一种数据驱动的完全端到端的相似问句生成方法与流程
本发明涉及自然语言处理,尤其涉及一种数据驱动的完全端到端的相似问句生成方法。
背景技术:
1、问答系统是一种信息检索的高级形式,它能用准确简洁的语言回答用户用自然语言提出的问题,目前,自动问答技术的实现主要有阅读式、检索式和生成式三大类,其中,阅读式是指机器阅读:通过给定文章和针对文章提出的具体问答对训练机器的阅读理解能力,并对针对文章的新问题作出回答,阅读式的问题是知识边界狭窄,训练语料构筑困难,与之相反的是生成式:生成式理论上可实现不受知识局限的通用机器人,但目前生成式最大的问题是答非所问、胡言乱语,无法表现出人类在解决问题时的逻辑自洽、思维发散和自然表达等能力, 而检索式则是一种取长补短的技术,检常见的检索式问答系统有基于知识图谱的(kbqa),有基于faq的(frequently asked questions),本发明聚焦于自动化扩充faq知识库。
2、faq知识库是基于faq的问答系统的核心组件,它限定了问答系统的能力边界,在faq知识库中,一条知识通常由以下内容构成:一条标准问,数条与标准问语义相同但表达不同的扩展问,答案,构建一个优质的知识库通常需要耗费大量的人力成本和时间成本,这其中,扩展问的构建是相当困难的问题,需要消耗知识库维护人员大量的时间,现有的自动化生成相似句的方法一般包括如下几种:数据增强法,通过删除、增加、替换、交换原问句中的词获得新的问句,这种方法极有可能改变原问句的语义和语句的通顺性,因此往往需要借助外部工具如需要语义相似度计算模型判断新问句和原问句语义是否相似,需要语言模型判断新问句是否流畅,回译法,通过将原始问句翻译成另外一种语言,再翻译回中文,这种方法需要维护两个甚至更多的翻译模型,而且经过两次翻译后原句的语义也极有可能与原句有偏差,为了解决现有技术模块复杂、维护成本高、生成问句语义偏移的现状,本发明提出了一种数据驱动的完全端到端的相似问句生成方法。
技术实现思路
1、本发明的目的是为了解决现有技术中存在的缺点,提出一种数据驱动的完全端到端的相似问句生成方法。
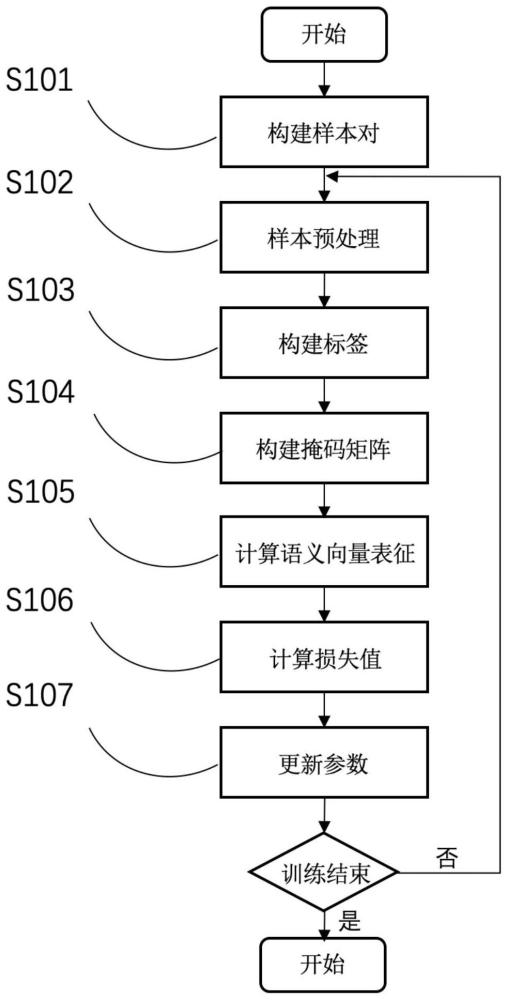
2、为了实现上述目的,本发明采用了如下技术方案:一种数据驱动的完全端到端的相似问句生成方法,所述的相似问句生成方法具体步骤为:
3、s1、训练阶段:
4、s1.1、构建样本对,每一个样本包含两个句子,句子a以及它的相似句b;
5、s1.2、将句子a和句子b进行分词,处理成如下的符号列表x(这里假设句子a和b分别包含3个词):
6、x={[cls],a1,a2,a3,[sep],b1,b2,b3,[sep]};
7、s1.3、构建训练标签;
8、s1.4、构建掩码矩阵m:掩码矩阵根据步骤s1.2中的输入x计算,x中从[cls]符号到第一个[sep]属于第一个句子,一共有5个符号,从b1到第二个[sep]有四个符号属于第二个句子,因此m形如下面的二维矩阵:
9、[1,1,1,1,1,0,0,0,0]
10、[1,1,1,1,1,0,0,0,0]
11、[1,1,1,1,1,0,0,0,0]
12、[1,1,1,1,1,0,0,0,0]
13、[1,1,1,1,1,0,0,0,0]
14、[1,1,1,1,1,1,0,0,0]
15、[1,1,1,1,1,1,1,0,0]
16、[1,1,1,1,1,1,1,1,0]
17、[1,1,1,1,1,1,1,1,1];
