基于部分域适应和知识蒸馏的旋转设备故障诊断方法
本发明涉及故障诊断,特别涉及一种基于部分域适应和知识蒸馏的旋转设备故障诊断方法。
背景技术:
1、随着现代工业中的机械设备越来越复杂,机械设备的稳定性也越来越重要,需要一种高效的监测技术来确认机械设备的健康状况信息。随着传感器技术不断地发展,可采集到的状态监测数据也越来越多,基于数据驱动的状态监测技术表现出了巨大的潜力。
2、深度学习可以充分利用多源状态监测数据对机械设备的健康状况进行自适应评估,是一种高效的数据驱动状态监测方法,由于训练数据和测试数据服从相同分布的前提假设。因此可以使用标记的训练数据对深度学习模型进行训练,然后使用未标记的测试数据对其性能进行评估。然而,在大多数实际场景中,训练数据和测试数据的分布是不一致的,这导致了训练数据和测试数据之间显著的域偏移。
3、基于迁移学习的诊断方法消除了域偏移对诊断性能的影响,其中域适应方法是一种利用矩匹配或对抗训练来对齐源域数据和目标域数据特征分布的特殊方法。然而,现有的域适应方法都是基于源域和目标域拥有相同的标签空间的假设,但是,在真实场景中,很难找到标签空间完全相同的源域和目标域数据,源域数据的标签信息往往远超于目标域数据,目标域数据的标签空间多为源域数据的子集。这种场景可以称为局部领域自适应问题。它将从以下两个方面给源域数据和目标域数据之间的特征对齐带来很大的挑战。
4、1、由于源域数据和目标域数据之间的共享标签空间未知,传统的领域自适应方法的边缘分布对齐方法在这种情况下会严重造成负迁移,在边缘分布对齐方法中需要引入类别权重估计过程,以评估每个源域类别对特征对齐过程的贡献。
5、2、由于标签信息在源域数据和目标域数据的从属关系比较混乱,传统的域自适应方法中的条件分布对齐方法在局部领域自适应方法中不可用,无法实现共享类别标签下,源域数据和目标域数据间类别特征对齐。
技术实现思路
1、本发明提供一种基于部分域适应和知识蒸馏的旋转设备故障诊断方法,可以提升现有部分迁移诊断方法用于旋转设备的故障识别正确率。
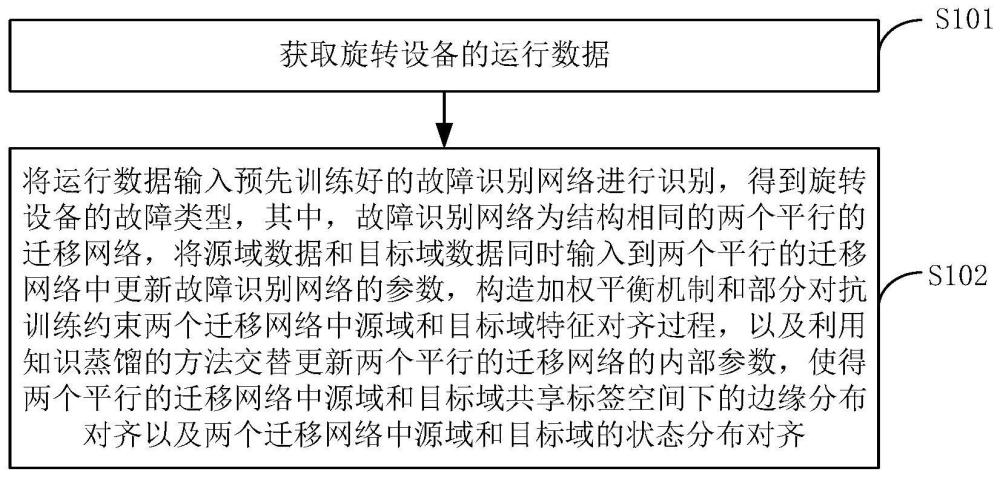
2、本发明实施例提供一种基于部分域适应和知识蒸馏的旋转设备故障诊断方法,包括以下步骤:获取旋转设备的运行数据;将所述运行数据输入预先训练好的故障识别网络进行识别,得到所述旋转设备的故障类型,所述故障识别网络为结构相同的两个平行的迁移网络,将源域数据和目标域数据同时输入到两个平行的迁移网络中更新所述故障识别网络的参数,构造加权平衡机制和部分对抗训练约束两个平行的迁移网络中源域和目标域特征对齐过程,以及利用知识蒸馏的方法交替更新两个平行的迁移网络的内部参数,使得两个平行的迁移网络中源域和目标域共享标签空间下的边缘分布对齐以及两个平行的迁移网络中源域和目标域的状态分布对齐。
3、可选地,在本发明的一个实施例中,收集任一工况包含故障类别数大于第一预设数量的数据作为所述源域数据,所述源域数据均为有标签数据,所述有标签的源域数据集表示为其中表示源域第i个样本,表示第i个样本的故障标签,ns表示源域样本数,源域数据集的标签空间为ys,对应的边缘状态分布为ps。
4、可选地,在本发明的一个实施例中,收集任一工况以外其他工况包含故障类别数小于第二预设数量的数据作为所述目标域数据,所述目标域数据均为无标签数据,所述目标域数据是源域数据的子集,所述无标签的目标域数据集表示为其中,表示目标域第i个样本,nt表示目标域样本数,目标域数据集的标签空间为yt,对应的边缘状态分布为pt,目标域标签信息为源域标签信息的子集
5、可选地,在本发明的一个实施例中,所述故障识别网络中每个迁移网络结构分别为特征提取器、域判别器和分类器;其中,特征提取器利用vit网络构造而成,域判别器和分类器均为三层全连接神经网络。
6、可选地,在本发明的一个实施例中,所述特征提取器包括:输入处理模块、transformer编码模块以及降维模块,在所述输入处理模块中,首先,将采集到的一维振动信号截断为n个等间隔的token,得到vit网络的输入数据;然后,将截取的n段振动信号带入全连接神经网络进行处理后,与可训练的参数类别token进行拼接,得到组合特征;最后,将可训练的参数位置嵌入编码和组合特征进行相加后得到transformer编码层的输入特征;
