一种基于S-HRNet模型的轻量型二维人体姿态估计方法
本发明属于计算机视觉技术,特别涉及一种轻量型二维人体姿态估计方法。
背景技术:
1、二维人体姿态估计主要目标是从图像或视频中推断出人体的关键点位置或区域,例如肩部、膝盖和手腕等。随着神经网络的高速发展,传统的二维人体姿态估计方法由于可扩展性差、对姿态变化不敏感和难以处理复杂背景等问题,已经基本被神经网络的方法所取代。以下是现有的两种轻量型二维人体姿态估计方法:一种方法是small hrnet(smallhigh resolution network,轻量级化高分辨率网络,其基于hrnet(high resolutionnetwork,高分辨率网络)使用了更少的通道数和更小的模型尺寸。另一种方法是spatialshortcut network(ssn,空间快捷网络),其基于resnet(residual network,残差网络)结构提出了一种针对于姿态估计任务的空间连接网络,使信息在空间上的流动更容易。
2、但是上述提到的两种基于神经网络的轻量型二维人体姿态估计方法存在以下问题:第一,对于轻量型网络来说,上述两种网络存在参数量和计算量较高,推理速度较慢的问题,导致人体姿态估计速度较慢;第二,减小网络通道数、尺寸以及以resnet为结构,使网络损失了一些空间语义信息,导致人体姿态估计准确率低。
技术实现思路
1、针对基于hrnet的轻量型人体姿态估计方法参数量、计算量较高、推理速度较慢和基于resnet的轻量型人体姿态估计方法准确度较低的问题,提出了一种基于s-hrnet的轻量型二维人体姿态估计方法,s-hrnet中,s代表small和sandglass结构,hrnet为高分辨率网络;其中,small意思是变得小巧、清凉;sandglss结构意思是将sandglass这个模块用于改进hrnet,sandglass结构可以翻译为沙漏模型。
2、本发明的技术方案为:
3、一种基于s-hrnet模型的轻量型二维人体姿态估计方法,包括以下步骤:
4、s1:下载coco数据集,从coco数据集中取自然场景下的n张人的彩色图像,每张人的彩色图像都包含了人体关键点标签,将这些人的彩色图像随机划分为训练集、验证集和测试集;
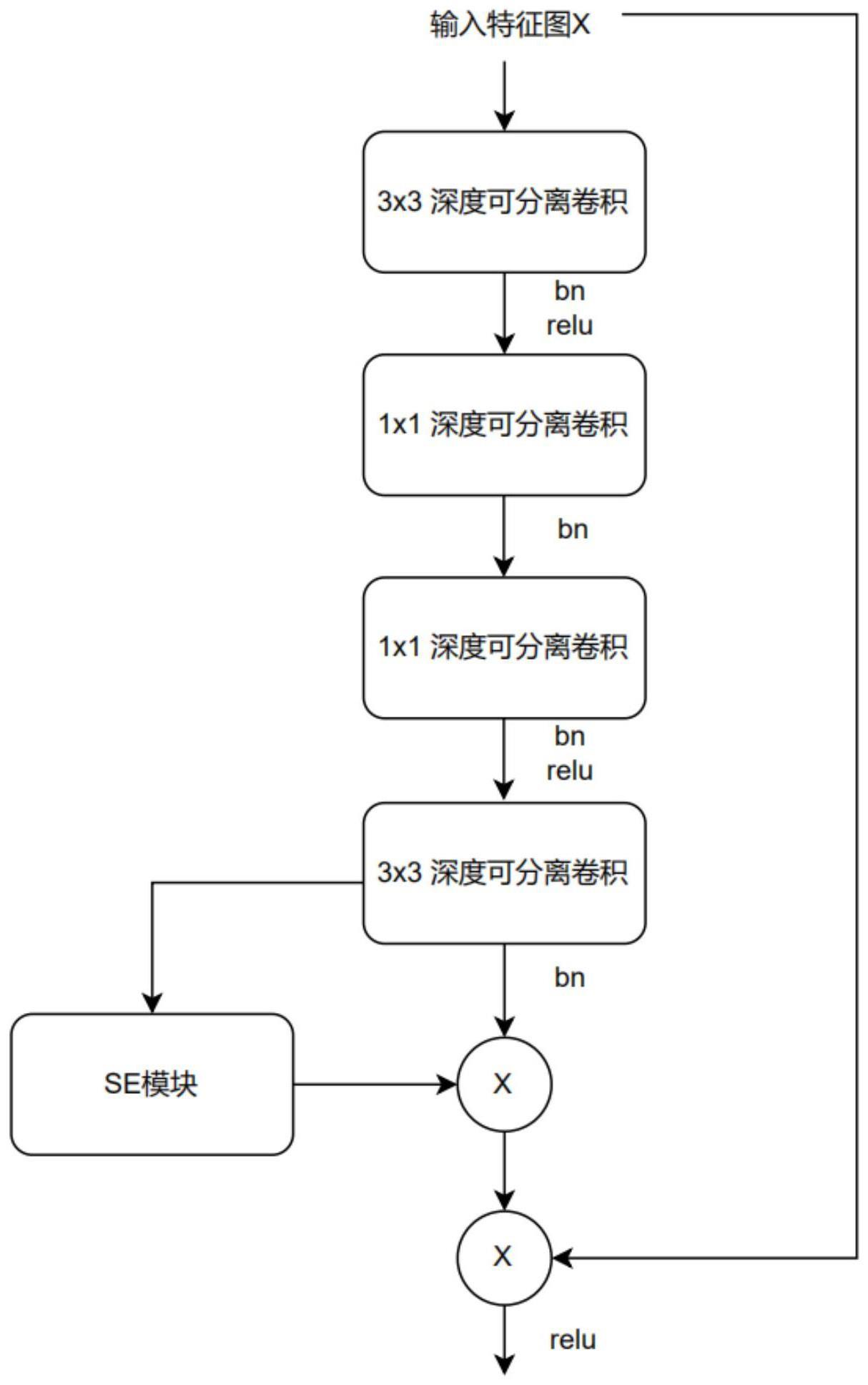
5、s2:对hrnet模型进行轻量化改进得到s-hrnet模型:先将hrnet模型的第一阶段的卷积核扩大;然后将hrnet模型的其余卷积核均替换为深度可分离卷积,再将hrnet模型中的基本块中的resnet结构替换为sandglass结构;最后在基本块中引入注意力机制;得到s-hrnet模型;
6、s3:将训练集中的人的彩色图像输入到s-hrnet模型中进行训练;通过验证集进行验证,得到训练好的s-hrnet模型;
7、s4:将测试集输入训练好的s-hrnet模型;输出人体姿态估计结果。
8、进一步的,步骤s2的具体操作为:
9、s2.1:将hrnet模型的第一阶段的两个3x3卷积分别替换为7x7和5x5卷积;
10、s2.2:将hrnet模型的其余3x3卷积均替换为深度可分离卷积,深度可分离卷积由先进行3x3的深度卷积,再进行1x1的逐点卷积;
11、s2.3:将hrnet模型中的基本块中的resnet结构替换为sandglass结构;在这种sandglass结构中,输入先通过一个下采样操作进行降维处理,然后再通过一个上采样操作进行升维处理,输出的尺寸恢复至与原始输入相同的尺寸;
12、s2.4:在基本块中引入包括挤压和激励两个步骤的注意力机制,以得到具有更强表达能力的特征图;
13、s2.5:对hrnet模型进行步骤2.1-2.4轻量化改进得到s-hrnet模型。
14、进一步的,步骤s2.3的具体操作为:
15、将hrnet模型中的基本块中的resnet结构替换为sandglass结构;
16、sandglass结构由两个方向相反的金字塔状结构组成,在这种sandglass结构中,输入先通过一个下采样操作进行降维处理,然后再通过一个上采样操作进行升维处理,输出的尺寸恢复至与原始输入相同的尺寸。
17、进一步的,步骤s2.4的具体操作为:
18、在基本块中引入注意力机制,以得到具有更强表达能力的特征图;注意力机制由两个步骤组成:挤压和激励;
19、第一个步骤称为挤压:在这一步骤中,全局平均池化操作被应用在输入的特征图上,将每个通道的特征进行降维处理,得到一个单一的数值;
20、第二个步骤称为激励:在这一步骤中,使用一个或多个全连接层或卷积层来对挤压后的特征进行非线性变换;这些层的目的是学习每个通道的权重,即激励值;然后,通过将激励值乘以原始特征,可以调整每个通道的权重,增强有用特征的表示,并抑制无关紧要的特征。
21、进一步的,步骤s3的具体操作为:
22、s3.1:将训练集中的人的彩色图像大小调整为256x192,将人的彩色图像随机分成多个batch,使每个batch中包含batchsize张人的彩色图像,若训练集中的人的彩色图像总数能被batchsize整除,则分成人的彩色图像总数/batchsize个batch,若训练集中的人的彩色图像总数不能被batchsize整除,则将剩余部分舍去,得到︱人的彩色图像总数/batchsize︱个batch,其中本实施例取batchsize=32,︱︱为取整符号;
23、s3.2:为了在训练模型中引入可变性,随机选取一个batch,对所选batch中每张人的彩色图像都进行一系列数据增强操作,数据增强操作包括随机旋转、随机缩放和随机翻转;
24、s3.3:将s3.2中经过数据增强操作后的batch输入到s-hrnet模型中,得到该batch中每张人的彩色图像对应的17张人体关键点预测热图并输出;
25、s3.4:对s3.3中的所选取batch中每张人的彩色图像,分别根据其对应的17张人体关键点预测热图和其对应的17个人体关键点标签,计算每张人的彩色图像的人体姿态估计损失值,并计算得到所选取batch中所有人体姿态估计损失值的平均值作为最终损失值,其中,每张人体姿态估计损失值计算如下公式所示:
26、
27、其中,loss为人体姿态估计损失值计,输入图像的尺寸m=256×192×17,gheatj表示所选取batch中一张人的彩色图像对应的第j个人体关键点预测热图,heatj表示该张人的图像对应的第j个人体关键点预测热图,其中j=
28、1,2,3,…,17;人体关键点标签所标的值与人体关键点是一一对应关系,此处的j即表示第j个人体关键点标签;
29、s3.5:根据s3.4中计算得到的所选取batch中所有人体姿态估计损失值,使用初始学习率为2e-3的adam优化器对s-hrnet模型的参数进行训练,完成所选取batch对s-hrnet模型的训练;
30、s3.6:重复步骤s3.2至s3.5,直至所有的batch都对s-hrnet模型进行一次训练,然后将验证集中所有人的彩色图像输入到此时训练后的s-hrnet模型中,并采用与s3.4相同的方法得到验证集中每张人体姿态估计损失值,计算并得到验证集中所有人的彩色图像的人体姿态估计损失值平均值;
31、s3.7:重复步骤s3.1至s3.6,直至s-hrnet模型在验证集上的损失收敛,最终得到训练好的s-hrnet模型。
32、进一步的,步骤s4的具体操作为:
33、输入测试集内需要进行人体姿态估计的人的彩色图像,将人的彩色图像保持比例拉伸为长256厘米x192厘米的图像,然后将拉伸后的人的彩色图像输入到训练好的s-hrnet模型中,训练好的s-hrnet模型生成17张人体关键点预测热图并输出,将该17张人体关键点预测热图堆叠,每张人体关键点预测热图对应人体的一处关键点坐标位置,堆叠17张就能拼成1张完整的人体关键点热图,完整的人体关键点热图即为人体姿态估计结果。
34、进一步的,步骤s1具体操作为:下载coco数据集,从coco数据集中取自然场景下的n张人的彩色图像,每张人的彩色图像都包含17个人体关键点标签,将这些人的彩色图像随机划分为训练集、验证集和测试集,所有人的彩色图像都是三通道彩色图像。
35、本发明的有益效果在于:
36、低参数量:s-hrnet通过引入轻量型卷积,在保持高准确度的同时大幅减少了参数量。这使得s-hrnet在资源受限的场景中更加实用,例如移动设备和嵌入式系统。
37、低计算量:s-hrnet的设计考虑了计算效率,使用了轻量型架构设计。因此,它能够在较短的时间内完成推理过程,加快了计算速度,提高了实时性。
38、高准确度:尽管s-hrnet在参数量和计算量上进行了优化,但它仍能够在各种计算机视觉任务中取得出色的准确度。通过充分利用hrnet的多尺度特征表示能力,并结合加入的sandglass模块和注意力机制,s-hrnet实现了高水平的性能。
39、可扩展性:s-hrnet的结构具有良好的可扩展性,可以方便地适应不同的任务和数据集。它可以作为计算机视觉研究和应用的基础模块,为未来的发展提供了潜力。
- 还没有人留言评论。精彩留言会获得点赞!