18、s1.5、将输入序列x和掩码矩阵m输入bert模型中进行语义计算,最后取bert最后一层神经网络的输出,得到一个维度为[9,768]的语义矩阵p,语义矩阵p包含9个768维的向量,每个向量分别是输入x中每个符号的语义向量。这些语义向量经过bert中神经网络的计算,包含了输入序列中丰富的上下文信;
19、s1.6、计算损失值;
20、s1.7、根据步骤s1.6中计算得到的损失值,用反向传播算法更新整个模型的参数;
21、s2、预测阶段:
22、s2.1、假设需要生成句子a的相似句,将句子a处理成如下的符号列表x(这里假设句子a包含3个词):
23、x={[cls],a1,a2,a3,[sep]};
24、s2.2、将序列x输入训练好的模型中进行语义计算;
25、s2.3、取[sep]的语义向量进行束搜索(beam search)解码,束宽设置为k,解码序列的最大长度设置为m,解码序列达到最大长度m或者解码出停止符号[sep]时输出一条最终解码序列,最终解码出k条序列,即生成k个a的相似句。
26、通过采用上述技术方案:本发明在大量数据的训练后,该方法能够捕捉到相同语义的不同表达方式,该方法完全端到端,可一次生成原问句的多个相似问句,易维护、可迭代。
27、优选的,所述s1.3的具体步骤为:在预测阶段,模型需要根据第一个[sep]的语义向量预测出b1,在根据b1的语义向量预测b2,依次类推,则在训练阶段的标签为:
28、{b1,b2,b3,[sep]}。
29、采用上述技术方案:通过对训练进行标签的构建,能够针对每个训练进行标记,避免在后期计算过程中将数据弄混,造成数据不准确的情况。
30、优选的,所述步骤s1.6中具体步骤为:步骤s1.5中得到的语义矩阵p中,第5-8个语义向量分别是“[sep],b1,b2,b3”这四个符号的语义向量,假设e[sep]是符号[sep]的语义向量,预测阶段需要用它预测下一个可能的符号,在这里下一个符号即是b1,将e[sep]通过一个全连接层转换为一个d维的向量,然后经过softmax函数计算得到预测向量y,y的维度是d,每个元素是0-1之间的实数,d是系统词典的大小,y的第i个元素yi的含义是“根据[sep]的语义向量预测下一个生成的符号是词典中第i个词的概率”,假设b1是字典中第j个词,根据j和yj计算交叉熵损失值,同理,根据(eb1,b2)、(eb2,b3)、(eb3,[sep])用同样的方法计算损失值。
31、采用上述技术方案:通过softmax函数计算得到预测向量y,利用函数对向量y进行精确计算,避免了人工计算过程中出现的误差。
32、优选的,所述步骤s1.4中,mij表示m中第i行第j列的元素,如果为1,则表示在计算输入序列x中第i个符号的语义向量时,参考第j个符号的信息;如果为0,则表示计算第i个符号的语义向量时不参考第j个符号。
33、优选的,所述步骤s1.2中[cls]和[sep]是特殊符号,[cls]表示这里是输入开始的位置,第一个[sep]符号表示这里是第一个句子结束的位置,第二个[sep]符号表示这里是第二个句子结束的位置。
34、优选的,所述步骤s2.1中[cls]和[sep]是特殊符号,[cls]表示这里是输入开始的位置,[sep]符号表示这里是输入结束的位置。
35、与现有技术相比,本发明的优点和积极效果在于,
36、本发明通过对训练进行标签的构建,能够针对每个训练进行标记,避免在后期计算过程中将数据弄混,造成数据不准确的情况;
37、通过softmax函数计算得到预测向量y,利用函数对向量y进行精确计算,避免了人工计算过程中出现的误差;在大量数据的训练后,该方法能够捕捉到相同语义的不同表达方式,该方法完全端到端,可一次生成原问句的多个相似问句,易维护、可迭代。
- 还没有人留言评论。精彩留言会获得点赞!