基于多变量Hawkes时空点过程嵌入注意力的兴趣点推荐方法
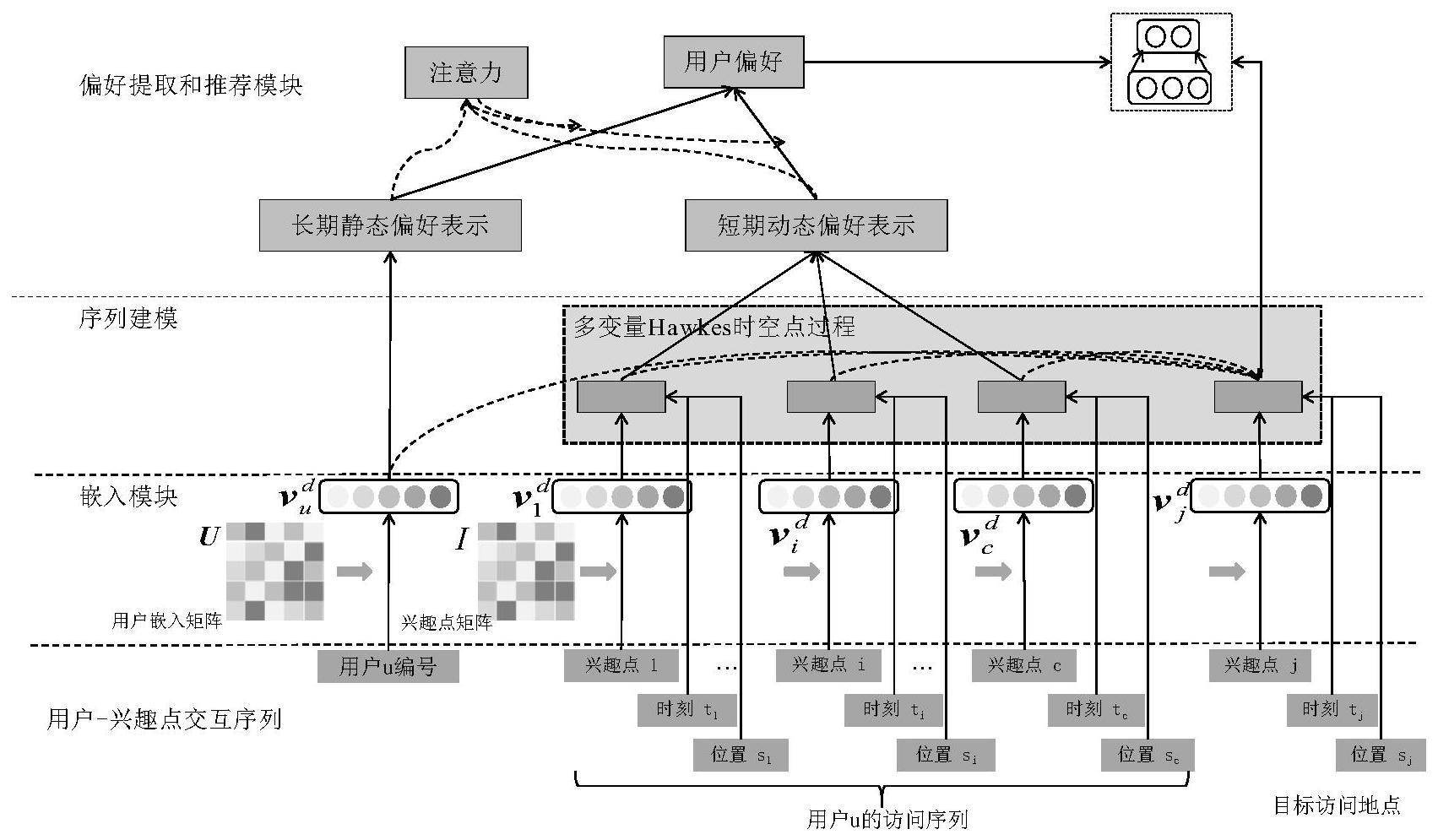
本发明涉及推荐系统兴趣点,具体指一种基于多变量hawkes时空点过程嵌入注意力的兴趣点推荐方法。
背景技术:
1、近年来,配置有gps(全球定位系统)模块的移动智能设备数量激增,时空位置服务已成为重要发展趋势。foursquare、gowalla、yelp等基于位置社交网络服务(location-based social network,lbsn)迅猛发展。人们通过签到方式记录感兴趣的兴趣点(pois,points of interest)。兴趣点推荐通过用户签到数据,分析其历史交互行为,进一步计算其偏好,帮助推荐系统更准确地为其进行兴趣点推荐。
2、目前,推荐方法,包括协同过滤(cf)、基于内容(cb)方法、上下文感知方法和其混合方法,已成功应用在许多领域,如电影/视频推荐,和音乐推荐。兴趣点推荐已有很多工作。
3、现有兴趣点推荐方法仍存在不足:在许多lbsn服务和应用程序中,只考虑序列信息,忽略空间坐标信息;有程序同时考虑时间信息和空间坐标信息,忽略时空关联性,这会丢失关键信息。将时间和空间信息融入循环神经网络中,又因rnn超强假设,签到序列中相邻签到行为会相互依赖,易产生错误依赖关系,影响推荐结果。
技术实现思路
1、本发明针对现有兴趣点推荐不足,提出了一种基于多变量hawkes时空点过程嵌入注意力的兴趣点推荐方法,设计了一个多变量hawkes过程为基础的方法来模拟用户行为序列之间复杂的顺序关系,以及用户行为序列的相应功能,推荐适当兴趣点,根据目标用户长期/短期喜好,以满足其实时需求。
2、为了解决上述技术问题,本发明的技术方案为:
3、本发明采用多变量hawkes时空点过程。hawkes过程主要是一个自我激励过程。hawkes过程最本质特点是点过程:过去发生事件一定会增加将来事件发生概率。hawkes时空点过程是hawkes过程的扩展。在第一个事件没有发生时,存在一个μu,i强度函数(基强度),为某个事件最基本发生概率。
4、在本发明中,采用用户特征表示与待推荐兴趣点特征表示的相似性乘积作为基强度。因为不同用户对兴趣点访问模式和偏好存在差异,将用户信息与兴趣点信息融入hawkes时空点过程中,可以实现个性化建模,区分不同用户行为模式。加入用户信息以及兴趣点信息可以让模型学习到每个用户独特访问规律。
5、本发明首先获取用于实现兴趣点推荐任务的相关数据集,数据集中包含用户集合u={u1,u2,...,u|u|}、用户访问兴趣点数据集i={i1,i2,...,i|i|}和用户访问兴趣点对应时间空间信息序列为
6、su=[(u,i1,t1,s1),(u,i2,t2,s2),...,(u,i|su|-1,t|su|-1,s|su|-1)],(u,i,t,s)∈u×i×t×s,(u,i,t,s)∈su,su∈s,
7、其中(u,i,t,s)表示用户u在t时刻访问兴趣点i,i在位置s处,t为时间戳集合,s为所有兴趣点集合,su为用户u的访问序列。本发明中空间位置s为经纬度坐标(latitude,longitude)。
8、具体的,包括如下步骤:
9、s1.从原始数据中抽取有效数据,构建用户-兴趣点交互数据,令su为用户u的访问序列,(u,i,t,s)∈su,su∈s,其中s为所有用户的访问序列,u∈u,i∈i,其中u为所有用户集合,i为所有兴趣点集合,u为用户编号,i为兴趣点编号,t为用户u访问兴趣点i的时刻,s为兴趣点i的位置。将用户访问序列su送入嵌入模块,分别构建用户u和兴趣点i的特征表示。
