算事件数量损失:
39、;均分别表示事件类型分别对应的事件数量;
40、步骤2.6:对于伪触发词的识别,认为对于每种事件类型来说贡献最大的token就是触发词;所以,首先针对文档中不定的k个事件和m种事件类型,从步骤2.3所得的文档中所有token对于每种事件类型的分数中,选出k组得分最高的token及其索引:
41、;
42、然后通过索引,从找到伪触发词的特征,其中;
43、步骤2.7:为了后续计算,将伪触发词的特征进行维度变换得到最终的伪触发词的特征:
44、;
45、其中,代表事件数量。
46、作为本发明的进一步方案,所述步骤3中包含以下步骤:
47、步骤3.1:在实体识别模块中,首先对步骤1所得实体识别特征进行线性变换得到<mi>q</mi><mi>=[</mi><msub><mi>q</mi><mi>1,</mi></msub><mi>,</mi><msub><mi>q</mi><mn>2</mn></msub><mi>,...</mi><msub><mi>q</mi><mi>n</mi></msub><mi>]</mi>和<mi>k=[</mi><msub><mi>k</mi><mn>1</mn></msub><mi>,</mi><msub><mi>k</mi><mn>2</mn></msub><mi>,...</mi><msub><mi>k</mi><mi>n</mi></msub><mi>]</mi>:
48、;
49、;
50、q作为实体片段头部特征,k作为实体片段尾部特征,表示q中的元素,表示k中的元素,n代表文档的句子数,l代表句子切分项token的数量,代表进行线性变换后的新的token特征维度;
51、步骤3.2:接着,采用内积的方式,为文档中每一种可能的实体片段进行打分:;
52、得到文档中所有片段的得分,表示文档中所有片段;然后选择片段得分大于0的片段作为候选论元,表示为;i代表实体片段头部,j代表实体片段尾部;
53、训练过程中,命名实体识别采用多标签分类交叉熵损失:。
54、作为本发明的进一步方案,所述步骤4中包含以下步骤:
55、步骤4.1:在事件论元识别模块中,为了简化计算,只使用实体头部特征进行计算,将步骤1得到的事件论元识别特征进行线性变换得到所有实体头部特征:;
56、n代表文档的句子数,l代表句子切分项token的数量,代表进行两个线性变换后的新的token特征维度;
57、步骤4.2:通过实体标签索引,在实体头部特征中找到候选论元的实体头部特征,其中,代表候选论元的个数;
58、步骤4.4:为了识别候选论元的角色类型,对候选论元的实体头部特征进行线性变换和维度变换得到:;
59、其中,代表论元角色的类型数;
60、步骤4.3:使用爱因斯坦求和约定,对步骤2所得的最终的伪触发词特征与候选论元实体头部特征进行计算:;
61、其中,;
62、目的是综合候选论元特征和事件伪触发词特征,对所有候选论元进行多标签分类,预测候选论元与论元角色的关系;
63、对候选论元的识别使用多标签分类交叉熵损失:;
64、其中,是单个候选论元,i代表实体片段头部,j代表实体片段尾部,m代表事件类型数。
65、作为本发明的进一步方案,所述步骤5中包含以下步骤:
66、将事件检测、实体识别、事件论元识别三个模块通过现有的多任务联合学习方式进行联合优化训练,用训练好的模型实现端到端的篇章级事件抽取,其中事件检测模块包括事件类型的预测和事件数量的预测,联合学习的损失为:;
67、为事件类型损失,为事件数量损失,为命名实体识别采用的多标签分类交叉熵损失,为对候选论元的识别使用的多标签分类交叉熵损失。
68、第二方面,本发明还提供一种端到端的多任务联合篇章级事件抽取系统,该系统包括用于执行上述第一方面的方法的模块。
69、本发明的有益效果是:
70、(1)本发明利用采用多任务联合的方式实现端到端的篇章级事件抽取;
71、(2)本发明在事件检测模块中,在没有标注触发词的情况下,通过对文档的编码获取具有上下文语义信息的词,从而完成事件类型的检测、事件数量的预测和伪触发词的识别;
72、(3)在事件论元识别模块,将候选论元特征与伪触发词特征融合,采用多标签分类方法,预测事件论元及论元角色的关系;其中,计算时仅使用实体头部特征,以简化计算过程;
73、(4)将候选论元特征与伪触发词特征融合,采用多标签分类方法,预测事件论元及论元角色的关系,缓解论元重叠问题。
- 还没有人留言评论。精彩留言会获得点赞!