装载机自主铲掘过程的数字孪生数据驱动模型建模方法
本发明涉及数字孪生仿真建模领域,特别涉及一种装载机自主铲掘过程的数字孪生数据驱动模型建模方法。
背景技术:
1、在当前仿真建模领域,单纯基于机理建模在建模精度方面,通常将一些因素进行简化处理,这使得所建立模型与实际情况存在差异,且机理仿真受制于求解速度,计算机资源消耗巨大,难以布置到实际装载机作业现场的边缘设备中,必须借助人类对数据的理解进行调整,否则无法对物理世界反馈的数据以及经验进行再学习。此外,基于数据的数据驱动模型难以嵌入物理规律以及领域知识,作业过程中采集的传感数据存在分散性、有限性、高噪声以及潜在同质化的缺陷,现阶段传感器测量存在固有缺陷导致构建的模型缺乏可解释性,尤其是在处理装载机自主铲掘过程这种非线性、多学科和多尺度的物理系统时,模型的精度、稳定性差且泛化能力严重不足,不能高效地利用这些数据。
2、由于当前单纯基于机理仿真或者单纯基于数据驱动均难以满足未来工程机械的自主化、智能化、无人化发展需求,数字孪生融合建模被提出,其多依赖于数据驱动模型与机理模型的融合实现。由于装载机属于复杂装备,其组成较为复杂,将其工作机理等效进行仿真建模较为困难,目前尚未见实例化的装载机铲掘作业高保真动态建模和仿真系统。
3、因此,以机理模型为核心,将高精度的传感数据特性与系统的机理模型合理有效的结合起来,基于数据驱动的模型构建方法采用统计、机器学习以及人工智能等理论对数据进行处理,通过挖掘数据中的内在信息建立数学模型并表达系统运行状态,以表征输入参量与输出参量间复杂的拟合关系,利用数据驱动模型对机理模型的参数进行修正和补充,实现模型的融合,以建立高保真、动态化模型是仿真建模的重要发展趋势和未来主要发展方向。
技术实现思路
1、本发明提出一种装载机自主铲掘过程的数字孪生数据驱动模型建模方法,旨在解决装载机自主铲掘过程的数字孪生建模中基于单一机理建模或单一数据建模的缺陷,以机理模型为核心,利用机器学习等工业人工智能技术,提出基于机理和数据融合的控制数字孪生建模方法,该方式能够充分利用已有的机理知识和数据,对部件的特性进行精准的刻画;此外,模型同时具有实时数据驱动的更新能力,改变机理模型的仿真输出使之更加接近真实装载机作业阻力(预测作业阻力),建立装载机自主铲掘过程的高保真、动态化模型。
2、本发明采用如下技术方案:
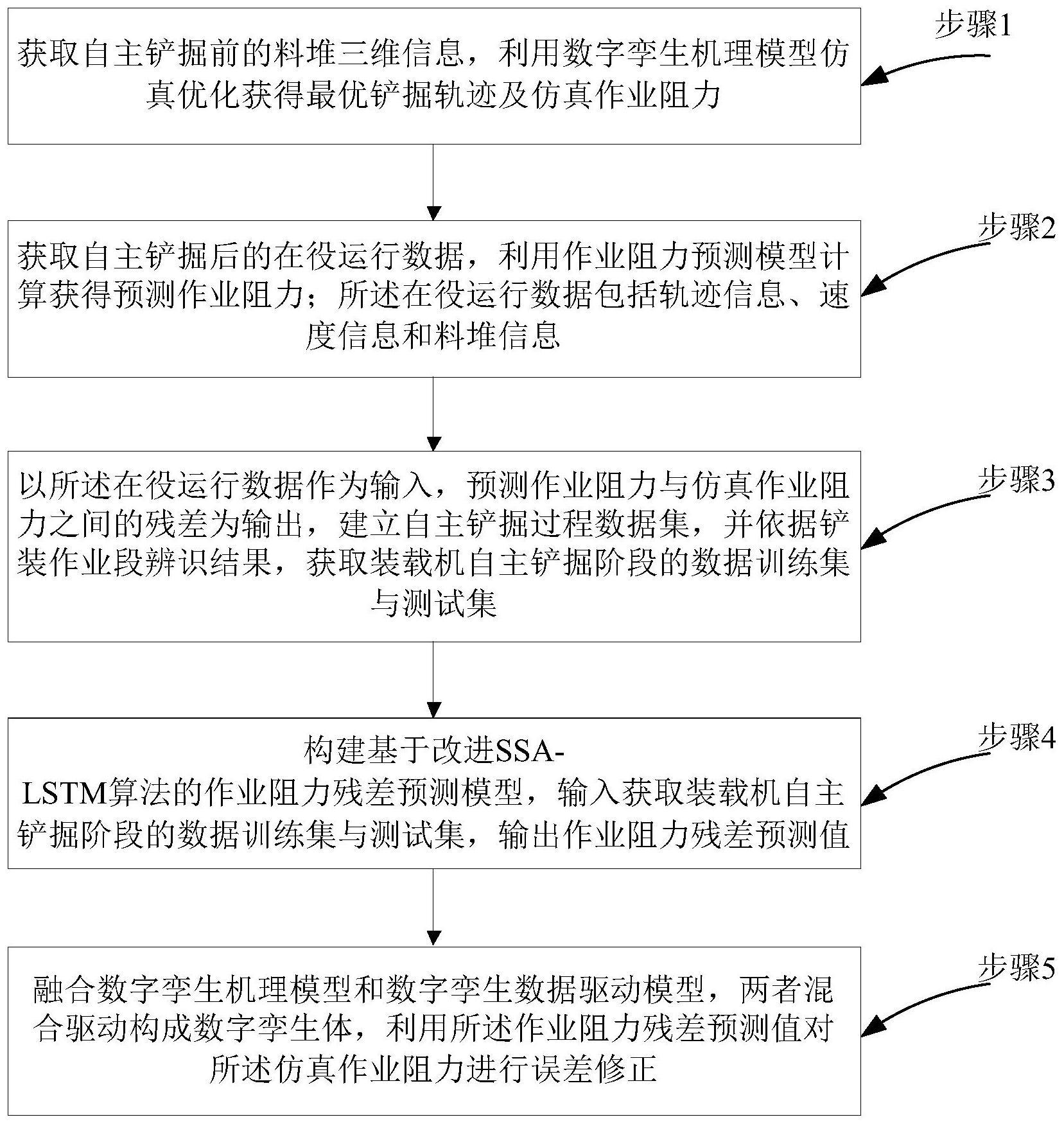
3、一种装载机自主铲掘过程的数字孪生数据驱动模型建模方法,包括:
4、步骤1,获取自主铲掘前的料堆三维信息,利用数字孪生机理模型仿真优化获得最优铲掘轨迹及仿真作业阻力;
5、步骤2,获取自主铲掘后的在役运行数据,利用作业阻力预测模型计算获得预测作业阻力;所述在役运行数据包括轨迹信息、速度信息和料堆信息;
6、步骤3,以所述在役运行数据作为输入,预测作业阻力与仿真作业阻力之间的残差为输出,建立自主铲掘过程数据集,并依据铲装作业段辨识结果,获取装载机自主铲掘阶段的数据训练集与测试集;
7、步骤4,构建基于改进ssa-lstm算法的作业阻力残差预测模型,输入获取装载机自主铲掘阶段的数据训练集与测试集,输出作业阻力残差预测值;
