本发明属于音视显著性检测方法的,特别涉及基于双流网络结构的音视显著性检测方法。
背景技术:
1、音视显著性检测(avsd)是为了在视觉-音频环境中模拟人类的注意力机制,突出在视觉和音频源中同时显著的视频区域。现有的音视显著性检测方法主要采用双流网络架构,分别计算音频显著性和视频显著性,然后融合音频和视频两个模态的结果作为最终输出,其常存在当音频信号与视频信号不一致时,音频显著性无法与视频显著性互补的现象,即音视一致性欠感知的现象,例如,视频图像为两个人在说话,同时的音频中,具有来自外部的背景音乐,这种情况下,音频信号在确定显著性区域时不能对视频显著性检测提供有效帮助,反而会带来冗余、错误信息。
2、如果采用的avsd模型欠缺音视一致性感知,则该模型在显著性检测中是否应当融合音视信息或者应当融合多少音视信息是不可知的,由此很难实现最佳的音视融合,导致在面对微弱的音频信号时,融合音频信息和视频信息的avsd模型反而不如单独使用视频信息的模型。因此,获得一种可准确判断或预测当前音频和视频是否具有一致性即具有音视一致性感知能力的avsd方法是现有技术亟需解决的问题。
技术实现思路
1、针对现有技术的缺陷,本发明的目的在于提供一种新的音视显著性检测方法,该检测方法具有音视一致性感知能力,并可基于音视一致性感知情况选择性地融合音视流和视频流,获得更为准确优异的检测结果。
2、本发明的技术方案如下:
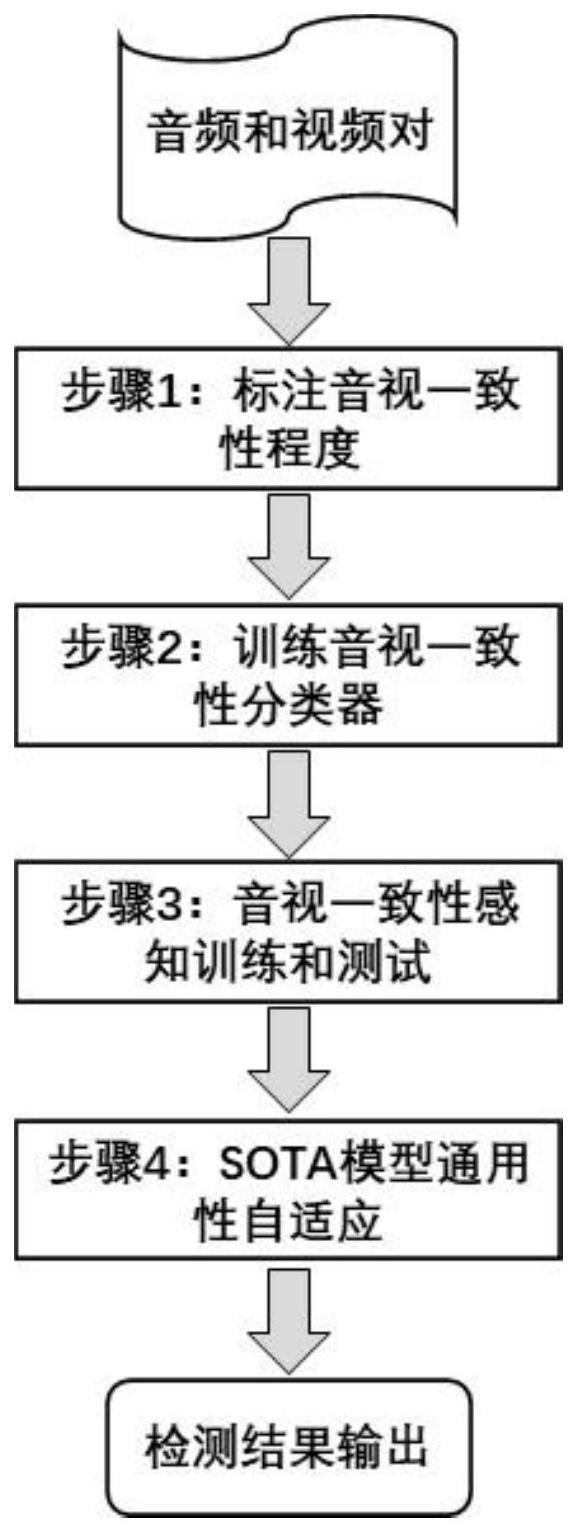
3、基于音视一致性感知的音视显著性检测方法,其包括:
4、s1根据音视频数据库中配对的音频和视频之间的关联程度,对音频和视频进行基于0/1二值的一致性标注,得到一致性标注数据,同时保留原音视频数据库中配对的音频和视频之间的显著性真值,共同组成标注后的音视频数据集;
5、s2基于所述标注后的音视频数据集中的所述一致性标注数据构建音视频一致性分类器,所述音视频一致性分类器使用对音频和视频的一致性进行检测的一致性检测模型;
6、s3构建基于音视频一致性分类器输出结果的音视频融合判断模型,所述融合判断模型可预测待进行音视显著性检测的视频和音频是否需要进行融合;
7、s4将所述一致性分类器及所述融合判断模型集成于第一音视显著性检测模型中,并对得到的集成后的音视显著性检测模型即第二音视显著性检测模型进行音视一致性感知训练,通过训练后或训练和测试后的第二音视显著性检测模型获得显著性检测结果,即基于音视一致性感知的音视显著性检测结果,其中,所述音视一致性感知训练包括通过所述一致性标注数据对音视频一致性分类器进行的训练及通过所述显著性真值对第一音视频显著性检测模型进行的训练,两者使用联合的损失函数;所述第一音视频显著性检测模型使用现有的可对音频和视频之间的显著性进行检测的模型。
8、根据本发明的一些优选实施方式,所述一致性标注包括:当配对的音频与视频时间对齐后,若音频中某时刻的声音由该时刻的视频中的显著目标发出,则认为该时刻的音频和视频具有关联,将其关联程度即一致性赋值为1,若音频中某时刻的声音不由该时刻的视频中的显著目标发出,则认为该时刻的音频和视频不具有关联,将其关联程度即一致性赋值为0。
9、根据本发明的一些优选实施方式,所述标注后的音视频数据集组成如下:
10、{ai,vi,lsi,lci}→{ai,vi,lsi,lci},lci∈{0,1},i∈[1,n],
11、其中,ai,vi表示配对的音频和视频,即音视频对,lsi表示音视频数据库中原有的音视显著性真值,即显著性视点图,lci表示新标注的音视频一致性值,n表示总的音视频对数量。
12、根据本发明的一些优选实施方式,所述音视频一致性分类器包括输入层、与输入层相连的视频特征提取模块和音频特征提取模块、与视频特征提取模块和音频特征提取模块相连的特征融合模块、与特征融合模块相连的全连接层、及与全连接层相连的输出层;其中,所述视频特征提取模块由3dresnet网络构成,所述音频特征提取模块由soundnet网络构成,所述特征融合模块由矩阵加法操作构成。
