一种基于图像视觉增强和半监督学习的水下目标检测方法与流程
本发明属于计算机视觉,具体涉及一种基于图像视觉增强和半监督学习的水下目标检测方法。
背景技术:
1、随着经济的发展和资源的日益缺乏,水下环境探索和水下科学研究近年来备受关注。基于深度学习的水下光学目标检测在水下探索和研究中具有重要的意义。由于水下环境复杂多样,将通用目标检测模型直接用于通用目标检测相比,水下目标检测面临更多的困难和挑战。
2、一方面,水下成像环境复杂,通过光学成像设备获得的光学图像往往存在低对比度、模糊、低亮度等问题,上述问题会限制目标检测模型的性能,一种容易想到的解决方法是利用视觉增强或恢复算法对水下图像进行预处理,并且大多数水下图像恢复工作提出“恢复图像可以提高其视觉质量并提高计算机视觉任务的性能”。例如,jingchun zhou等人提出“退化的水下图像严重限制了特征提取、目标检测和特征匹配等实际应用,因此从模糊的视频和图像中恢复真实的场景具有重要的意义”。
3、但最近的研究中发现,利用现有的视觉增强或恢复算法对水下图像进行预处理不能提高目标检测的性能,甚至会导致目标检测性能下降。例如,jiashuo zhang等人选择了3种具有代表性的图像视觉增强算法处理水下数据集,分别为传统方法、uwcnn、funie-gan,通过实验得出结论:不同的图像质量参数的变化与最终检测精度没有明显的统计相关性;xingyu chen等人分别利用frs、gan-rs处理水下数据集,通过实验得出“域质量对域内卷积表示和检测精度有可忽略的影响”的结论;haifeng yu等人提出一种结合dcp和clahe的图像视觉增强方法,该方法具有良好的水下图像增强性能,但实验发现该方法会降低目标检测的精度。因此,近期部分工作基于“如何利用水下图像恢复或增强提高目标检测性能”展开。例如,wen-yi peng等人提出“将水下图像恢复作为数据增强可以提高目标检测精度”;xingyu chen等人提出“视觉恢复可以减小训练数据与真实场景之间的域移,从而提高在线检测性能”。然而上述所有方法都忽略了图像视觉增强算法中参数的可调节性,即合适的参数可能是利用图像视觉增强提高目标检测性能的关键。
4、另一方面,基于深度学习的目标检测器性能很大程度上依赖于标注数据集的大小。但由于水下图像中目标模糊难以识别,人工标注的成本很高,而获取无标注图像的成本相对较低,因此,研究如何利用无标注数据提高水下目标检测器的性能十分重要。近年来半监督学习(ssl)受到了越来越多的关注,它的优势在于可以利用无标注数据进行网络训练,从而在有标注数据较少的情况下提高网络的性能,在很大程度上减小了深度学习模型对于有标注数据的依赖。
5、关于半监督学习的研究大多集中在分类任务上,如基于伪标签和基于一致性正则化两种流行的ssl方法,以及结合伪标签和一致性正则化的ssl方法。吸取分类任务中的经验和教训,针对半监督目标检测的研究也在不断发展。例如,jisoo jeong等人提出一种基于一致性的半监督目标检测方法(csd),类似于半监督图像分类中的一致性正则化(cr),该方法将一致性约束作为工具,通过充分利用可用的未标记数据来提高检测性能。kihyuksohn等人提出一种结合自训练和一致性正则化的半监督目标检测框架(stac),受噪声学生(noisy student)的启发,进行两个阶段的训练,并结合两阶段目标检测器faster r-cnn在ms coco数据集上取得了很好的效果。qiang zhou等人提出一个完全端到端的半监督目标检测框架(instant-teaching),它在训练迭代中使用实时伪标记。上述方法半监督目标检测方法均未与anchor-free的目标检测器相结合,并且目前为止还没有将半监督学习引入水下目标检测领域的工作。
技术实现思路
