一种基于混合注意力与特征增强的文本检测方法
本发明属于计算机视觉文本检测,具体涉及一种基于混合注意力与特征增强的文本检测方法。
背景技术:
1、文本检测作为一种基础性的计算机视觉技术,旨在自动识别和定位图像或视频中的文本区域。它是许多高级计算机视觉和自然语言处理任务的基础,可以应用到文本识别、图像检索、智慧城市系统、场景理解等许多与我们生活息息相关的领域中。
2、尽管深度学习技术的发展提高了文本检测的性能,但在实际应用中,仍然面临着很多挑战和困难,如文本尺寸和方向的变化、遮挡和复杂背景等。因此,对于研究文本相关的检测问题依旧是一个很关键的研究方向。解决掉这些问题,不仅可以提高文本检测的性能,还可以提升其他相关任务的性能,为人们带来更好的使用体验和更广泛的应用场景,让人类在日常生活中处理问题变得更加方便。这就需要依赖于更加精确的文本检测技术,对文本检测技术提出了更高的要求。
3、基于滑动窗口回归的文本检测方法,其主要思想是在图像上滑动固定大小的窗口,然后将窗口中的图像区域分类为文本或非文本。这种方法的优点是简单易懂,容易实现,而且可以很好地适应不同尺度和方向的文本。然而,这种方法的缺点是计算复杂度高,需要对图像进行大量的滑动窗口操作,对于大型图像处理速度较慢,并且存在误检和漏检的问题。另外此方法还需要更多的样本标注,计算量巨大且检测效率不高。它的检测效果主要取决于它获取的特征信息的好坏程度。
4、基于分割方式的文本检测方法能够更加精确地将文本区域和背景等非文本区域进行分割,所以分割方法会达到更好的检测效果。基于分割的检测使用像素级方法来提升文本检测的效果,它将图像含有的所有像素进行判断,将属于相同文本区域的像素分成同一组,从而将不同的文本区域进行有效的区分。textbpn算法使用一种用于任意形状文本检测的新型自适应候选边界网络,它可以学习为任意形状文本生成准确的边界而无需任何后处理,该网络通过一种迭代的方式不断的纠正文本边界,最后得到精确的文本边界。cm-net算法提出一个新的文本构建的表示方法和多视角特征单元,前者可以通过同心掩模拟合任意形状的文本轮廓。后者促进网络从多视角学习更多与同心掩模相关的特征,从而提升网络性能。
5、基于分割的方法相比于回归的方法对于文本的检测有所提升,但还是存在着一些问题。如对于密集区域的小文本分割效果较差,会出现分割区域粘连的情况。复杂背景也会对检测造成相应的误检发生。
6、在现实生活中的文本图像,受到真实场景下复杂背景、光照和拍摄角度的变化等影响,现有方法容易造成小文本的漏检。现有方法中很少关注网络中各层特征之间信息的结合,无法将背景和文本区域进行有效的区分,导致对于图片中小文本区域易发生忽视,产生漏检的情况。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供一种基于混合注意力与特征增强的文本检测方法,提出混合注意力融合模块和自适应特征增强模块去减少背景噪声对文本检测的干扰和提升对小尺度文本的检测能力。
2、为实现上述目的,本发明提供如下技术方案:一种基于混合注意力与特征增强的文本检测方法,包括以下步骤:
3、s1,采集自然场景下的文本图像并对图像进行预处理;
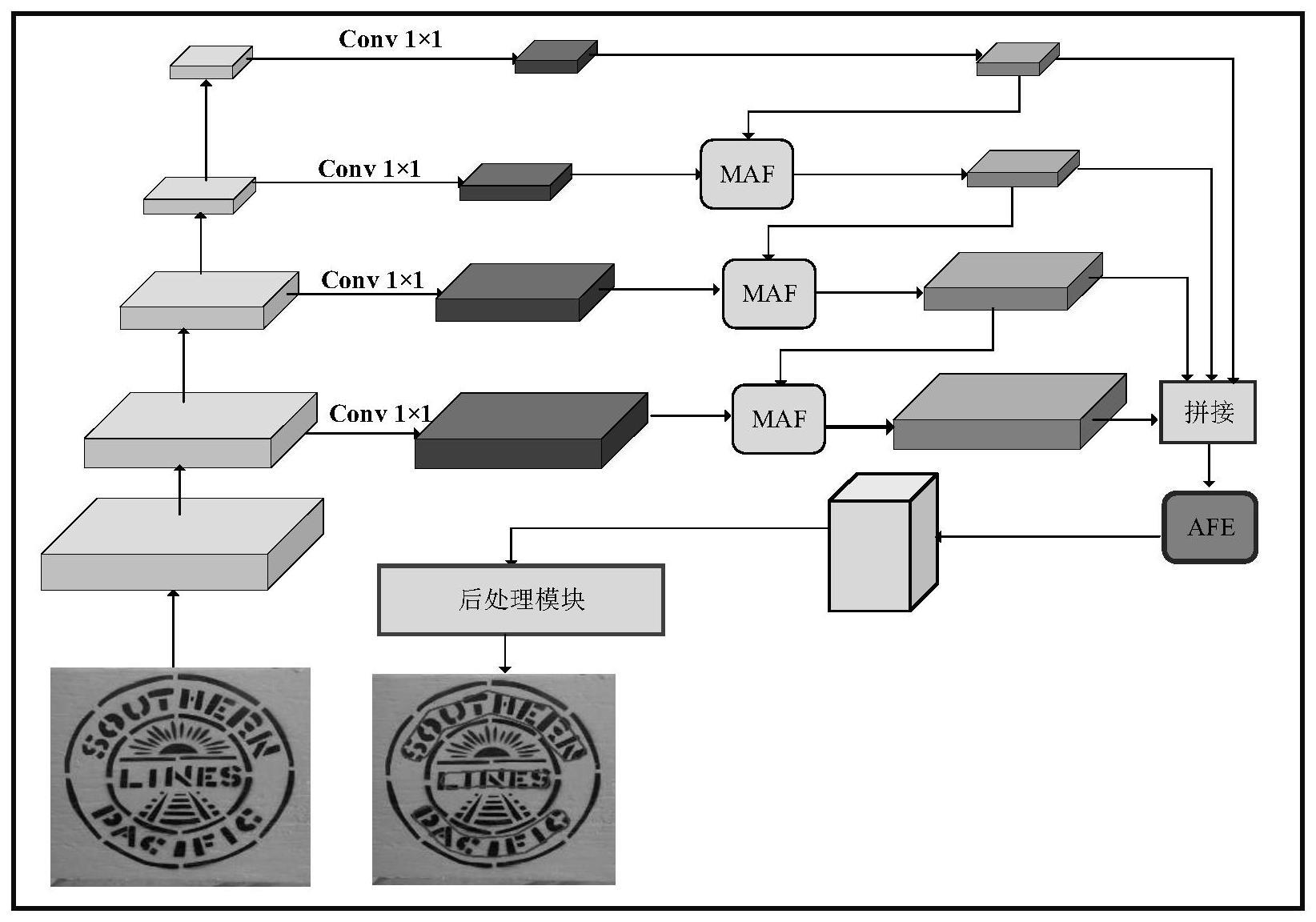