8、步骤5,融合数字孪生机理模型和数字孪生数据驱动模型,两者混合驱动构成数字孪生体,利用所述作业阻力残差预测值对所述仿真作业阻力进行误差修正。
9、优选的,所述步骤1,具体包括:
10、步骤1.1,采用双目视觉相机和激光雷达分别获取铲掘作业时物料堆的堆积状态信息,利用多源数据融合技术将激光雷达的深度信息和双目视觉相机的图像颜色纹理信息进行融合,提取料堆三维信息;
11、步骤1.2,利用装载机自主铲掘过程的料堆三维信息,依据不同作业方式构建基于料堆三维信息的装载机满斗铲掘的轨迹模型,以便根据铲前的料堆三维信息的输入,输出可能的铲掘轨迹信息;
12、步骤1.3,分析装载机自主铲掘过程机械、液压、控制、负载和环境的耦合机理,通过modelica语言的统一语言在mworks平台上进行构建基于modelica的装载机机械、液压、控制、负载和环境数字孪生耦合机理模型,实现物理模型和数字孪生模型的双向映射,如下:
13、步骤1.3.1,构建装载机modelica机械模型,同时将所建立的数字模型其图形化并开放必须的接口,进行拖拽式系统级建模,从而实现耦合模型的机械端构建;
14、步骤1.3.2,确定液压动力元件参数,开放所建立液压系统各部件的对应参数输入接口,进而完成液压系统参数设置;依据上述机械模型的接口信息,进行拖拽式系统级建模,从而完成液压端模型的构建;
15、步骤1.3.3,根据上述所建立的液压端系统数字模型进行稳定性分析,进行控制系统各部件建模,之后以拖拽式系统级建模对控制系统进行构建;
16、步骤1.3.4,最终将结合上述流程整合,构建出完整的装载机机、电、液耦合模型;
17、步骤1.4,分析装载机自主铲掘过程涉及的铲斗与物料的耦合机理,进行铲斗动力学分析与铲斗-物料相互作业分析,构建出装载机铲装机构的动力学模型,如下:
18、步骤1.4.1,基于上述在mworks平台中利用modelica语言构建的完整的装载机机、电、液耦合模型,对装载机铲装作业过程中各类传感器的铲斗的速度、位置和姿态信息进行获取,将这些信息输入到耦合控制端,进而驱动机械端模型;
19、步骤1.4.2,根据铲装物料特性参数和作业地形参数,利用离散元理论,通过modelica语言构建目标铲装物料模型并留出其与装载机机械模型的相应接口,进而构建铲斗结构动力学模型与铲斗-物料的相互作用模型,同时结合双目相机所获得视差图和激光雷达视差图获得更加准确的料堆表面三维信息,并通过接口信息,从而构建出负载-环境的耦合模型;
20、步骤1.4.3,基于上述构建基础,将机-电-液耦合模型与负载-环境耦合的图形化部件模型进行融合,实现装载机自主铲掘过程的数字孪生虚拟模型的构建;
21、步骤1.5,依据铲掘前的料堆三维信息获取可能的铲掘轨迹信息,进而在多领域耦合仿真平台上进行装载机自主铲掘过程轨迹寻优,并输出相应的最优轨迹与对应的仿真作业阻力。
22、优选的,所述步骤3,具体包括:
23、步骤3.1,将阻力预测模型输出的预测作业阻力作为装载机作业阻力的真实值fz,将数字孪生机理模型进行同步仿真输出的装载机自主铲掘仿真作业阻力设置为ff,两者同时输出后作差运算,最终获得作业阻力残差数据fc,如下