10、s2.构建用户u访问兴趣点i事件发生概率的基础强度将用户u的特征表示向量和t时刻用户u访问兴趣点i的特征表示向量输入模型。进行元素级乘法操作,并沿着第一个维度(batch维)求和。获得vu和vu,t,i之间相关性得分μu,i。公式为:
11、μu,i=(vu)tvu,t,i
12、s3.构建用户u行为序列中的历史序列h对当前兴趣点i的初始激发程度向量对用户u历史访问兴趣点h的特征表示矩阵与t时刻用户u访问兴趣点i的特征表示向量vu,t,i进行逐元素相乘。并对最后一维度求和,获取vu,h与vu,t,i之间的相关性得分αu,h,i。公式为:
13、αu,h,i=vu,hvu,t,i
14、s4.计算用户u对历史行为的注意力(attention)权重。
15、s41.将用户u历史访问兴趣点h的特征表示矩阵vu,h输入线性层(vu,hwh+bh),其中为可训练模型参数,再经过非线性激活函数relu(),获得历史访问序列隐特征表示矩阵公式为:
16、hvecu,h=relu(vu,hwh+bh)
17、s42.将用户u的特征表示向量vu与历史访问序列隐特征表示矩阵hvecu,h相乘经过softmax()函数获得用户u对不同历史兴趣点注意力向量公式为:
18、attu,h=softmax(hvecu,hvu)
19、s5.通过基于注意力自适应方法来利用和融合用户偏好。使用注意力模型确定用户长短期偏好动静态权重。
20、s51.将用户u的特征表示向量vu和平均化历史访问兴趣点特征表示向量拼接到一起,构建一个长短期特征表示矩阵获取一个兼具全局及局部信息特征表示,的公式定义如下:
21、
22、其中vu,h是用户u历史访问兴趣点h的特征表示矩阵;是t时刻,用户u历史访问兴趣点h的特征表示总和;|su,t|是t时刻用户u历史访问序列长度;su,t是t时刻用户u的历史访问序列。
23、s52.构建可训练长短期偏好动静态权重矩阵其中w[l,s]可分解为长期偏好静态权重wl和短期偏好动态权重ws,其中采用初始化方法随机初始化可训练长短期偏好动静态权重矩阵w[l,s]。
24、s53.对长短期特征表示与可训练长短期偏好权重矩阵w[l,s]进行矩阵乘法计算,结果再加上可训练偏置向量采用非线性激活函数relu(),并对最后一维度求和,对结果进行softmax()操作,使结果归一化为概率分布。公式为:
25、
26、其中为用户u的长短期偏好动静态权重向量,为用户u的长期偏好静态权重,为用户u的短期偏好动态权重。
27、s6.构建关于用户u的指数核函数,其计算过去事件发生对当前事件发生的历史影响随时间及空间的指数衰减ku(t-th,s-sh)。
28、引入用户相关参数δu>0、γu>0表示历史影响的衰减速率,控制历史事件对当前发生事件的影响,即先前事件的影响随时间向0衰减,接近它们的基本速率μu,i,公式为:
29、ku(t-th,s-sh)=exp(-δu|t-th|-γu|s-sh|)
30、其中δu控制着随时间变化,过去事件对当前事件发生强度的影响程度;γu控制着随距离变化,过去事件对当前事件发生强度的影响程度;k(t-th,s-sh)是用户u关于|t-th|和|s-sh|的指数核函数,其计算历史影响随时间的指数衰减;|t-th|是当前时刻t与历史时刻th之间时间差;|s-sh|是当前时刻t访问的位置s与历史访问位置sh之间距离差。