1、针对上述现有的视觉增强或恢复算法对水下图像进行预处理不能提高目标检测的性能的技术问题,本发明提供了一种基于图像视觉增强和半监督学习的水下目标检测方法,该方法使用一个轻量级卷积神经网络预测图像视觉增强模块的可调节参数,使得视觉增强模块预处理之后的图像有助于后续目标检测任务;该方法还将半监督学习框架引入水下目标检测领域,并与无锚框的目标检测器结合,很大程度上减弱了水下目标检测对标注数据的依赖,在只有少量标注数据的情况下具有良好的性能。
2、为了解决上述技术问题,本发明采用的技术方案为:
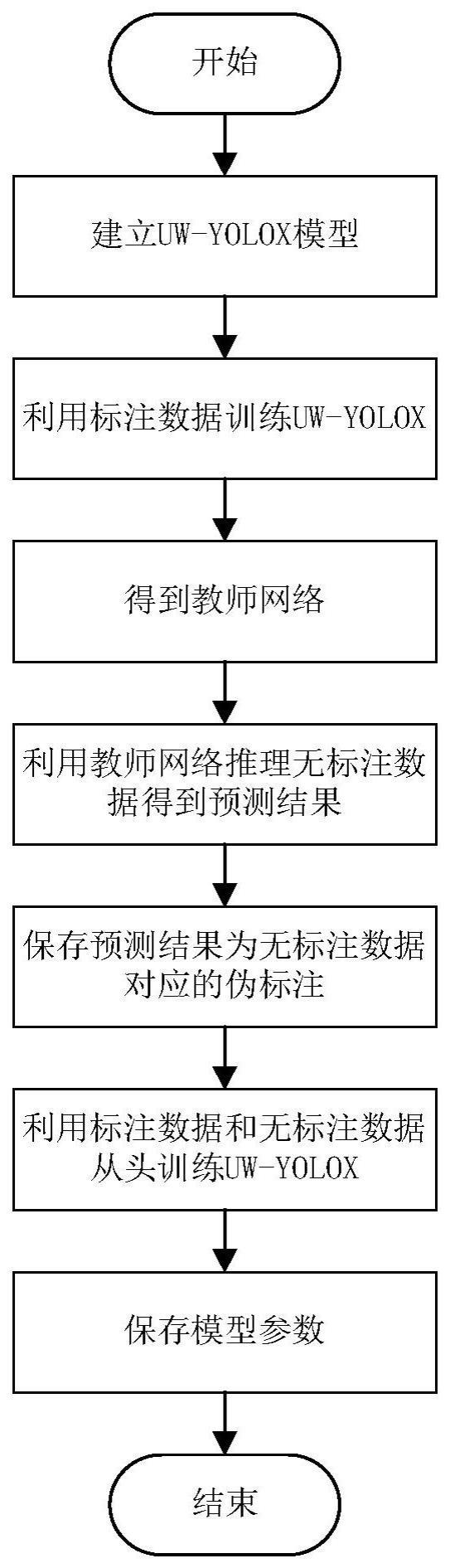
3、一种基于图像视觉增强和半监督学习的水下目标检测方法,包括下列步骤:
4、s1、建立水下目标检测模型;
5、s2、利用所有的标注数据训练s1中建立的水下目标检测模型得到教师模型,该训练过程中通过最小化监督损失进行模型参数优化;
6、s3、利用s2中得到的教师模型推理无标注数据,得到无标注数据的伪标注,伪标注包括位置坐标和类标签,其格式与人工标注的格式保持一致;
7、s4、利用标注数据和无标注数据从头开始训练s1中建立的水下目标检测模型,训练过程中,标注数据使用mosaic和随机仿射变换进行数据增强;对无标注数据使用全局颜色变换、coarsedropout、mosaic和随机仿射变换进行数据增强;通过最小化无监督损失和监督损失的加权和来优化模型参数。
8、所述s1中建立的水下目标检测模型包括三个部分:视觉增强参数预测模块ve-pp、视觉增强模块ve和目标检测器。
9、所述视觉增强参数预测模块采用轻量级卷积神经网络peleenet,其作用是预测ve模块中的可调节参数,针对不同水下图像生成不同的视觉增强参数,实现水下图像自适应增强。
10、所述视觉增强模块包括四个图像滤波器:white balance图像滤波器、gamma图像滤波器、contrast图像滤波器和sharpen图像滤波器;以上四个滤波器均可微,以保证ve-pp模块可以通过反向传播进行网络训练;以上四个滤波器中参数都与待处理图像的分辨率无关,使得ve-pp模块的输入图像可以将分辨率缩小到304×304,以节省计算资源;ve-pp模块实际处理的图像分辨率为416×416,与目标检测网络输入图像的分辨率保持一致。
11、所述white balance图像滤波器的映射函数为:
12、po=(wrri,wggi,wbbi)
13、所述pi=(ri,gi,bi)为输入像素值,po=(ro,go,bo)为输出像素值,所述(r,g,b)分别代表红、绿、蓝颜色通道的值,所述wr、wg、wb分别为红、绿、蓝颜色通道的系数,与ri、gi、bi是对应相乘的关系,该映射为一个乘法变换;
14、所述gamma图像滤波器的映射函数为:
15、po=pig
16、所述pi为输入像素值,所述po为输出像素值,所述g为gamma值,该映射为一个幂变换;
17、所述contrast图像滤波器的映射函数为:
18、po=α·en(pi)+(1-α)·pi
19、所述pi为输入像素值,所述po为输出像素值,所述α为原始图像与完全增强图像之间的线性插值;
20、所述en(pi)定义为:
21、
22、其中:
23、lum(pi)=0.27ri+0.67gi+0.06bi
24、
25、所述sharpen图像滤波器的映射函数为:
26、f(x,λ)=i(x)+λ(i(x)-gau(i(x)))
27、所述i(x)为输入图像,所述gau(i(x))为高斯滤波器,所述λ为一个正的比例因子,通过改变λ值来调整锐化程度。
28、所述目标检测器使用yolox-nan,yolox-nano中引入了深度可分离卷积,只有0.91m的参数量和1.08g浮点运算量,在coco数据集上ap达到25.3%,在小尺寸模型中表现良好。
29、所述s2中训练使用的监督损失为yolox的目标检测损失,其定义为:
30、
