一种基于轻量表情识别模型的课堂专注度检测方法及装置
本发明属于智慧课堂专注度检测领域,具体涉及一种基于轻量表情识别模型的课堂专注度检测方法及装置。
背景技术:
1、实时获取学生的课堂状态对于现代课堂至关重要,大量研究人员试图通过无接触的形式实现专注度的自动检测,使用深度学习方法是其中热门的研究方向。
2、随着近些年深度学习在图像识别领域的广泛应用,无论是实现物体的识别与分类,还是对人脸的检测,对诸如年龄、表情的人脸属性进行识别,都为后面基于深度学习的方法进行学生课堂状态检测提供了技术基础。在教育学领域,研究者将表情与学生的课堂参与度进行了关联。学生的面部表情是课堂上最常用的非语言交流模式,可以较为清晰地反映出学生在课程中此时的情绪,这有助于教育者识别他们对课堂的理解与能否良好的参与其中。进一步在理论的基础上结合社会实验,对理论进行验证和补足,将表情切实映射到相应的参与水平上。这些研究,为通过深度学习的方法进行学生课堂状态检测提供理论基础。
3、深度学习的核心在于构建网络模型,模型的大小通常用模型参数量来衡量。该领域的现有方法,为获得更佳的表现,更多的是基于较大尺寸的模型,这也就意味着更多的参数量与计算量。然而对于检测学生课堂状态的应用场景来说,模型可能需要在边缘设备、移动平台或不配备高性能gpu的设备上部署,因此现有方法难以满足实际的应用场景,更多的是停留在理论与实验层面。
技术实现思路
1、针对上述问题,本发明提出了一种基于轻量表情识别模型的课堂专注度检测方法及装置。一是基于表情识别实现对学生的课堂专注度检测;二是通过轻量化的思想方法构建轻量表情识别模型,通过使用深度可分离卷积、分组卷积、倒瓶颈结构和残差链接构建目标模型,在不降低准确率的前提下实现整体系统参数量和计算量的降低,以满足灵活部署的需求。
2、按照本发明提供的技术方案,提出了一种基于轻量表情识别模型的课堂专注度检测方法包括以下步骤:
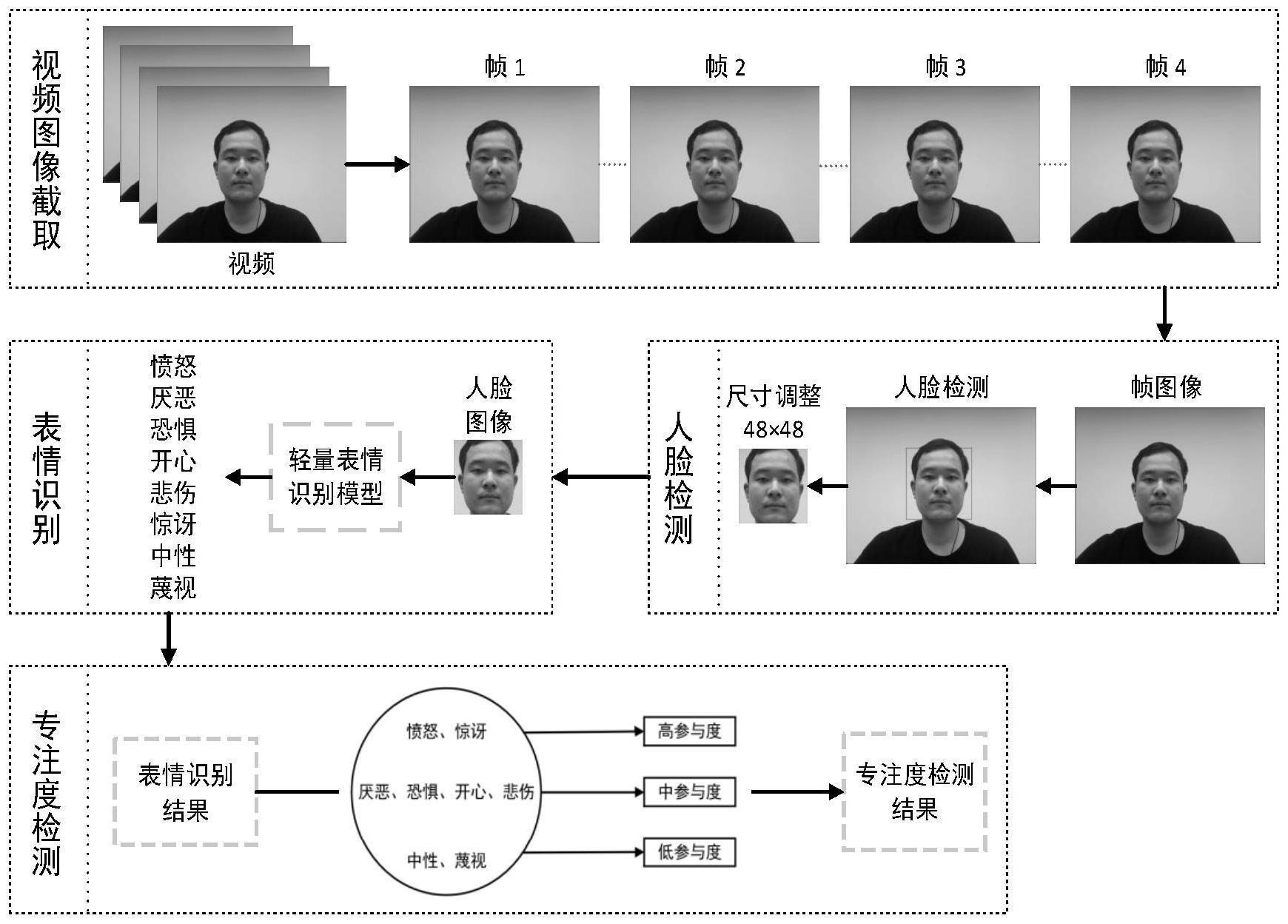
3、步骤1、获取学生的课堂视频,通过跨平台计算机视觉库opencv将视频截取为单独的帧图像。
4、步骤2、通过人脸检测算法检测出课堂帧图像中所包含的人脸,并通过方框标注出来,再将人脸部分图像剪裁并调整为统一大小,得到人脸图像。
5、步骤3、将人脸图像送入预训练后的轻量表情识别模型中,得出相应的表情识别结果。
6、步骤4、根据表情与参与度的关系,将表情分类结果对应到高、中、低三档参与度水平中的一种,实现基于表情识别的课堂专注度检测。