4、s2,采用resnet18作为主干网络,并对其进行修改,将resnet-18的第二层到第五层的普通卷积更换为可变形卷积;将特征送入到fpn中进入特征提取,首先特征经过卷积核为1×1的卷积操作后,各层特征均变成通道数为256维的特征;后续特征会自顶向下的顺序进入到混合注意力融合模块maf模块操作,在maf模块中高层的语义信息作用于底层特征,融合多个特征的上下文信息;
5、s3,输出的多个特征图进行拼接操作后,自适应特征增强模块afe模块使网络的注意权重在空间维度上更加灵活,捕捉到特征信息。
6、进一步的,步骤s2包括:
7、混合注意力融合模块的输入为pi和outi+1,p为此层特征,out为下一层特征的结果;计算过程如公式(1)表示:
8、
9、其中,代表特征元素相加,代表特征元素相乘,up表示双线性插值操作;cm和sm表示通道维度的注意力和空间维度上的注意力;
10、通道维度上的注意力是通道维度不进行改变,而对空间维度进行压缩操作;该模块将输入的特征图经过两个并行的最大池化层和平均池化层,将特征图从c×h×w变为c×1×1的大小,然后经过mlp模块;在该模块中,它先将通道数压缩为原来的1/r倍,再扩张到原通道数,经过relu激活函数得到两个激活后的结果;将这两个输出结果进行逐元素相加操作;之后再通过一个sigmoid激活函数得到输出结果;
11、空间注意力模块则是空间维度不进行任何改变,而通道维度进行相应的压缩操作,之后再去学习空间维度上的特征信息;该模块关注的是目标的位置信息;即将输入的特征图像通过最大池化和平均池化操作得到两个1×h×w的特征图;然后经过连接操作对两个特征图进行拼接,之后再通过一个7×7卷积操作变为通道数为1的特征图,再经过一个sigmoid得到空间注意力的特征图,最后将输出结果乘原图之后变回c×h×w大小;特征信息经过这两种注意力的运算,对其浅层细节信息和深层语义信息进行相结合。
12、进一步的,步骤s3包括:
13、先输入的特征拼接在一起,如公式(2)表示;然后进入到自适应特征增强模块,首先通过卷积核为3×3的卷积,再经过一系列操作,之后再与s相加后生成t(s),如公式(3)所示。
14、之后,t(s)再进行卷积、relu、卷积、sigmoid操作后生成的结果,再与原t(s)相加之后生成k(s),如公式(4)所示。
15、由公式(5)表示,最终生成output特征图送入到后处理模块进行操作。
16、s=concat([out2,out3,out4,p5]) (2)
17、
18、
19、
20、其中,avg表示为平均池化操作,conv3代表卷积核为3×3的卷积操作,conv1代表卷积核为1×1的卷积操作;relu表示为relu激活函数,σ表示为sigmoid激活函数,和分别表示两个特征图对应元素进行相加或相乘的操作。
21、与现有技术相比,本发明的有益效果是:
22、1)本发明提出一种混合注意力融合模块,该模块在特征金字塔部分对特征信息的提取进行帮助和提升,注意力模块可以有效地获取特征图像的上下文信息,通过融合局部细节和全局文本信息,可以降低背景噪声对检测的干扰和提升网络对易忽略小文本的关注度。
23、2)本发明提出一种自适应特征增强模块,该模块通过对金字塔输出后的特征进行学习,使网络自适应去掌握不同尺度和不同位置特征信息的重要性。特征进行动态的聚合,进而提升网络模型对小尺度文本的检测能力。
24、3)在两个公共数据集上进行消融实验并与其他优秀方法进行对比试验,本发明所提的方法对文本检测都有明显的提升。
- 还没有人留言评论。精彩留言会获得点赞!