一种基于区块链的联邦学习方法及其学习系统
本发明属于人工智能模型训练,更具体地,涉及一种基于区块链的联邦学习方法及其学习系统。
背景技术:
1、随着通信技术的快速发展和互联网的广泛应用,来自不同环境的数百万异构设备被连接到无线网络中以提供实时智能服务,这产生了指数级别增长的海量数据。当需要利用不同设备上的数据训练人工智能模型时,传统的方式要求网络中的设备将本地数据上传到中央机构进行集中处理。然而,由于通信成本高、网络安全和隐私问题,这种方法不适用于目前的无线网络环境。因此,联邦学习作为一种具有隐私保护特性的人工智能新范式已被部署在无线网络中以联合网络中的异构设备在不交换私有数据的情况下协同训练人工智能模型。
2、然而,当前的联邦学习面临一种严峻安全挑战。
3、第一,连接到无线网络的一些设备是恶意的,这些恶意设备能通过上传损坏的局部模型(例如向梯度参数添加噪声或使用有毒数据训练局部更新)来操纵全局模型的预测。目前针对此问题的解决方案主要是通过减少异常值对客户端更新参数的影响来抵御恶意节点。专利cn202211394660.3《一种联邦学习中恶意节点检测方法》利用余弦相似度计算每次上传的梯度向量的相似性来确定此次梯度的质量,并计算信誉值来选择优质节点,同时通过余弦相似度判断模型是否为恶意以实现恶意节点检测。然而,仅设计恶意节点检测方案无法有效阻止恶意客户端不断地上传损坏模型,也不能消除损坏参数对全局模型聚合的不利影响。
4、第二,联邦学习面临的另一个挑战是缺乏有效的激励机制。目前为联邦学习所提出的激励方案大多专注于定价机制的设计。专利cn202111647692.5《一种公平可信的联邦学习激励方法》以联邦学习参与者拥有的数据量为报价,并利用后验价格机制赋予参与者一个公平的收益,从而实现通过实施逆向维克里拍卖促使参与者诚实地提交其报价信息以实现最大化收益。然而,基于定价方法设计的激励机制可能无法持续激励异构的联邦学习参与者积极参与联邦学习并在模型训练中贡献本地资源。
技术实现思路
1、针对现有技术的以上缺陷或改进需求,本发明提供了一种基于区块链的联邦学习方法及其学习系统,其目的在于将恶意节点检测与激励机制的有效融合,在联邦学习期间,有效抵御恶意客户端,减小损坏参数对全局模型聚合的不利影响并持续鼓励更多诚实的设备参与联邦学习,防止参与者转化为恶意客户端,提供联邦学习的效果。
2、为实现上述目的,按照本发明的一个方面,提供了一种基于区块链的联邦学习方法,包括:
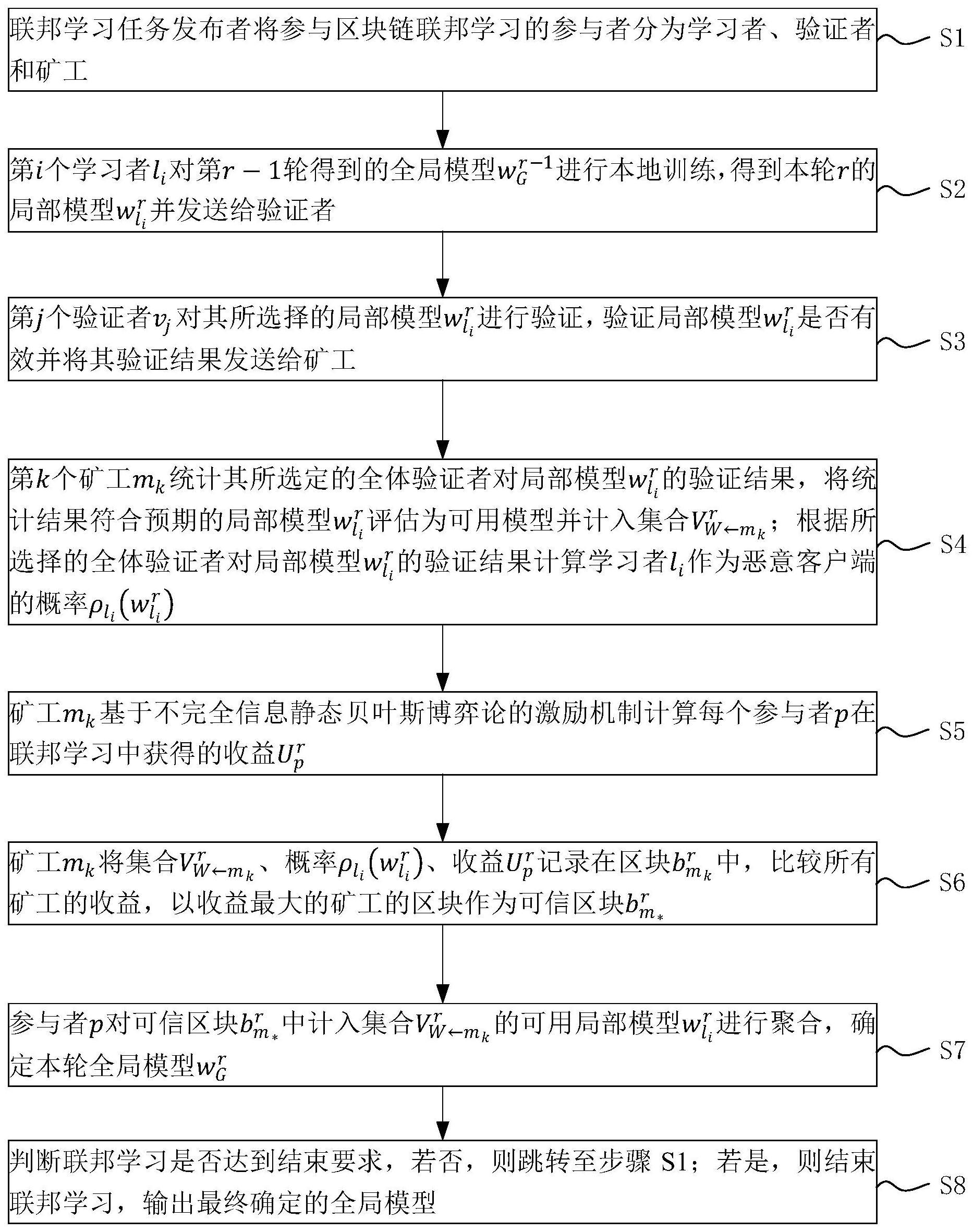
3、步骤s1:联邦学习任务发布者将参与区块链联邦学习的参与者分为学习者、验证者和矿工;
4、步骤s2:第i个学习者li对第r-1轮得到的全局模型进行本地训练,得到本轮r的局部模型并发送给验证者;
5、步骤s3:第j个验证者vj对其所选择的局部模型进行验证,验证局部模型是否有效并将其验证结果发送给矿工;
6、步骤s4:第k个矿工mk统计其所选定的全体验证者对局部模型的验证结果,将统计结果符合预期的局部模型评估为可用模型并计入集合根据所选择的全体验证者对局部模型的验证结果计算学习者li作为恶意客户端的概率以为所有参与者在下轮选择动作策略提供参考;