24、fc=fz-ff
25、步骤3.2,将自主铲掘后的包括油缸压力、位移和速度的在役运行传感数据作为预测特征列[a1,a2…,ak],k为阻力残差预测特征数量;fc作业阻力残差时间序列数据集作为预测目标列,两者合并后生成装载自主机铲掘过程时间序列数据集dc作为输入,即dc为[a1,a2…,ak,fc]进行铲掘作业段辨识,主要包括:空载前进、铲装、满载后退、满载前进卸料、空载后退5个作业阶段;然后在获得上述所述时间序列数据dc之后,将其划分为训练集与测试集,之后将装载自主机铲掘过程时间序列数据集dc=[dc1,dc2…,dcz]分割成训练集dcr=[dc1,dc2…,dcm]和测试集dce=[dcm+1,dcm+2…,dcz],且满足m<n,其中的dc1为[a11,a12…,a1k,fc1];dc2为[a21,a22…,a2k,fc2];dcz为[az1,az2…,azk,fcz];
26、将提取的训练集与测试集进行预处理,并将数据集分割为若干个lstm数据子集,进而完成数据集的构建;所述预处理包括数据滤波、特征选择以及归一化。
27、优选的,所述步骤4中,构建基于改进ssa-lstm算法的作业阻力残差预测模型的方法如下:
28、步骤4.1,对ssa麻雀优化算法进行改造;设所搭建lstm网络模型有n层lstm层,将lstm网络模型中的网络超参数利用改进ssa算法进行优化;其中,网络超参数包括各层网络神经元数量neurons、dropout神经元随机失活率和batch size网络每批次处理的数据数量;
29、步骤4.1.1,首先加入sobol序列优化初始参数以及种群,使初始化个体分布均匀;
30、根据各个超参数的实际情况,设得到最优解所需超参数取值范围为[xmin,xmax],sobol序列产生的随机数kn∈[0,1],定义种群初始位置xn,如下:
31、xn=xmin+kn·(xmax-xmin)
32、步骤4.1.2,构建麻雀种群,如下:
33、
34、其中,d表示待优化问题的维数,n表示麻雀种群的数量;
35、步骤4.1.3,构建麻雀种群的适应度函数,所有麻雀种群的适应度函数表示成如下形式:
36、
37、其中,表示所有种群适应度函数的集合;表示第1个种群的适应度;表示第2个种群的适应度;表示第n个种群的适应度;代表的即是在设定取值范围内的lstm网络各个超参数;当适应度达到最优时,所选择出来的lstm网络超参数能够使lstm网络输出每个时刻的装载机作业阻力残差预测值与装载机作业阻力残差实际值差别最小;
38、更新最优位置,迭代寻优到达最佳适应度;
39、步骤4.1.4,发现者的位置更新;当r2<st时,觅食区域周围没有捕食者,发现者可以广泛搜索食物;当r2≥st时,捕食者出现,所有发现者都需要飞往安全区域;
40、
41、其中,t表示当前迭代次数,表示在第t代中第i只麻雀在第j维的位置,α∈(0,1],itermax代表最大迭代次数,r2表示报警值,st表示安全阈值,q是服从正态分布的随机数,l是1×dim的矩阵,dim表示维度;