31、所述xl为有标注图像,所述c*为类别概率的真实值,所述r*为预测框坐标的真实值,所述o*为置信度的真实值,所述lcls代表分类损失,所述lreg代表定位损失,所述lobj代表obj损失,所述λ代表定位损失的平衡系数,所述npos代表被分配为正样本的锚点数。
32、所述s3中教师模型推理得到的伪标注指基于置信度阈值conf过滤后的预测结果,所述conf是基于置信度定义的,置信度定义为:
33、confi=obj_confi×class_confi
34、所述confi表示第i个目标框的置信度,所述obj_confi表示第i个目标框中存在目标的概率,所述class_confi表示第i个目标框中的目标是某个类别的概率;在置信度的基础上定义置信度阈值conf筛选目标框,某个目标框的confi值大于conf,则该目标框被保留,否则被抛弃;通过调整conf来改变伪标注的保留情况,conf越大,最终得到的伪标注置信度越高。
35、所述s4中模型训练过程所使用的数据增强方法为:
36、首先,每次迭代时输入模型的一批图像中包括有标注图像和无标注图像两个部分,推理之前对该批图像进行数据增强;其中标注图像进行yolox中默认的数据增强,包括mosaic和随机仿射变换;无标注图像进行强数据增强,包括全局颜色变换、coarsedropout、mosaic和随机仿射变换,具体方法如下
37、s4.1、全局颜色变换:equalize、solarize、randombrightness、contrast、sharpen、posterize;
38、s4.2、coarsedropout:随机将图像中矩形区域像素设置为零;
39、s4.3、mosaic:将四张图片拼接至一张图像中作为训练数据;
40、s4.4、仿射变换:rotation、scale、shear、translation;
41、每张图像都按如下顺序进行变换:首先,按照一定概率进行随机全局颜色变换;然后应用coarsedropout矩形丢弃增强器;接下来进行mosaic数据增强,即随机选取3张图像与当前遍历图像拼接至同一张图像中;最后,对mosaic处理后得到的图像按照概率进行随机的仿射变换。
42、所述s4中模型训练过程所使用的无监督损失和监督损失的加权和定义为:
43、loss=losss+lossu=ls(xl,c*,r*,o*)+λulu(a(xu,r*),c*,o*)
44、所述losss和lossu分别代表监督损失和无监督损失,所述λu代表无监督损失权重,所述xl为有标注图像,所述c*为类别概率的真实值,所述r*为预测框坐标的真实值,所述o*为置信度的真实值,所述lcls代表分类损失,所述lreg代表定位损失,所述lobj代表obj损失,所述λ代表定位损失的平衡系数;根据总损失对uw-yolox模型进行参数更新,并不断迭代训练得到最终的最优模型参数;
45、所述监督损失和s2中一致;
46、所述无监督损失为:
47、
48、所述xu代表无标注图像,所述a代表强数据增强,所述分别代表由伪标注得到的类别概率的真实值、预测框坐标的真实值、置信度的真实值,所述xa、分别代表应用强数据增强后的无标注图像和伪预测框;给出了监督损失和无监督损失之间的关系。
49、本发明与现有技术相比,具有的有益效果是:
50、本发明以目标检测损失作为总的损失函数,联合训练视觉增强参数预测模块和目标检测器,针对不同水下图像生成不同且有利于目标检测的视觉增强可调节参数,使得视觉增强模块能够增强图像中有利于目标检测的潜在信息,从而提高水下目标检测的精度。
51、本发明将半监督学习引入水下目标检测,具体来说是将改进的stac半监督学习框架与目标检测器yolox-nano结合。该方法可以充分利用无标注数据进行模型训练,很大程度上减弱了基于深度学习的水下目标检测模型对标注数据的依赖,从而显著提高了少量标注数据下水下目标检测的精度和鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!