7、所述步骤1中,所述学生课堂视频为摄像机所捕获的学生在上课过程中的课堂学习视频。所述帧图像截取功能,通过opencv中的视频捕获函数videocapture实现,它读取输入的视频内容,并按需将视频截取为帧图像。
8、所述步骤2中,所述人脸检测算法是opencv中的哈尔级联检测器haarcascade人脸检测算法,基于哈尔haar特征和自适应提升算法adaboost级联分类器,可以实现检测所述基于课堂视频截取的帧图像中的人脸。
9、根据所述人脸检测算法所得检测结果,可以获取图像中的人脸坐标,使用opencv将人脸截取人脸部分图像。再使用调整尺寸resize函数,将不同尺寸的人脸部分图像调整为统一尺寸大小。
10、所述的步骤3中,所述轻量表情识别模型的表情识别范围为愤怒、厌恶、恐惧、开心、悲伤、惊讶、中性、蔑视这8类表情。
11、所述轻量表情识别模型的具体构成包括:
12、(1)所述轻量表情识别模型包括第一提取单元、第二提取单元和分类单元,所述第一提取单元用于初步提取图像特征,所述第二提取单元用于深度提取所述第一提取单元所提取的特征,所述分类单元用于分类所述第二提取单元所提取的特征。
13、(2)所述第一提取单元包括2个卷积层,每个卷积层后连接一个批归一化层和mish激活函数,输入人脸图像经过第一特征提取单元提取得到特征图d1。
14、(3)所述第二提取单元包括四个分组倒瓶颈残差块,每个所述分组倒瓶颈残差块后连接1个卷积块注意力模块cbam,每个卷积注意力模块由空间注意力模块和通道注意力模块组成。
15、(4)所述分组倒瓶颈残差块包括左右两条通路。左侧通路依次串联2个分组倒瓶颈结构和最大池化层,每个所述分组倒瓶颈结构后连接一个批归一化层。右侧通路为卷积核尺寸为1*1的卷积层,后面连接一个批归一化层,构成残差连接。所述特征图d1分别经过左右通路运算,然后按元素进行加和处理。经过四层所述分组倒瓶颈残差块运算,得到特征图d2。
16、(5)所述分组倒瓶颈结构由倒瓶颈结构进行分组数为2的分组卷积操作构成。所述倒瓶颈结构包括三层深度可分离卷积,分别为扩展层、保持层与缩减层。所述扩展层通过所述深度可分离卷积增加通道数量,使所述保持层的通道数量为所述缩减层通道数量的2倍;所述保持层用于维持扩充后的通道数量不变;所述缩减层用于减少通道数量以匹配后续操作。在所述扩展层和所述保持层后依次连接批归一化层和mish激活函数。