42、步骤4.1.5,跟随者的位置更新;当i>n/2时,第i个加入者的适应度较低,没有同发现者竞争食物的资格,需要飞往其他区域觅食;其他情况下,加入者将在最优个体xp附近觅食;
43、
44、其中,表示第t代适应度最差的个体位置,表示第t+1代中适应度最佳的个体位置;a表示1×dim的矩阵,矩阵中每个元素随机预设为-1或1,a+=at(aat)-1;
45、步骤4.1.6,警戒者位置更新;当fi>fg时,该个体处于种群外围,需要采取反捕食行为,不断变换位置获得更高的适应度;当fi=fg时,该个体处于种群中心,它将不断接近附近的同伴,以此远离危险区域;
46、
47、其中,表示第t次迭代中全局最优位置;β控制步长,服从均值为0、方差为1的正态分布;k∈[-1,1];ε为常数;fi表示当前个体的适应度值,fg与fw分别表示目前全局最佳和最差个体的适应度值;
48、步骤4.1.7,对当前最优解进行扰动产生新解,更新最优位置,直到达到最大迭代次数停止,否则一直重复发现者的位置更新之后的流程;
49、在达到结束条件之后,得到优化后的lstm神经网络超参数;
50、步骤4.2,ssa算法达到最大迭代次数后,将输出的最优lstm网络模型参数输入到lstm网络模型中,然后进行训练预测残差;
51、lstm网络是由细胞状态和遗忘门、输入门和输出门3种门控单元共同组成;在t时刻有细胞状态ct-1、隐层状态ht-1和xt,输出为细胞状态ct和隐含层状态ht;lstm单元的更新过程可用如下:
52、
53、其中,wf、bf、wi、bi、wc、bc为网络权重;ft、it、为遗忘门、输入门、输出门3种门控单元;(h1,h2,...,ht)为隐藏层状态;xt为输入信息,包括装载自主机铲掘过程时间序列数据集dc中除fc作业阻力残差预测目标列之外的油缸压力、位移和速度的在役运行传感数据的特征数据[a1,a2…,ak];bf、bi、bo、bc分别为函数的偏置;ct和ct-1为隐藏层的输出层;
54、输入上述训练集dcr和测试集dce时间序列数据到所构建的lstm网络中进行训练以及测试验证,最终获得训练好的基于改进ssa-lstm算法的作业阻力残差预测模型,输出预测作业阻力残差。
55、优选的,所述步骤5,具体包括:
56、将所述作业阻力残差预测作为补偿,以数据驱动的方式,修正数字孪生机理模型仿真输出的仿真作业阻力,改变机理模型的仿真输出使之不断接近所述预测作业阻力,直至误差达到预设值。
57、与现有技术相比,本发明的有益效果如下:
58、本发明一种装载机自主铲掘过程的数字孪生数据驱动模型建模方法,通过以机理模型为核心,利用机器学习等工业人工智能技术,提出的基于机理和数据融合的控制数字孪生建模方法。该方式能够充分利用已有的机理知识和数据,对部件的特性进行精准的刻画。此外,模型同时具有实时数据驱动的更新能力,改变机理模型的仿真输出使之更加接近真实装载机作业阻力,建立装载机自主铲掘过程的高保真、动态化模型,对工程机械自主化、智能化、无人化的发展具有重要意义。
- 还没有人留言评论。精彩留言会获得点赞!