批量数据匹配方法、装置、设备及存储介质与流程
本发明涉及数据匹配,尤其涉及一种批量数据匹配方法、装置、设备及存储介质。
背景技术:
1、随着互联网的快速发展,网购逐渐替代了人们的日常生活购物,即线上购物的比例逐渐超过线下购物的比例,线上购物带来的物流订单大批量增长。
2、目前物流包裹的所有信息都由包裹上所粘贴的面单所承载,但在承接大批量的配送过程中,存在需要根据某些条件匹配大批量运单的情况,比如:当出现极端天气时,需要以极端天气所在地区的位置信息为条件大批量匹配运单,以拦截该地区的收发件。
3、现有的物流数据管理系统中,当需要进行大批量数据匹配时,由于业务影响导致匹配逻辑较为复杂,因此,无法实现及时返回匹配结果的目标,即存在匹配效率低的问题,无法做到及时响应。
4、可见,现有技术还有待改进和提高。
技术实现思路
1、为了克服现有技术的不足,本发明的目的在于提供一种批量数据匹配方法、装置、设备及存储介质,通过elasticsearch引擎和java进行基础数据的匹配,具有匹配效率高、匹配准确性高的优点,可达到及时响应的目的。
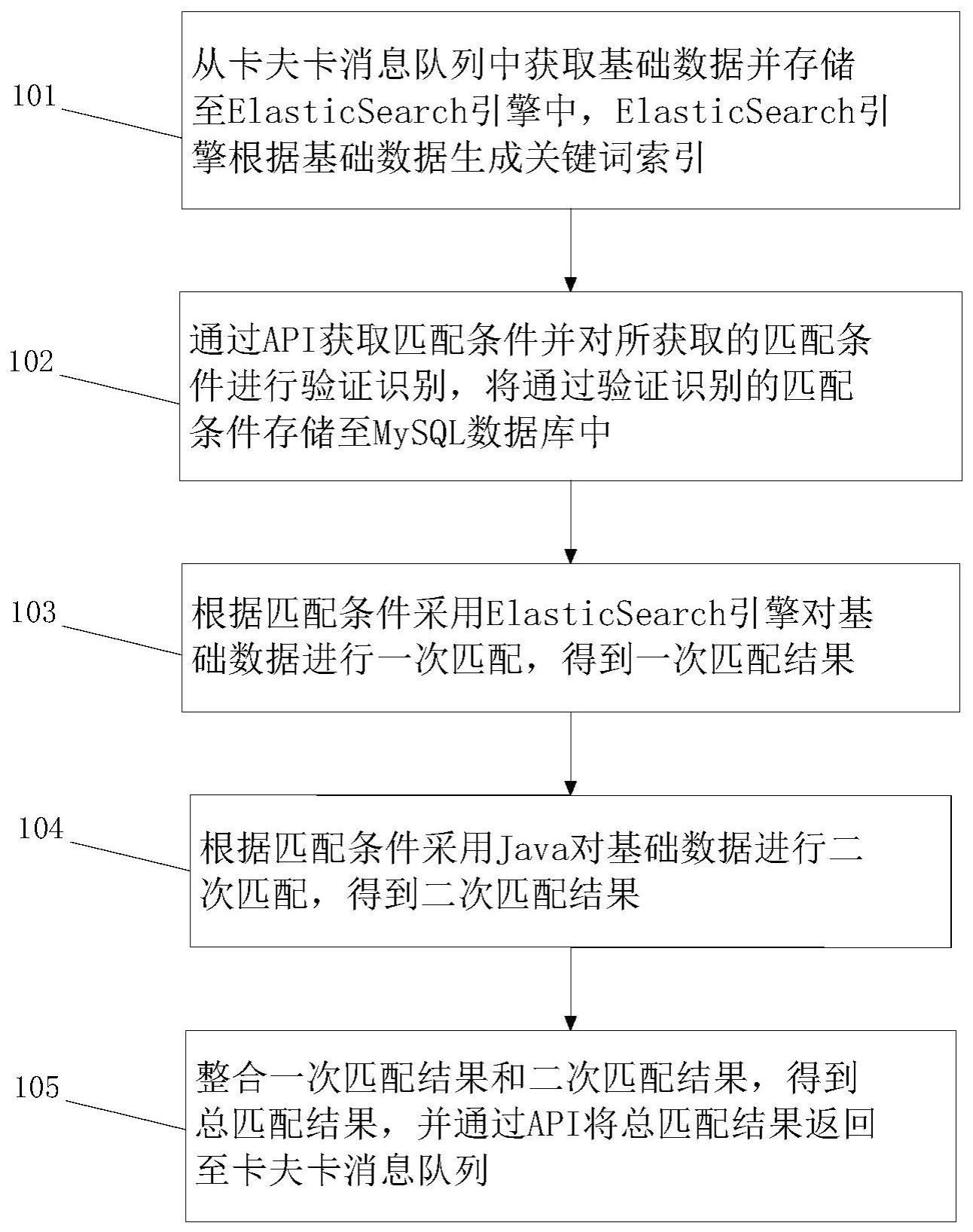
2、本发明第一方面提供了一种批量数据匹配方法,包括:从卡夫卡消息队列中获取基础数据并存储至elasticsearch引擎中,elasticsearch引擎根据基础数据生成关键词索引;通过api获取匹配条件并对所获取的匹配条件进行验证识别,将通过验证识别的匹配条件存储至mysql数据库中;根据匹配条件采用elasticsearch引擎对基础数据进行一次匹配,得到一次匹配结果;根据匹配条件采用java对基础数据进行二次匹配,得到二次匹配结果;整合一次匹配结果和二次匹配结果,得到总匹配结果,并通过api将总匹配结果返回至卡夫卡消息队列。
3、可选的,在本发明第一方面的第一种实施方式中,所述从卡夫卡消息队列中获取基础数据并存储至elasticsearch引擎中,具体包括:配置filebeat获取日志文件的路径,通过filebeat从卡夫卡消息队列中采集日志数据;配置logstash的服务主机和端口,采用logstash对filebeat所采集的日志数据进行解耦和预处理,得到基础数据;配置logstash的output为elasticsearch,将基础数据存储至elasticsearch引擎中。
4、可选的,在本发明第一方面的第二种实施方式中,所述elasticsearch引擎根据基础数据生成关键词索引,具体包括:采用elasticsearch引擎将基础数据所包括的文档序列化成json格式,并获取json对象;采用分词模型获取json对象所包括的类型关键词,根据类型关键词生成类型索引;通过hash算法对类型索引进行分片处理,得到关键词索引,并对关键词索引进行副本复制处理。
5、可选的,在本发明第一方面的第三种实施方式中,所述通过api获取匹配条件并对所获取的匹配条件进行验证识别,将通过验证识别的匹配条件存储至mysql数据库中,具体包括:通过api获取匹配条件,所述匹配条件包括唯一的任务id;采用kmp算法匹配所获取的任务id以及预设的用户id表,以对匹配条件进行验证识别;当预设的用户id表内存在与所获取的任务id一致的id时,表明通过验证识别,将匹配条件存储至mysql数据库中。