17、进一步将所述倒瓶颈结构进行分组数为2的分组卷积操作,即所述倒瓶颈结构在通道维度上为2组,输入到每组的特征图的通道数量为输入到所述分组倒瓶颈结构的特征图通道数量的一半,分别运算后在通道维度上进行接合。
18、(6)所述深度可分离卷积将常规卷积分解为深度卷积和点卷积。所述深度卷积在空间维度上进行运算,每个特征图的通道都由一个独立的卷积核进行卷积,改变特征图的宽与高,维持通道数量不变。所述点卷积对经过所述深度卷积运算后的特征图运算,在通道维度上进行,通过卷积核大小为1*1的卷积,改变特征图通道数量。
19、(7)所述分类单元包括常规卷积、所述通道注意力模块、全局平均池化和softmax(归一化指数函数)函数,对所述第二提取单元所提取到的所述特征图d2进行分类,得到相应的表情分类结果。
20、所述训练好的轻量表情识别模型是基于ferplus数据集。通过配置相关训练超参数,训练模型直到满足终止条件为止,得到可以直接调用的轻量表情识别模型。
21、所述的步骤4中,教育学领域相关研究人员通过理论分析与社会实验,得到所述的表情与专注度的对应关系,将不同种类的表情对应到高、中、低三档参与度水平中,其中愤怒、惊讶对应高等专注度、厌恶、恐惧、开心、悲伤对应中等参与度,中性、蔑视对应低等参与度。根据所述轻量表情识别模型得到的表情识别结果和表情与专注度的对应关系,可以实现基于表情的课堂专注度检测,并可以较小的性能开销灵活部署在不同设备上。
22、本发明另一方面,一种基于轻量表情识别模型的课堂专注度检测方法及装置包括图像处理模块、表情识别模块和专注度评价模块。
23、图像处理模块,用于采集目标上课时的课堂视频,并处理为帧图像。
24、表情识别模块,标注出帧图像中的人脸图像,并基于轻量表情识别模型,对人脸图像进行表情识别,得到课堂表情信息。
25、专注度评价模块,根据课堂表情信息,结合参与度,确定目标对象上课时的课堂专注度。
26、本发明有益效果如下:
27、利用深度可分离卷积、分组卷积和softmax分类方法,减少了模型的参数量与性能开销;使用深度可分离卷积、倒瓶颈结构、残差链接与注意力机制,使模型在降低参数量的同时维持了较高的准确率;结合教育学领域表情与参与度的关系,实现了表情到专注度水平的映射。本发明比以往的研究在不降低准确率的前提下,减少了参数量,降低了运算开销,可以灵活部署在不同设备上进行专注度检测。
- 还没有人留言评论。精彩留言会获得点赞!