一种基于磨粒特征优选的磨损状态精准辨识方法
本发明属于机械装备磨损状态监测,具体涉及一种基于磨粒特征优选的磨损状态精准辨识方法。
背景技术:
1、机械装备运行过程中,因摩擦副之间的相对运动引起的接触表面磨损是不可避免的。磨损是零部件失效的基本形式,是机械装备产生故障的主要原因。磨粒作为磨损过程的直接产物,携带了大量的磨损信息。基于磨粒特征对机械装备磨损状态进行分类识别,不仅可以为机械装备的运维提供决策支撑,还能够分析磨粒特征的内再联系,有效促进机械装备的智能运维。但是机械装备磨损状态复杂,且磨粒特征繁多加大了机械装备磨损状态辨识的难度,因此选择合适的特征并构建有效的分类模型是机械装备磨损状态监测领域的研究热点。
2、在众多基于磨粒特征的磨损状态识别方法中,人工智能领域的机械装备学习算法因其强大的非线性拟合能力受到众多学者青睐。传统的机械装备学习算法主要通过构造复杂的高维数据特征,借助神经网络、逻辑回归和支持向量机等模型对机械装备磨损状态进行分类。此类方法可以综合多种磨粒特征的特点来实现磨损状态识别,但是,当选择的特征之间存在明显的相关性时极易造成特征冗余,导致模型分类精度降低。因此,本发明旨在提出一种磨损状态辨识方法,解决特征冗余性对磨损状态辨识精度的影响。
3、基于决策树的随机森林模型可以在完成分类的同时对输入指标的重要性进行评估,从而筛选出最佳特征。但是在应用于机械装备磨损状态辨识任务时,该模型还存在以下问题:
4、1)随机森林模型根据训练的效果评估特征子集的优劣,当输入指标存在较强共线性时模型会出现过拟合,从而使模型可靠性降低。
5、2)传统的随机森林模型忽略了磨粒特征波动性过大对机械装备磨损状态的影响,导致模型分类精度低,泛化能力差。
6、综上所述,磨粒分析技术通过获取磨粒特征可以实现磨损状态表征。然而,磨粒特征波动性大且特征之间存在冗余信息,制约了磨损状态辨识的精度。
技术实现思路
1、本发明的目的是提供一种基于磨粒特征优选的磨损状态精准辨识方法,解决了磨损状态辨识时,磨粒特征之间信息冗余的问题和数据挖掘不充分的问题,提高了机械装备磨损状态辨识的精度。
2、本发明所采用的技术方案是,一种基于磨粒特征优选的磨损状态精准辨识方法,
3、步骤1、采集机械装备不同磨损状态下的磨粒特征制作数据库;
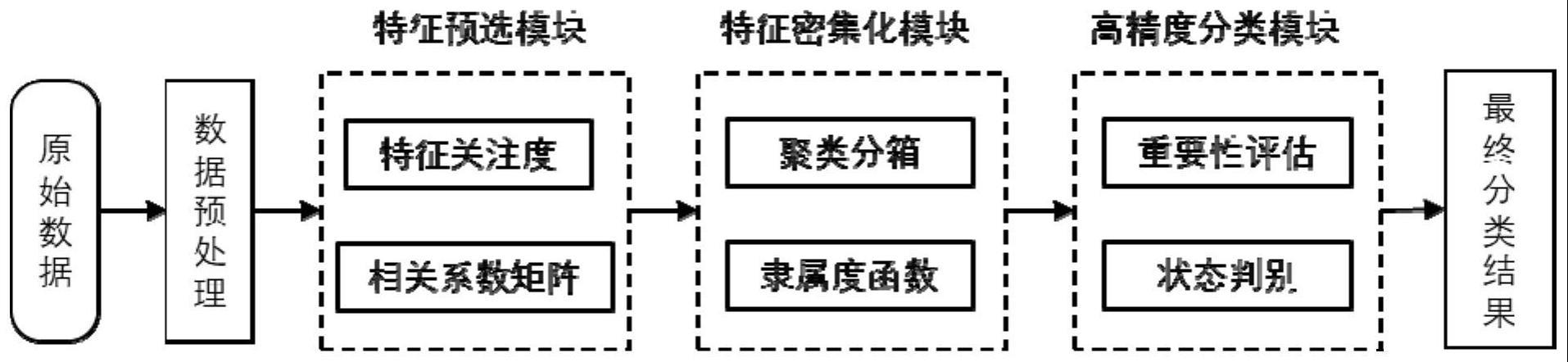
4、步骤2、为解决磨粒特征共线性过强,导致磨损状态表征模型过拟合的问题,建立摩擦学知识引导的磨粒特征预选模块,通过协同磨粒特征关注度与相关系数的特征筛选策略剔除具有高共线性的特征;
5、步骤3、为进一步挖掘磨粒特征内在规律,同时避免数据波动过大导致模型准确率低的问题,建立基于分箱策略的磨粒特征密集化模块,以聚类分箱的方式构建磨粒特征隶属判别方法,将原始磨粒特征划分为若干磨粒子特征;
6、步骤4、为实现基于磨粒特征自适应优选的机械装备磨损状态辨识,建立融合多级决策的磨损状态高精度分类模块,通过评估样本平均不纯度先对磨粒子特征进行重要性评估,然后再通过磨粒子特征的重要性来求原始磨粒特征的重要性,最后根据原始磨粒特征的重要性评估结果对其进行优选,再利用评分机制判别机械装备磨损状态;
7、步骤5、以随机森林架构为基础,嵌入磨粒特征初筛模块、密集化模块和分类模块,建立基于磨粒特征优选的磨损状态辨识模型,实现机械装备磨损状态辨识。
8、本发明的特点还在于,
9、步骤1具体为:
10、步骤1.1:采集机械装备不同磨损状态下的磨粒特征,并依照机械装备实际磨损状态等级对每一组采样数据进行标记;
11、步骤1.2:对监测数据进行预处理,通过均值填充和3σ法则对数据中特征缺失和明显异常的标签样本进行修正或剔除;
12、步骤1.3:建立磨损状态辨识数据集,并按5:1划分训练集和测试集;
13、其中,训练集作为输入,用于进行构建随机森林模型并完成磨粒特征筛选,测试集用于对随机森林模型的效果进行测试;
14、步骤2具体为:
15、步骤2.1:以摩擦学知识为引导建立基于磨粒特征关注度的样本数据选择机制,为磨粒特征预选提供数据支撑;
16、步骤2.2:建立基于磨粒特征相关系数矩阵的特征预选策略;
17、进一步的,步骤2.2中的特征预选策略如下:
18、步骤2.2.1:计算磨粒特征相关系数矩阵,选出具有最大相关系数的特征m和n;