6、可选的,在本发明第一方面的第四种实施方式中,所述根据匹配条件采用elasticsearch引擎对基础数据进行一次匹配,得到一次匹配结果,具体包括:采用提取模型对匹配条件进行关键词提取处理,得到多个匹配关键词;
7、随机组合多个匹配关键词,得到多个组合条件;采用elasticsearch引擎,逐次选取任一组合条件对基础数据进行轮询匹配;当完成多个组合条件的轮询匹配后,得到一次匹配结果。
8、可选的,在本发明第一方面的第五种实施方式中,所述根据匹配条件采用java对基础数据进行二次匹配,得到二次匹配结果,具体包括:导入正则表达式包,根据匹配关键词,采用compile方法生成正则表达式模式;基于正则表达式模式,采用matches方法对基础数据进行匹配,得到第一匹配结果;基于正则表达式模式,采用find方法对基础数据进行匹配,得到第二匹配结果;整合第一匹配结果和第二匹配结果,得到成二次匹配结果。
9、可选的,在本发明第一方面的第六种实施方式中,所述整合一次匹配结果和二次匹配结果,得到总匹配结果,并通过api将总匹配结果返回至卡夫卡消息队列,具体包括:整合一次匹配结果和二次匹配结果,得到总匹配结果;关联总匹配结果和匹配任务,生成匹配文件,将匹配文件存储于mysql数据库中;关联总匹配结果和匹配任务的任务id,生成返回文件,通过api将返回文件返回至卡夫卡消息队列。
10、本发明第二方面提供了一种批量数据匹配装置,包括:获取模块,用于从卡夫卡消息队列中获取基础数据并存储至elasticsearch引擎中,elasticsearch引擎根据基础数据生成关键词索引;识别模块,用于通过api获取匹配条件并对所获取的匹配条件进行验证识别,将通过验证识别的匹配条件存储至mysql数据库中;第一匹配模块,用于根据匹配条件采用elasticsearch引擎对基础数据进行一次匹配,得到一次匹配结果;第二匹配模块,用于根据匹配条件采用java对基础数据进行二次匹配,得到二次匹配结果;返回模块,用于整合一次匹配结果和二次匹配结果,得到总匹配结果,并通过api将总匹配结果返回至卡夫卡消息队列。
11、可选的,在本发明第二方面的第一种实现方式中,所述获取模块包括:第一获取单元,用于配置filebeat获取日志文件的路径,通过filebeat从卡夫卡消息队列中采集日志数据;处理单元,用于配置logstash的服务主机和端口,采用logstash对filebeat所采集的日志数据进行解耦和预处理,得到基础数据;第一存储单元,用于配置logstash的output为elasticsearch,将基础数据存储至elasticsearch引擎中。
12、可选的,在本发明第二方面的第二种实现方式中,所述获取模块还包括:第二获取单元,用于采用elasticsearch引擎将基础数据所包括的文档序列化成json格式,并获取json对象;分词单元,用于采用分词模型获取json对象所包括的类型关键词,根据类型关键词生成类型索引;分片单元,用于通过hash算法对类型索引进行分片处理,得到关键词索引,并对关键词索引进行副本复制处理。
