稀疏Cholesky分解硬件加速系统及其求解方法
本发明涉及fpga硬件加速的,尤其是指一种面向嵌入式平台的稀疏cholesky分解硬件加速系统及其求解方法。
背景技术:
1、近年来,稀疏矩阵的cholesky分解方法在嵌入式平台已经得到了较为广泛的应用。稀疏cholesky分解是将稀疏对称正定矩阵分解为一个稀疏矩阵与其转置乘积的方式。目前,移动机器人领域的局部路径规划、实时定位和地图构建等方法均涉及对称正定稀疏矩阵的分解操作,由此产生了对稀疏cholesky算法在嵌入式平台上计算的性能和实时性需求。fpga硬件以其流水线化和资源可重配置的特性,能够为上述稀疏矩阵分解算法提供高效的计算方案,并集成到嵌入式平台的运算流程中,解决当前嵌入式平台处理分解操作时性能受限的问题,为各类上层应用实现硬件加速功能。
2、cholesky分解法使用递归的思想,对于待分解矩阵a,对该矩阵进行分块,可以得到如下公式:
3、
4、其中,a11为矩阵a中位于第1行第1列的元素,a21为矩阵a第1行对角线以下元素的列向量,a22为阶数是n-1的方阵,表示矩阵a除第1行第1列外形成的矩阵,为a21的转置。矩阵a进行cholesky分解的结果同样可以通过以下分块形式表示:
5、
6、其中,l为矩阵a分解结果中的下三角矩阵,lt为l的转置,l11为矩阵l第1行第1列的元素,l21为矩阵l第1行对角线以下元素的列向量,l22为阶数是n-1的方阵,表示矩阵l除第1行第1列外形成的矩阵,为l21的转置,为l22的转置。
7、根据矩阵分解公式a=llt,可以得到以下公式:
8、
9、由此可以求出a22和l21。同样地,对l22的求解也能够使用cholesky方法实现。因此,递归进行上述计算流程,即可完成对a的分解。
10、上述分解方法从待分解矩阵a的第一列开始,顺序向后分解各列,各列的分解依赖于前一列分解对矩阵的修改。对于稀疏矩阵,由于矩阵中大部分位置由零元素填充,一列的分解可能不会对后续各列产生影响。因此,在稀疏cholesky分解过程中,各列一般不存在严格数据依赖关系,这为不同列的并行分解提供了很好的机会。为了实现稀疏矩阵的并行分解,目前针对稀疏cholesky分解方法的软硬件加速系统通常利用multifrontal方法处理各列在分解计算时的数据依赖关系,将计算中间值在依赖图上的结点间传递,以消除对原矩阵读写访问的竞争,从而在各类计算平台上实现分解并行化,提高算法的吞吐量和对硬件资源的利用率。
11、multifrontal方法利用消去树管理各个结点在分解过程中的依赖关系。若将各个列视为图上的一个结点,则可以形成一张称为消去树的依赖关系图。其中,消去树上父结点对应列将依赖于子结点分解过程中对原矩阵的修改。对于分解过程的某一状态而言,将消去树上入度为0的结点表示为一个集合,则该集合中的所有结点可以并行完成分解。在符号分解之后的待分解矩阵a′中,若将当前分解列对角线及对角线以下元素的行索引形成的集合表示为集合r,则消去树中该列子结点对应列只可能对集合e={a′ij|i∈r,j∈r}中的元素产生修改,其中,i,j表示集合r中的元素,a′ij表示待分解矩阵a′中位于第i行第j列的元素。multifrontal方法利用frontal矩阵消除了子结点计算过程中对原矩阵进行更新时的竞争条件。frontal矩阵存储结点分解操作所涉及矩阵元素的最新值,其与上述集合e中元素位置一一对应。结点的分解操作开始时,其从自身frontal矩阵获取元素的最新值。在需要修改后续列矩阵元素时,其将更新值暂存于更新矩阵中,以待更新消去树父结点的frontal矩阵,从而避免其余结点修改原矩阵相同元素时引起的竞争问题。