7、transformer编码模块利用多头自注意力机制挖掘监测数据中的全局特征信息,经transformer编码模块处理后的输出特征与输入特征拥有相同的维度;
8、在降维模块中,从transformer编码模块中提取的特征矩阵第一行的元素为一个token,通过全连接网络进行特征降维处理,得到vit网络的输出特征,vit网络的输出特征进一步用作分类器和鉴别器的输入。
9、可选地,在本发明的一个实施例中,两个平行的迁移网络中源域和目标域共享标签空间下的边缘分布对齐,包括:利用加权平衡机制和部分对抗训练方法约束源域和目标域在共享标签空间下的特征分布,使得两个平行的迁移网络中源域和目标域共享类别边缘分布对齐;在加权平衡机制中,训练好的分类器对目标域数据的输出概率属于共享标签空间,分类器给出的目标域数据输出概率分布用来评估共享标签空间和离群标签空间,使得两个迁移网络的分类器输出概率建立加权平衡机制
10、可选地,在本发明的一个实施例中,边缘分布对齐过程包括以下步骤:
11、加权平衡机制的第一步为:利用两个平行的迁移网络对所有目标域数据的标签预测,对和求平均值制定每个类别的初始权重,公式如下:
12、
13、其中,为分类器softmax层给出的目标域数据标签概率分布,k为源域数据标签类别数,γ=[γ1,…,γk,…,γk];表示第k个类别的初始权重;
14、加权平衡机制的第二步为:对类别权重系数进行归一化处理,以扩大共享标签空间与离群标签空间的权值差:
15、
16、其中,maxγ=max(γ)=max([γ1,…,γk,…,γk])为类别权重系数的最大值,γk为第k类的类别权重系数,γn为正则化处理后的类别权重系数;
17、在部分对抗训练中,对分类器和域判别器采用归一化权重约束参数更新过程,以降低离群标记空间下源域数据对对抗训练的过程的贡献,第一迁移网络的优化目标公式为:
18、
19、其中,θ1e,θ1d,θ1c表示特征提取器e、域判别器d和分类器c的网络参数;di表示第i个样本的领域标签;ly和ld表示分类器和域判别器交叉熵损失函数;λ表示度量两个损失函数的权重参数;部分迁移网络在特征提取器与域判别器之间引入梯度反转层,域判别器中域分类损失对应的梯度反向传播到特征提取器的参数之前自动取反,通过端对端的方式实现网络参数对抗训练;
20、第二迁移网络的优化目标公式为:
21、
22、其中,θ2e,θ2d,θ2c表示特征提取器e、域判别器d和分类器c的网络参数。
23、可选地,在本发明的一个实施例中,两个平行的迁移网络中源域和目标域的状态分布对齐包括:
24、两个迁移网络在每次迭代依次充当教师网络和学生网络,在每次迭代第一迁移网络的优化目标公式如下:
25、
26、其中,kldiv为kullback-leibler散度,和是两个迁移网络对目标域数据的输出概率,t是蒸馏温度的超参数,grd_fix表示梯度固定的操作,在第一迁移网络的训练过程中,固定第二迁移网络的梯度,并以第二迁移网络的预测结果作为基准;
27、第二迁移网络在每次迭代的优化目标公式如下:
28、
29、在第二迁移网络参数更新过程中,第一迁移网络的梯度是固定的,并且以第一迁移网络的预测结果作为基准。
30、本发明实施例的基于部分域适应和知识蒸馏的旋转设备故障诊断方法的有益效果为:
31、(1)利用平行vit网络结构提取监测数据全局特征信息。vit网络利用自注意力机制提取全局特征信息,该网络具有很好的分类效果。本发明方法利用两个vit网络构造并行网络结构,通过迭代更新两个并行网络的内部参数实现源域与目标域共享标签空间下的特征对齐任务。
32、(2)利用部分域适应的方法,实现源域和目标域共享类别数据间的边缘分布对齐。通过加权平衡机制和部分对抗训练约束源域和目标域特征对齐过程,弱化第一迁移网络和第二迁移网络中离群标签空间下源域数据对特征对齐过程的影响,促进源域和目标域共享标签空间下的边缘分布对齐。
33、(3)利用知识蒸馏的方式训练两个结构相同的迁移网络,实现源域和目标域共享类别数据间的条件分布对齐。在每次迭代过程中两个迁移网络依次充当教师网络和学生网络,来提高两个迁移网络的目标域数据的标签一致性,实现两个迁移网络源域和目标域在共享标签空间下的类别特征对齐。
34、本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!