7、步骤s5:矿工mk基于不完全信息静态贝叶斯博弈论的激励机制计算每个参与者p在联邦学习中获得的收益其中,激励机制为:针对学习者li,根据局部模型是否为可用模型进行奖惩;针对验证者vj和矿工mk,根据其参与验证或评估工作的量进行奖惩;
8、步骤s6:矿工mk将集合概率收益记录在区块中,比较所有矿工的收益,以收益最大的矿工的区块作为可信区块
9、步骤s7:参与者p对可信区块中计入集合的可用局部模型进行聚合,确定本轮全局模型
10、步骤s8:判断联邦学习是否达到结束要求,若否,则跳转至步骤s1;若是,则结束联邦学习,输出最终确定的全局模型。
11、在其中一个实施例中,在步骤s4中,矿工mk统计所选择的全体验证者对局部模型的验证结果,将统计结果符合预期的局部模型评估为可用模型,包括
12、矿工mk选定准备进行评估的若干验证者,构成评估集合
13、获取评估集合中所有验证者对局部模型的验证结果,综合验证结果,若局部模型为有效模型的验证占比超过认为局部模型为无效模型的验证占比,则评估局部模型为可用模型。
14、在其中一个实施例中,每个参与者设置有可信权重;
15、在步骤s3中,以记为验证者vj对局部模型的验证结果,当局部模型被验证者vj验证为有效模型时,记否则,记其中,d为正数;
16、在步骤s4中,综合验证结果,计算局部模型的评估分数若则评估局部模型为可用模型,其中评估分数的计算公式为:
17、
18、式中,表示上一轮确定的可信块中的验证者vj的可信权重。
19、在其中一个实施例中,每一轮联邦学习中,矿工mk根据局部模型是否为有效模型更新区块中学习者li的可信权重:
20、若局部模型并非有效模型,则学习者li的可信权重更新为:
21、若局部模型为有效模型,则学习者li的可信权重更新为:
22、
23、式中,可调系数为设定参数且为可信区块中记录的学习者li的收益,p为参与者的集合,为参与者可信区块中记录的参与者p的收益。
24、在其中一个实施例中,矿工mk中,学习者li作为恶意客户端的概率的计算公式为:
25、
26、在其中一个实施例中,在步骤s3中,第j个验证者vj对其所选择的局部模型进行验证,包括:
27、验证者vj对全局模型进行本地同分布训练,得到对应局部模型的基准模型根据局部模型和基准模型准确率的差距验证局部模型是否有效;
28、其中,第j个验证者vj根据局部模型和基准模型准确率的差距验证局部模型是否有效,包括:
29、分别计算局部模型的准确率以及基准模型的准确率
30、计算准确率差值
31、判断是否满足若是,则验证局部模型为有效模型,否则,验证局部模型为无效模型,θ为设定的阈值。
32、在其中一个实施例中,在步骤s5中,矿工mk计算每个参与者p在联邦学习中获得的收益的计算公式为:
33、
34、式中,rp(sp)、cp(sp)分别是参与者p执行动作策略sp时的奖励函数和成本函数,c0是参与者p加入联邦学习的固定成本;
35、其中,奖励函数rp(sp)为基于所述激励机制生成的函数,包含针对参与者p的惩罚变量和奖励变量
36、针对参与者p为学习者li,当矿工mk判定其局部模型为可用模型,则惩罚变量取0,奖励变量式中,u1为设定的正系数,f1(|dli|)为以学习者li的本地数据集的数据量为变量的递增函数;否则,惩罚变量取负值-u2;奖励变量取0;