12、fpga硬件平台能够为稀疏cholesky分解提供性能提升。利用fpga硬件平台的数据流模型,各个模块间可以实现并行化计算。具体而言,fpga硬件中的各个模块间使用fifo通道传递计算中间值,位于通道下游的模块基于fifo通道进行同步,从通道中实时接收上游模块的输出值且并行完成运算,上述模型称为数据流模型。目前,现有基于fpga硬件平台的稀疏cholesky分解加速方案通常面向大规模科学计算问题且针对服务器平台设计。此类方案利用平台资源量充足的特点,将一部分中间结果存储至片上sram中,在单个时钟周期内完成多个元素的运算,达到最大化吞吐量的效果。考虑到嵌入式fpga加速平台一般拥有有限的硬件资源,难以在片上sram中完整存储中间结果,且嵌入式fpga加速平台的内核通过axi总线直接访问主机内存,不需要使用pcie总线及控制器进行数据交换。因此,嵌入式平台和服务器平台部署的fpga硬件加速系统的内存访问和通信模型差异较大,以往针对服务器平台的软硬件设计往往无法简单移植。除此之外,嵌入式平台上运行的计算应用通常处理较小规模的输入,其对延迟更为敏感,不适用以吞吐量为中心的设计方法。因此,有必要针对嵌入式fpga加速平台实现专门的稀疏矩阵cholesky分解软硬件设计,为嵌入式应用提供低延迟和高效率的加速方案。
技术实现思路
1、本发明旨在克服现有稀疏cholesky分解加速硬件设计方案面向嵌入式小规模fpga器件部署时的不足,提出一种面向嵌入式平台的稀疏cholesky分解硬件加速系统及其求解方法,该系统采用fpga和cpu结合的异构计算方式,所提供的技术方案包括fpga侧硬件部分和cpu侧软件部分。该系统将稀疏cholesky分解中可流水线化计算的部分设计于fpga侧硬件部分实现,将调度管理以及辅助数据生成工作设计于cpu侧软件部分实现,以充分发挥fpga并行计算以及cpu随机读写效率的优势。本发明提出的系统降低了硬件复杂度,考虑了嵌入式fpga器件的资源限制,通过fifo通道实现fpga侧硬件部分各个子模块间的数据传递,减少片上bram资源的使用,降低小规模问题的处理延迟,提升了稀疏cholesky分解算法的性能。
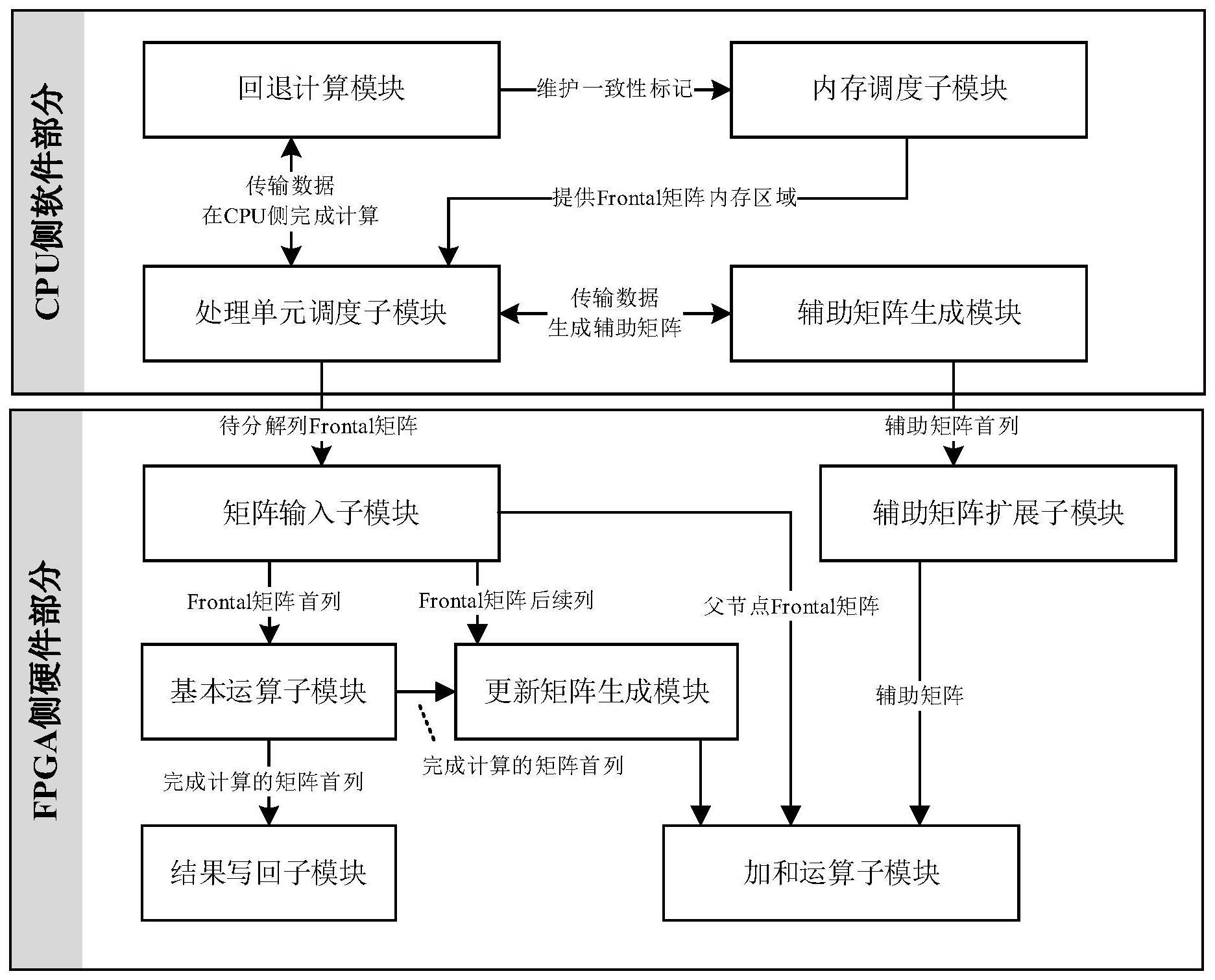
2、为实现上述目的,本发明提供的技术方案为:面向嵌入式平台的稀疏cholesky分解硬件加速系统,包括:
3、fpga侧硬件部分,用于实现稀疏cholesky分解算法中对矩阵单列的分解工作,生成单列的分解结果和更新矩阵;该fpga侧硬件部分利用数据流模型同步不同速率的内部模块,通过fifo通道实现模块间的数据传递,将计算的中间结果以元素为单位推送至通道中,从而实现模块间计算的并行化;
4、cpu侧软件部分,用于接收输入的待分解矩阵信息,输出任务调度序列,在每轮运算中为fpga侧硬件部分分配内存区域、生成辅助数据以及执行按需cpu回退计算工作;该cpu侧软件部分于每一列分解开始时完成内存管理以及辅助数据生成,当待分解列满足fpga侧硬件部分的计算条件时,使用axi总线将上述内存区域的地址及辅助数据传输至fpga侧硬件部分,启动fpga侧硬件部分完成单列分解;反之,该cpu侧软件部分采用cpu回退计算策略,于cpu实现单列分解计算。
5、优选的,所述fpga侧硬件部分包括矩阵输入及基本运算模块、更新矩阵生成模块和扩展加和模块,其中:
6、所述矩阵输入及基本运算模块用于从主机ddr内存中读取待分解矩阵的一列,随后分别对该列的对角线及以下的各个元素执行浮点平方根和除法运算,生成分解结果,最终将结果写回ddr内存的同时推送至fifo通道中;
7、所述更新矩阵生成模块用于从矩阵输入及基本运算模块中接收处理结果,计算结果集合的笛卡尔积以生成元素对集合,进而计算各个元素对自身两个量的乘积;上述乘积将与消去树父结点frontal矩阵相应位置元素相减,生成更新矩阵并推送至连接下游模块的fifo通道;
8、所述扩展加和模块用于从更新矩阵生成模块接收更新矩阵,借助cpu侧软件部分输入的辅助数据以及内存中消去树父结点当前frontal矩阵数据完成稀疏矩阵扩展加和操作,生成消去树父结点新的frontal矩阵,进而通过axi总线将结果写回ddr内存。
9、优选的,所述矩阵输入及基本运算模块包括矩阵输入子模块、基本运算子模块以及结果写回子模块,其中:
10、所述矩阵输入子模块通过axi总线从主机ddr内存中读入指定长度的一段数据,并将该段数据处理后推送至模块内fifo通道中;该矩阵输入子模块启动时,其通过cpu侧软件部分传入的任务控制位判断当前结点是否为消去树中的叶结点;若为叶结点,则该矩阵输入子模块将待分解列所有非零元素输出至fifo通道qff;若不为叶结点,则该矩阵输入子模块将当前结点frontal矩阵的首列与待分解列所有非零元素加和后输出至fifo通道qff,并将当前结点frontal矩阵的后续列输出至fifo通道qfa;由于frontal矩阵为对称矩阵,需要输出的首列元素个数为矩阵的阶数fn,后续列元素个数为fn×(fn-1)÷2;同时,该矩阵输入子模块将消去树上当前结点父结点的frontal矩阵输出至fifo通道qpf;
11、所述基本运算子模块与矩阵输入子模块通过fifo通道qff相连接;基本运算子模块从qff中读入当前结点frontal矩阵首列,读入的第一个元素为该列的对角线元素trig;该基本运算子模块使用平方根逻辑电路计算对角线元素的平方根并将其推送至两个fifo通道ql、qffd;上述两个fifo通道均用于存放当前列分解结果,其中,通道ql与结果写回子模块相连接,通道qffd与更新矩阵生成模块相连接;之后,基本运算子模块对frontal矩阵首列对角线以下的所有元素ti计算浮点数除法ti÷trig,并同样将计算结果推送至上述两个fifo通道ql、qffd中;
12、所述结果写回子模块与矩阵输入子模块通过fifo通道ql相连接;在fpga侧硬件部分启动时,cpu侧软件部分向fpga侧硬件部分传入存放计算结果的内存基址以及当前分解列对应该地址的偏移量,结果写回子模块通过偏移量计算当前分解列对应计算结果存放的实际内存地址,其中,实际内存地址为基址加偏移量得到的地址;之后,该结果写回子模块通过axi总线向该实际内存地址顺序写入ql的元素。
13、优选的,所述更新矩阵生成模块包含待处理元素发送子模块和元素计算子模块,其中:
14、所述待处理元素发送子模块内部使用bram暂存结点frontal矩阵首列元素;启动时,待处理元素发送子模块使用长度为结点frontal矩阵阶数的循环从fifo通道qffd读取首列元素,并将元素依次存储至bram中;完成首列元素存储后,待处理元素发送子模块使用双层嵌套循环向qd推送元素对,其中,qd表示存储首列元素集合笛卡尔积的fifo通道;从fifo通道qffd中接收的元素为ffirst={f1,f2,...,fn},其中,fn表示接收的第n个元素,即下三角frontal矩阵首列的第n个元素,ffirst表示下三角frontal矩阵首列元素的集合;去除对角线元素后,得到集合ff′irst=ffirst\f1={f2,f3,...,fn};嵌套循环用于推送集合中的元素对,其中,x,y为frontal矩阵首列元素的索引,在[2,n]的范围内取得,并分别用于外层和内层循环;表示x,y的取值均为正整数;