19、步骤2.2.2:分别计算磨粒特征m和n与其他磨粒特征相关系数的平均值m和n;
20、步骤2.2.3:若m>n,则剔除磨粒特征m,反之则剔除磨粒特征n;
21、步骤2.2.4:重复上述步骤直到所有磨粒特征两两之间的相关系数小于阈值0.8。
22、步骤3具体为:
23、步骤3.1:对经过初步筛选的磨粒特征进行归一化处理;
24、
25、其中m(a)代表第a个磨粒特征,x(a)代表归一化后的数据;
26、步骤3.2:建立基于聚类算法的磨粒特征分箱模块,将磨粒特征按照数值大小划分为若干子特征区间;
27、步骤3.3:以步骤3.2中子特征区间的中心和标准差,构建基于混合高斯函数的磨粒子特征隶属度函数;
28、
29、其中,σk(a)和μk(a)为原始磨粒特征a的第k个子特征标准差和均值。
30、步骤3.4:依照样本数据隶属于子特征区间的结果,以最大隶属度原则将原始磨粒特征划分为若干磨粒子特征。
31、步骤4具体为:
32、步骤4.1:将步骤3.4获得的磨粒子特征作为多级决策的磨损状态分类模块的输入,利用平均不纯度减少法评估子特征的重要性;
33、特征重要性计算式如下:
34、
35、
36、
37、其中,vimak代表子特征ak的重要性;z代表构建的随机森林模型中决策树的数量;giniz(x)代表第z颗决策树划分前数据集x的基尼指数;giniz(x,a)代表第z颗决策树在特征a划分后数据集的基尼指数;h代表样本数据集中磨损状态的类别数量;ph代表数据集x中随机选择的样本属于类别h的比例;数据集子特征ak的某一取值将数据集x划分为两个子集x1和x2;|x|、|x1|和|x2|分别代数据集x和子集x1、x2的样本数;
38、步骤4.2:对隶属于同一磨粒特征的磨粒子特征进行算数加权,得到原始磨粒特征重要性的降序集合;当相邻磨粒特征重要性之差超过阈值t时,剔除排序靠后的全部特征,保留剩余磨粒特征作为最佳磨粒特征。
39、步骤4.3:利用最佳磨粒特征建立若干决策树对机械装备磨损状态进行一级决策;
40、步骤4.4:建立基于投票评分机制的磨损状态二级决策体系,通过统计一级决策的结果获取机械装备磨损状态评估的最终结果。
41、步骤5具体为:
42、步骤5.1:以随机森林架构为基础,嵌入磨粒特征初筛模块、密集化模块、和分类模块,建立基于磨粒特征优选的机械装备磨损状态辨识模型,具体涉及的模型参数包括:
43、n_estimators=500
44、max_features=6
45、max_depth=none (6)
46、min_samples_leaf=1
47、max_leaf_nodes=none
48、其中n_estimators代表决策树的个数;max_features代表构建决策树最优模型时考虑的特征数;max_depth代表决策树的最大深度,none代表不限制子数的深度;min_samples_leaf代表叶子节点含有的最少样本;max_leaf_nodes代表最大叶子节点,none代表模型对叶子节点没有限制。
49、步骤s5.2:将测试集数据输入基于磨粒特征参数优选的随机森林模型以完成机械装备磨损状态辨识。
50、本发明的有益效果是:
51、1、本发明对原有的随机森林模型进行改进,提出了一种基于磨粒特征优选的随机森林磨损状态辨识方法,通过采集机械装备不同磨损状态下的磨粒特征构建数据集;建立摩擦学知识引导的磨粒特征预选模块,通过协同磨粒特征关注度和相关系数矩阵剔除高共线性特征;建立基于分箱策略的磨粒特征密集化模块,通过磨粒特征隶属度将原始磨粒特征划分为若干磨粒子特征;建立融合多级决策的磨损状态分类模块,通过评估样本平均不纯度实现磨粒特征重要性评估,再利用优选的磨粒特征判别机械装备的磨损状态。
52、2、本发明基于随机森林架构进行改进,解决了磨损状态辨识时,磨粒特征之间信息冗余的问题和数据挖掘不充分的问题,提高了机械装备磨损状态辨识的精度。
53、3、本发明基于相关系数矩阵剔除共线性较强的磨粒特征;提出基于聚类算法和隶属度函数的分箱策略进一步挖掘数据内在特征;利用基于原始磨粒特征随机森林模型进行特征优选;建立基于优选磨粒特征的随机森林模型,实现机械装备磨损状态辨识。
- 还没有人留言评论。精彩留言会获得点赞!