37、针对参与者p为验证者vj,当验证者vj未执行验证动作,则惩罚变量取负值-u3,奖励变量取0;否则,惩罚变量取0,奖励变量式中,u4为设定的正系数,为以验证者vj所选择进行验证的局部模型的数量为变量的递增函数;
38、针对参与者p为矿工mk,当矿工mk未执行评估动作,则惩罚变量取负值-u5,奖励变量取0;否则,惩罚变量取0,奖励变量式中,u6为设定的正系数,为以矿工mk所选择进行评估的验证者的数量为变量的递增函数。
39、在其中一个实施例中,奖励函数rp(sp)的表达式为:
40、
41、式中,rp>0为可调的奖励系数,u为设定的单位奖励,为根据矿工mk所生成的全局模型的准确率设置的附加奖励:
42、当mk所生成的全局模型的准确率达到目标阈值,则针对惩罚变量的参与者p,附加奖励取正值u7,针对其他参与者p,附加奖励
43、否则,所有参与者的附加奖励
44、在其中一个实施例中,在步骤s7中包括;
45、每个参与者p对可信区块中计入集合的可用局部模型进行聚合,生成全局模型
46、将全局模型的精度与前面轮次确定的精度最高的全局模型的精度进行比较,若两者差值满足设定要求,则以生成的全局模型作为本轮全局模型,否则,以精度最高的全局模型作为本轮全局模型。
47、按照本发明的另一方面,提供了一种基于区块链的联邦学习系统,包括区块链以及接入区块链的通信节点,所述通信节点包括联邦学习任务发布者和参与区块链联邦学习的参与者,当所述联邦学习任务发布者在所述区块链上发布联邦学习任务后,所述联邦学习系统用于实现上述的方法的步骤。
48、总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
49、本发明通过部署区块链以建立去中心化的联邦学习系统,为实现安全的模型聚合与高参与率的联邦学习提供了保障。在进行联邦学习时,为基于区块链的参与者协调了三种角色,其中学习者用于训练局部模型,验证者用于验证局部模型的有效性,矿工用于汇总不同验证者的验证结果,确定模型是否可用,然后再基于不完全信息静态贝叶斯博弈论的激励机制计算每个矿工的收益,选择收益最大的矿工所挖掘区块作为可信区块以更新区块链。最后再将更新区块链中所记录的可用本地模块聚合,获取全局模块。
50、上述方法中设置验证者和矿工两级判断节点,学习者生成的局部模型的有效性可以由验证者和矿工以去中心化的方式验证,这能有效识别学习者提供的局部模型是否可用,在聚合生成全局模型时,仅选用可用的局部模型,被评估为不可用的恶意模型则直接丢弃,削弱恶意参与者对全局模型的干扰。同时,本发明分析了联邦学习系统中学习者、验证者和矿工的战略性并将其建模为贝叶斯博弈,对于学习者,根据其局部模型是否可用进行奖惩,鼓励学习者提供真实可靠的数据,对于验证者和矿工,则根据其工作量进行奖惩,调动其工作积极性,对更多的数据进行验证和评估,提高验证和评估工作的准确度。基于贝叶斯博弈论,在前述的奖惩激励机制下,各参与者会回溯区块链上记录的关键信息并选择合适的动作策略,因此,该激励机制能鼓励更多诚实的参与者参与联邦学习并防止参与者转化为恶意客户端。
- 还没有人留言评论。精彩留言会获得点赞!