15、所述元素计算子模块与待处理元素发送子模块通过fifo通道qd相连接;元素计算子模块从qd中读入待计算元素对(fx,fy),计算元素对浮点乘法结果值m=fx×fy;之后,该元素计算子模块使用长度为更新矩阵元素数量的循环从fifo通道qfa中读入frontal矩阵后续列元素值q,计算q-m的值并将其推送至fifo通道qu,其中,qu表示存储更新矩阵的fifo通道。
16、优选的,所述扩展加和模块包含辅助矩阵扩展子模块以及加和运算子模块,其中:
17、所述辅助矩阵扩展子模块从axi总线中读取cpu侧软件部分输入的辅助矩阵首列,扩展得到完整的辅助矩阵;该辅助矩阵扩展子模块启动时,将读取的辅助矩阵首列元素存入bram中;之后,该辅助矩阵扩展子模块通过辅助矩阵首列元素计算辅助矩阵后续列;辅助矩阵p中的元素取0值或1值,p中行列索引为(r,c)的元素pr,c由首列元素pr,1和pc,1通过逻辑与操作得到;计算得到的辅助矩阵后续列按顺序推送至fifo通道qp中,其中,qp表示存储完整辅助矩阵的fifo通道;
18、所述加和运算子模块与辅助矩阵扩展子模块、矩阵输入及基本运算模块和更新矩阵生成模块分别通过三个fifo通道qp、qpf、qu相连接,具体执行以下操作:加和运算子模块使用长度为父结点frontal矩阵元素个数的循环每次从qp中读入辅助矩阵的一个元素p,若该元素为1值,则说明结果矩阵的对应位置由父结点frontal矩阵元素和更新矩阵元素加和得到,对于此情况,加和运算子模块从qpf和qu中分别读入元素pf、u,计算pf+u的值后通过axi总线将结果写入ddr内存中;若该元素为0值,则说明更新矩阵的对应位置为零元素,对于此情况,加和运算子模块从qpf中读入元素pf,同样通过axi总线将pf写入ddr内存;上述操作实现了稀疏矩阵加和运算。
19、优选的,所述cpu侧软件部分包括辅助矩阵生成模块、并行调度模块和回退计算模块,其中:
20、所述辅助矩阵生成模块用于在子结点中寻找与父结点对应列当前处理行的同行元素,从而生成辅助矩阵的第一列,以供fpga侧硬件部分的扩展加和模块使用;
21、所述并行调度模块用于为fpga侧硬件部分中设计有任意数量计算单元的情形提供任务调度方案和内存资源管理方案,以待求解问题的消去树结构以及fpga侧硬件部分部署的计算单元数量作为输入,返回当前时刻能够并行处理的结点任务集合,并在求解过程中管理系统内固定大小内存区域的所有权,维护内存区域的一致性标记;
22、所述回退计算模块用于从并行调度模块接收计算任务,在cpu侧软件部分计算非零元素密度高的待分解列,并将单列分解结果以及对消去树父结点的更新直接写回ddr内存。
23、优选的,所述辅助矩阵生成模块以当前分解列wi与消去树上父结点对应列wj的元素数据作为输入,输出用于extend-add操作的辅助矩阵p首列;该辅助矩阵生成模块启动时,其遍历列wj的所有行,在列wi中寻找与列wj同行的元素;若找到符合条件的元素,则设置输出的辅助矩阵p首列相应行上的元素为1值,反之设置上述元素为0值。
24、优选的,所述并行调度模块包括处理单元调度子模块和内存调度子模块,其中:
25、所述处理单元调度子模块用于提供高效的任务调度功能,以最大程度开发问题求解过程中的并行性;该处理单元调度子模块以待求解问题的消去树结构以及fpga侧硬件部分部署的计算单元数量作为输入,返回当前时刻能够并行处理的结点任务集合;该处理单元调度子模块在每次返回任务时维护调度相关数据结构,以快速获取更新后的消去树结构中可并行处理的新结点;调度相关数据结构包括任务栈以及每个结点的等待队列;当一个结点从任务栈中被移除时,该处理单元调度子模块将检查结点在消去树上的父结点;若父结点更新后的出度为0,则执行以下判断:若父结点没有其余子结点在任务栈中,则将父结点压入任务栈,否则将父结点放入其消去树中更上一级结点的等待队列;若父结点更新后的出度不为0,则执行以下判断:若父结点的等待队列不为空,则从该队列中取出一个结点放入任务栈;为了在o(1)的时间复杂度内完成以上各项判断,该处理单元调度子模块为每个结点维护一个标记,用于指示当前结点是否有在任务栈中的子结点;每次从任务栈中移除结点时,根据父结点等待队列是否为空的判断结果更新父结点的上述标记;完成调度和维护工作后,该处理单元调度子模块输出能够并行处理的结点任务集合,调用内存调度子模块为各个任务分配frontal矩阵内存空间,生成辅助矩阵,并通过任务中结点对应列的非零元素数量与fpga侧硬件部分部署的bram规模的对比,判断其是否满足于fpga侧硬件部分运行的要求;若满足要求,则处理单元调度子模块为fpga侧硬件部分输入结点frontal矩阵、父结点frontal矩阵、辅助矩阵的内存地址数据,以及指示该结点在消去树中是否为叶结点的任务控制位信息,并启动内核运行;若不满足要求,则该处理单元调度子模块调用回退计算模块,利用cpu完成单列分解计算;
26、所述内存调度子模块包含内存分配器和内存池调度器;其中,内存分配器调用系统库完成初始内存区域分配,内存池调度器接收处理单元调度子模块的请求,处理系统内部内存分配和释放工作;为了在最大程度重利用结点内存空间的同时控制系统整体的内存占用,内存调度子模块首先将结点按其对应列非零元素数量排序,并根据数量大小分为两个类别;同类别结点共享一个内存池中的内存区域;该内存调度子模块管理的内存池中各个内存元素的大小相同,且所有内存元素的大小由其所对应类别中非零元素数量最大的列决定;因此,一个内存元素能在求解过程中的不同时刻被多个任务重复利用;当某结点完成分解工作时,其释放内存空间,并由内存调度子模块放入其所属内存池中;该内存调度子模块中的各个内存池通过栈结构进行管理;在内存池不为空的情况下,该内存调度子模块在收到内存分配请求时向请求者分配的内存区域为最近一次返还的内存空间。
27、优选的,所述回退计算模块包含缓存一致性管理子模块和cpu回退算法子模块,其中:
28、所述缓存一致性管理子模块用于在fpga侧硬件部分和cpu侧软件部分共同读写同一段内存区域时避免cpu缓存导致的潜在不一致问题,管理框架侦听两者在不同内存区域中的读写情况,当一侧读取经过另一侧更新的内存区域时,该缓存一致性管理子模块介入并执行缓存刷新操作以消除一致性问题;该缓存一致性管理子模块为并行调度模块分配的每一段内存区域维护一个一致性标记;在cpu侧软件部分向操作系统申请一段内存区域时,该内存区域首先被初始化为一致状态;当fpga侧硬件部分或cpu侧软件部分对该内存区域进行写入操作时,上述标记将被更新为对应侧的不一致状态;在实际计算过程中,当读取一段内存区域时,该区域的标记若因另一侧先前的写操作被更新为不一致状态,则需要刷写cpu高速缓存以获取最新数据;缓存刷写操作能够保证cpu所有缓存的写操作被正确执行,而新的读操作将从ddr内存中重新请求数据;