13、根据本发明的一些优选实施方式,所述视频特征提取模块由含注意力机制的四层3dresnet网络构成,每层均由resnet50网络形成。
14、根据本发明的一些优选实施方式,所述音频特征提取模块由通过视觉和声音自监督联合训练的soundnet网络构成。
15、根据本发明的一些优选实施方式,通过所述视频特征提取模块进行视频特征提取的过程包括:由四层3dresnet网络的每层网络对输入的编码后视频帧进行特征提取,分别得到一个时空尺度下的视频特征xm(m=1,…,4);在四层3dresnet网络间增加注意力机制,对每层输出的视频特征xm(m=1,…,4)进行注意力筛选。
16、根据本发明的一些优选实施方式,通过所述音频频特征提取模块进行音频特征提取的过程包括:将输入的音频波形进行海明窗加窗处理,得到当前音频信号波形位置得到强调的音频段数据,通过soundnet网络的前七层对音频段数据进行编码提取,得到音频特征。
17、根据本发明的一些优选实施方式,所述音频波形为梅尔频谱处理后的音频波形,其通过预训练后的语音识别模型得到。
18、根据本发明的一些优选实施方式,所述音视频融合判断模型构建如下:
19、
20、
21、其中,avccls表示经音视频一致性分类器处理,表示音视频一致性分类器对输入的视频和音视对的分类结果,av表示输入的音视流,v表示输入的视频流,fuse()表示融合处理,output表示判断结果。
22、根据本发明的一些优选实施方式,所述音视一致性感知训练使用的损失函数为:
23、lall=(1-ρ)·lcls+ρ·α·lavsd+ρ·(1-α)·lvsd
24、其中,lall表示联合的损失函数,lcls为所述音视频一致性分类器的交叉熵损失函数,lavsd为第一音视频显著性检测模型的kullback-leibler散度函数,lvsd为第一音视频显著性检测模型中不使用音频分支仅针对视频进行显著性检测的kullback-leibler(kl)散度函数,ρ为平衡因子,可依据经验取值。
25、根据本发明的一些优选实施方式,所述第二音视显著性检测模型的训练过程包括:
26、s41获得所述标注后的音视频数据集;
27、s42根据所述音视一致性感知训练,使用标注后的音视频数据集训练音视频一致性分类器和音视显著性检测的sota模型;
28、s43在s42的训练过程中,若音视频一致性分类器的输出结果为1,则在第二音视显著性检测模型中同时使用视频和音频,其整体损失函数设置为:
29、lall=(1-ρ)·lcls+ρ·lavsd
30、若音视频一致性分类器的输出结果为0,则在第二音视显著性检测模型中不使用音频,其整体损失函数设置为:
31、lall=(1-ρ)·lcls+ρ·lvsd。
32、本发明在现有音视显著性数据集基础上新标注了音视一致性程度,根据给定音频与视频之间的关联程度进行音视一致性程度二值(0/1)标注,提高了关联程度强的音视对的检测性能。
33、本发明还设计了针对音视一致性感知的训练和测试策略,可通过音视一致性程度标签选择性融合音视流和视频流,提高音视语义特征的表征能力。
34、本发明还设计了可实现音视流和视频流自适应选择性融合的音视一致性分类器,其可通过自动预测当前输入音视对片段的音视一致性程度,自动控制音视流和视频流融合过程,实现端到端训练和测试。
35、以上过程中,音视一致性程度的新标注和针对音视一致性感知的训练和测试策略可应用于现有的音视显著性检测模型中,将现有的音视一致性欠感知的检测方法提升为具有音视一致性感知的方法。
36、进一步的,相对于现有技术,本发明具备以下有益效果:
37、(1)现有的音视显著性检测方法在融合不同模态的音频和视频特征信息时,没有考虑音视频不一致带来的模态欠感知的问题,将音视频特征直接进行了融合;而本发明中引入了音视一致性程度标签,可根据该标签选择性融合音视流和视频流,提高了音视语义特征的表征能力;
38、(2)本发明对音视一致性程度的标注方式和针对音视一致性感知的训练/测试策略具有通用性,可适用于任何现有的音视显著性检测sota模型,将现有的音视一致性欠感知方法提升为具有音视一致性感知的方法,显著提升了现有模型的检测性能。