31、s7.采用多变量hawkes时空点过程对用户行为序列建模,根据历史序列预测/推荐她/他下一个兴趣点。将上述结果带入模型中,公式为:
32、
33、其中是在时刻t时,用户u更偏好s位置处兴趣点i的概率;μu,i是用户u访问兴趣点i事件发生概率的基础强度;是用户u的长期偏好静态权重;是用户u的短期偏好动态权重;attu,h是用户u对不同历史兴趣点注意力向量;αu,h,i是用户u行为序列中的历史序列h对当前兴趣点i的初始激发程度向量。
34、s8.计算用户u在时刻t对兴趣点i′感兴趣的概率,对于每个兴趣点i′∈i,条件分布pi′|u(s,t)在整个兴趣点集合i上。公式为:
35、
36、s9.对用户u在时刻t采样负样本,负样本为兴趣点特征表示(与t时刻,用户历史访问兴趣点特征表示不同)。用负样本兴趣点k′特征表示替换上述i′特征表示为
37、s10.计算损失,并对hawkes时空点过程参数进行优化。为了提高推荐准确性,本发明采用损失loss公式为
38、
39、其中σ(x)是sigmoid函数,n是负样本数量,k′是基于pi从兴趣点集合采样的兴趣点,pi是度分布du是用户u的度,对历史访问序列中没有出现的负样本进行采样。
40、作为优选,步骤s1.从原始数据抽取用户数据(u,i,t,s)u∈u,i∈i,其中u为用户集合,i为兴趣点集合,u为用户编号,i为兴趣点编号,t为用户u访问兴趣点i的时刻,s为兴趣点i的位置。按照用户编号分组,筛选出用户u的历史访问序列其中s为所有用户的访问序列,su为用户u的访问序列。将用户访问序列su送入嵌入模块,分别构建用户u和兴趣点i的特征表示。
41、作为优选,步骤s2.将用户特征表示与时刻访问兴趣点的相似度作为hawkes时空点过程的基础强度值。
42、作为优选,步骤s4计算用户与历史访问序列的注意力权重来捕获用户对历史访问序列不同访问兴趣点的关注度。
43、作为优选,步骤s6计算出t时刻与历史访问序列的时间差值|t-th|以及t时刻用户访问的兴趣点与历史序列的访问兴趣点的距离差值|s-sh|用来捕获hawkes时空点过程中的用户访问序列变化。
44、作为优选,步骤s7.计算用户对于访问兴趣点喜好为hawkes时空点过程模型。
45、作为优选,步骤s10.通过度分布pi∝du3/4,其中du是用户u的度,对历史访问序列中没有出现的负样本进行采样,有助于避免对整个地点序列集进行求和,节省计算时间。
46、本发明具有以下的特点和有益效果:
47、采用上述技术方案,在hawkes时空点过程模型中加入嵌入层缓解数据稀疏问题。直接使用id建模,会面临用户-兴趣点交互矩阵过于稀疏问题。映射到低维稠密嵌入空间,可获得更好的模型表达能力;并且可以捕获隐式特征。因为id本身携带信息有限,映射到嵌入空间后,可通过模型训练学习到用户和兴趣点隐式特征表示。直接在大规模用户-兴趣点空间计算复杂,映射到低维嵌入空间后,计算加速许多。最后统一用户和兴趣点。把不同类型id映射到同一空间,方便模型统一学习用户-兴趣点相关性。
48、另外,采用用户特征表示与待推荐兴趣点特征表示的相似性乘积作为基强度。因为不同用户对兴趣点访问模式和偏好存在差异,将用户信息与兴趣点信息融入hawkes时空点过程中,可以实现个性化建模,区分不同用户行为模式。加入用户信息以及兴趣点信息可以让模型学习到每个用户独特访问规律。
- 还没有人留言评论。精彩留言会获得点赞!