29、所述cpu回退算法子模块在cpu侧软件部分实现稀疏cholesky分解算法,其算法流程与fpga侧硬件部分实现完全相同,在实现方式上利用cpu中算法不需要额外传送数据且随机读写内存效率高的特性直接在原先内存区域中完成计算,在单列的分解计算中不引入额外的内存空间;该cpu回退算法子模块从cpu侧软件部分的并行调度模块接收计算任务,按照矩阵输入及基本运算模块、更新矩阵生成模块和扩展加和模块中描述的流程完成单列分解运算;与fpga侧硬件部分部署的模块不同的是,cpu回退算法子模块消除了从ddr内存中间接读取数据的需要,直接对内存进行随机访问和更新;对一段内存区域进行读写操作时,该cpu回退算法子模块将调用缓存一致性管理子模块以保证操作的数据不产生一致性问题;完成计算后,cpu回退算法子模块将结果写入存储计算结果的矩阵对应列以及消去树父结点的frontal矩阵。
30、本发明也提供了上述面向嵌入式平台的稀疏cholesky分解硬件加速系统的求解方法,包括以下步骤:
31、1)cpu侧软件部分从用户端读取待分解矩阵、矩阵符号分解结果以及矩阵消去树结构;
32、2)cpu侧软件部分的并行调度模块获取当前可并行计算的所有列,分配计算任务;辅助矩阵生成模块生成用于扩展加和操作的辅助矩阵的第一列,并将其存储至内存中;并行调度模块随后传输任务数据并启动内核执行;
33、3)fpga侧硬件部分借助设计的数据流模型,从axi总线中按照给定地址偏移量读取ddr内存中的相应数据;fpga侧硬件部分的各模块执行计算任务,并将计算结果通过axi总线写回ddr内存;
34、4)若并行调度模块检测到不满足fpga侧硬件部分运行要求的任务,则回退计算模块在cpu侧软件部分完成单列分解计算,并将计算结果写入ddr内存;
35、5)分解完成列的frontal矩阵占用的内存空间通过内存调度子模块返还至内存池,至此完成一列分解工作;若仍存在待分解的列,则从步骤2)开始重复分解过程,直到矩阵所有列均分解完成。
36、本发明与现有技术相比,具有如下优点与有益效果:
37、1、本发明通过模块间fifo通道实现数据流模型,减少了对fpga侧内存资源的需求,降低了硬件设计复杂度,使本发明提出的设计能够被部署到不同规格的嵌入式fpga开发板中。
38、2、本发明通过模块间fifo通道同步具有不同数据处理速率的模块,实现了各个模块间的并行计算,上游模块处理完成的元素沿fifo通道流向下游模块,大部分模块不需要等待上游模块输出完整计算结果即可启动计算工作,降低了小规模数据的整体处理延迟。
39、3、本发明采用fpga侧硬件部分和cpu侧软件部分联合实现稀疏cholesky分解,将可流水线化和并行化较显著的核心计算部署于fpga侧硬件部分,将对随机读写性能要求较高的调度和内存管理部署于cpu侧软件部分,充分利用了异构平台各个部分的处理能力。
40、4、本发明设计了回退计算模块,该模块配合并行调度模块消除了fpga平台资源规模对其可求解问题的限制,能够在cpu侧软件部分处理fpga侧硬件部分无法求解的问题,为实际应用不同特征的输入提供可靠的求解结果。
41、5、本发明实现了高效的任务调度算法,借助任务栈和各个结点等待队列的设计,使单结点调度工作能够实现o(1)的时间复杂度,减轻了cpu侧软件部分计算资源的压力,提升了稀疏cholesky分解硬件加速系统的整体性能。
- 还没有人留言评论。精彩留言会获得点赞!