13、可选的,在本发明第二方面的第三种实现方式中,所述识别模块包括:第三获取单元,用于通过api获取匹配条件,所述匹配条件包括唯一的任务id;第一匹配单元,用于采用kmp算法匹配所获取的任务id以及预设的用户id表,以对匹配条件进行验证识别;识别单元,用于当预设的用户id表内存在与所获取的任务id一致的id时,表明通过验证识别,将匹配条件存储至mysql数据库中。
14、可选的,在本发明第二方面的第四种实现方式中,所述第一匹配模块包括:提取单元,用于采用提取模型对匹配条件进行关键词提取处理,得到多个匹配关键词;组合单元,用于随机组合多个匹配关键词,得到多个组合条件;第二匹配单元,用于采用elasticsearch引擎,逐次选取任一组合条件对基础数据进行轮询匹配;第一整合单元,用于当完成多个组合条件的轮询匹配后,得到一次匹配结果。
15、可选的,在本发明第二方面的第五种实现方式中,所述第二匹配模块包括:生成单元,用于导入正则表达式包,根据匹配关键词,采用compile方法生成正则表达式模式;第三匹配单元,用于基于正则表达式模式,采用matches方法对基础数据进行匹配,得到第一匹配结果;第四匹配单元,用于基于正则表达式模式,采用find方法对基础数据进行匹配,得到第二匹配结果;第二整合单元,用于整合第一匹配结果和第二匹配结果,得到成二次匹配结果。
16、可选的,在本发明第二方面的第六种实现方式中,所述返回模块包括:第三整合单元,用于整合一次匹配结果和二次匹配结果,得到总匹配结果;关联单元,用于关联总匹配结果和匹配任务,生成匹配文件,将匹配文件存储于mysql数据库中;返回单元,用于关联总匹配结果和匹配任务的任务id,生成返回文件,通过api将返回文件返回至卡夫卡消息队列。
17、本发明第三方面提供了一种批量数据匹配设备,所述批量数据匹配设备包括:存储器和至少一个处理器,所述存储器中存储有指令;至少一个所述处理器调用所述存储器中的所述指令,以使得所述批量数据匹配设备执行上述任一项所述的批量数据匹配方法的各个步骤。
18、本发明的第四方面提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有指令,所述指令被处理器执行时实现上述任一项所述批量数据匹配方法的各个步骤。
19、本发明的技术方案中,通过获取基础数据并存储至elasticsearch引擎中,elasticsearch引擎根据基础数据生成关键词索引;通过api获取匹配条件,根据匹配条件采用elasticsearch引擎对基础数据进行一次匹配,并根据匹配条件采用java对基础数据进行二次匹配,整合一次匹配结果和二次匹配结果,得到总匹配结果,并通过api将总匹配结果返回至卡夫卡消息队列;本技术公开的方法,通过api和卡夫卡消息中心配合获取匹配条件并返回匹配结果,可实现异步处理,减少api响应时间,并提高系统的吞吐量;通过elasticsearch引擎和java进行基础数据的匹配以获取匹配结果,具有匹配效率高、匹配准确性高的优点,大大缩短了响应时间。
- 还没有人留言评论。精彩留言会获得点赞!