基于强化学习的多智能体协同对抗决策方法及装置与流程
本公开涉及深度强化学习,特别涉及一种基于强化学习的多智能体协同对抗决策方法及装置。
背景技术:
1、即时策略游戏中,为完成敌我双方对抗任务,智能体需要基于所处的环境做出相应决策,根据该决策执行相应的动作。为了使智能体能够做出最优的决策,现有技术通常采用多目标深度强化学习算法实现。在多目标问题中,强化学习需要处理多个目标函数,例如,在游戏中需要同时考虑最大化得分和最小化游戏时间等,因此,在强化学习算法中,需要设计一个合适的奖励函数来评估智能体的行为,从而指导其行为。一般来说,可以采用线性加权法或帕累托优化法处理多目标强化学习中的奖励函数。
2、线性加权法是将多个目标函数的奖励值线性加权,得到一个加权和作为智能体的奖励值,比如,该奖励值可表示为r=ω1×r1+ω2×r2,其中,ω1和ω2分别是不同目标函数r1和r2的权重,可以根据具体问题进行调整。线性加权法的优点是简单易实现,其缺点在于不同目标函数之间权重的设置非常依赖特定应用场景,在实际动态优化目标问题中难以固定特定的权重,权重多变,并且可能会导致奖励函数的精度在某些情况下不准确,从而导致智能体做出的最终决策有所偏差。
3、帕累托优化法是通过寻找帕累托最优解来解决多目标强化学习问题。在帕累托最优解中,没有任何一个目标函数能够在所有解中达到最优。该方法中,我们需要确定一组不同的权重向量,然后对每个权重向量进行优化。通过重复这个过程,我们可以得到一组帕累托最优解。帕累托优化法的优点在于可以同时考虑多个目标函数并且可以得到一组最优解,其缺点在于找到一组有效的权重向量通常需要较大的计算量,并且帕累托最优解的数量可能会很大,在实际动态优化目标问题中寻找最优向量比较困难,网络训练效率低,从而导致智能体无法即时做出相应决策。
技术实现思路
1、本公开旨在至少解决现有技术中存在的问题之一,提供一种基于强化学习的多智能体协同对抗决策方法及装置。
2、本公开的一个方面,提供了一种基于强化学习的多智能体协同对抗决策方法,所述决策方法包括:
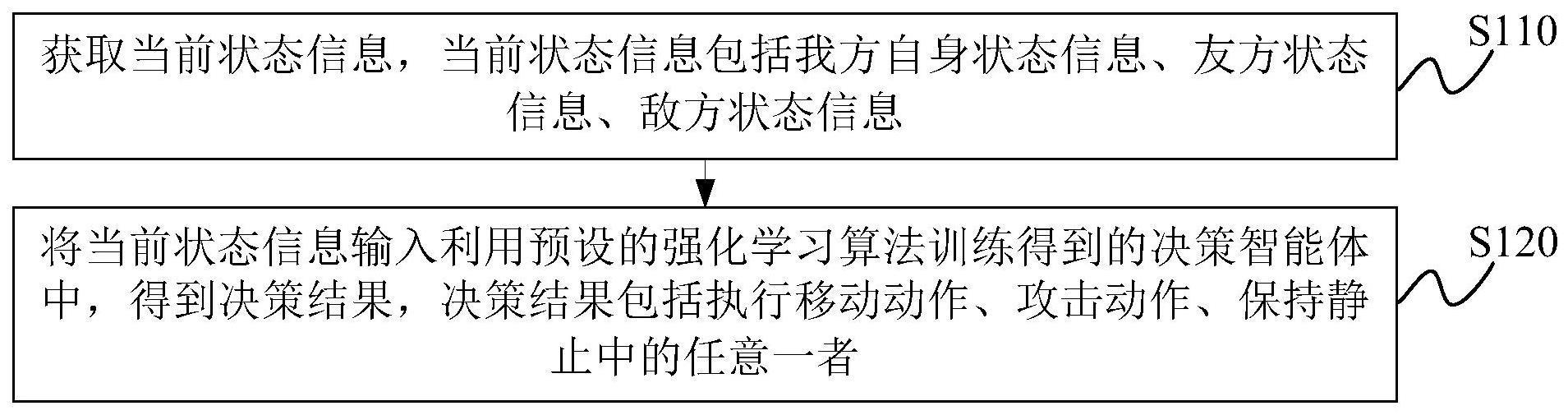
3、获取当前状态信息,所述当前状态信息包括我方自身状态信息、友方状态信息、敌方状态信息;
4、将所述当前状态信息输入利用预设的强化学习算法训练得到的决策智能体中,得到决策结果,所述决策结果包括执行移动动作、攻击动作、保持静止中的任意一者;
5、所述预设的强化学习算法包括以下步骤:
6、获取决策智能体的观测信息,所述观测信息包括所述决策智能体的自身状态信息、友方状态信息、敌方状态信息;
7、利用编码权重矩阵对所述观测信息和权重向量进行编码,得到权重与状态特征协同编码,并设计目标奖励函数;
8、基于所述权重向量所在的权重空间进行多状态价值重采样,结合所述权重与状态特征协同编码对应的整体轨迹q值,确定所述权重与状态特征协同编码对应的最优增广元组序列;
9、基于所述最优元组序列分别确定策略网络的损失函数和值网络的总渐进式包络损失函数,基于所述策略网络的损失函数和所述总渐进式包络损失函数,对所述策略网络和所述值网络进行参数更新;
10、基于所述目标奖励函数,利用参数更新后的所述策略网络和所述值网络对权重与状态特征协同编码进行决策解码,输出决策结果。
11、可选地,所述利用编码权重矩阵对所述观测信息和权重向量进行编码,得到权重与状态特征协同编码,包括:
12、根据下式(1)对所述观测信息进行编码,得到观测信息编码o,其中,oself∈ros表示所述决策智能体的自身状态信息,r表示奖励函数,os表示所述决策智能体的信息维度,为of的向量化表示,of∈rof×nf表示友方状态信息,of表示友方信息维度,nf表示友方作战单位数量,为oe的向量化表示,oe∈roe×ne表示敌方状态信息,oe表示敌方信息维度,ne表示敌方作战单位数量:
13、
14、根据下式(2)对观测信息编码o进行编码,得到状态信息编码s,其中,f1∈re1×no表示第一编码权重矩阵,o∈rno,no=os+of*nf+oe*ne,s∈re1,e1表示状态信息编码s对应的状态特征维度:
15、s=f1×o (2)
16、根据下式(3)对权重向量进行编码,得到权重向量编码fw,其中,fw∈re2,f2∈re2×nw表示第二编码权重矩阵,ω∈rnw表示权重向量,nw表示权重向量维度,e2表示权重向量编码fw对应的权重特征维度:
17、fw=f2×ω (3)
18、根据下式(4)获得权重与状态特征协同编码csw:
19、csw={s,fw} (4)。
20、可选地,所述目标奖励函数表示为下式(5):
21、fω(r(s,a))=ωtr(s,a)=ω1r1(s,a)+ω2r2(s,a) (5)
22、其中,fω(r(s,a))表示所述目标奖励函数,s表示所述决策智能体对应的状态张量,a表示所述决策智能体对应的动作张量,r1(s,a)表示击杀敌方作战单元奖励,ω1表示r1(s,a)对应的权重,r2(s,a)表示所述决策智能体的剩余血量奖励,ω2表示r2(s,a)对应的权重。
23、可选地,所述基于所述权重向量所在的权重空间进行多状态价值重采样,结合所述权重与状态特征协同编码对应的整体轨迹q值,确定所述权重与状态特征协同编码对应的最优增广元组序列,包括:
24、根据下式(6)计算所述整体轨迹q值,其中,qπ(s,a)表示所述整体轨迹q值,π为动作策略分布,γ为衰减系数,t表示时刻,rt表示t时刻的奖励函数,s0表示所述决策智能体与环境互动时在t=0时刻的初始状态,a0表示所述决策智能体与环境互动时在t=0时刻的动作,表示数学期望:
25、
26、对权重向量ω所在的权重空间ω进行n次均匀随机采样,得到n个权重向量ω,将n个权重向量ω分别与状态转移序列组合,得到m×n×k个状态元组(st,at,rt,st+1,ω)作为增广元组序列,其中,m表示奖励向量的维数,k表示状态转移序列的个数,st表示所述决策智能体与环境互动时在t时刻的初始状态,at表示所述决策智能体与环境互动时在t时刻的动作,st+1表示所述决策智能体与环境互动时在t时刻交互后返回的状态;
27、对于任意一个给定的转移元组序列(st,at,rt,st+1),在采样得到的n个权重向量ω中计算最优权重向量ω*=argmaxωωtq(st+1,at,ω),得到对应的最优增广元组序列(st,at,rt,st+1,ω*),其中,q(st+1,at,ω)表示(st+1,at,ω)的q值。
28、可选地,所述策略网络的损失函数表示为下式(7):
29、
30、其中,lπ(θ)表示所述策略网络的损失函数,πθ和分别为新旧策略分布,θ和θold分别为πθ和的参数,表示对样本取均值,为增广优势函数且表示为下式(8),
31、
32、其中,vπ为根据当前策略π学习的值网络,θv为vπ的参数,qπ(st,at,ω)表示当前策略π对应的状态轨迹q值。
33、可选地,所述值网络的总渐进式包络损失函数表示为下式(9):
34、
35、其中,l(θ)表示所述值网络的总渐进式包络损失函数,表示权衡权重,k为迭代次数,τ为延缓系数,为值网络的训练初期损失函数且表示为下式(10),为值网络的训练后期损失函数且表示为下式(11),
36、
37、
38、其中,y1和y2均为中间变量且分别表示为下式(12)和下式(13)
39、
40、
41、其中,γ表示折扣因子。
42、可选地,所述基于所述目标奖励函数,利用参数更新后的所述策略网络和所述值网络对权重与状态特征协同编码进行决策解码,输出决策结果,包括:
43、根据下式(14)计算决策动作概率:
44、
45、其中,p表示所述决策动作概率,softmax表示归一化指数函数,na表示决策动作的维度,i表示决策动作的维度序号,output=fc(csw)表示且output∈rna,outputi表示output的第i个元素,fc表示全连接网络。
46、本公开的另一个方面,提供了一种基于强化学习的多智能体协同对抗决策装置,所述决策装置包括:
47、获取模块,用于获取当前状态信息,所述当前状态信息包括我方自身状态信息、友方状态信息、敌方状态信息;
48、决策模块,用于将所述当前状态信息输入利用预设的强化学习算法训练得到的决策智能体中,得到决策结果,所述决策结果包括执行移动动作、攻击动作、保持静止中的任意一者;
49、训练模块,用于根据包括以下步骤的所述预设的强化学习算法对所述决策智能体进行训练:
50、获取决策智能体的观测信息,所述观测信息包括所述决策智能体的自身状态信息、友方状态信息、敌方状态信息;
51、利用编码权重矩阵对所述观测信息和权重向量进行编码,得到权重与状态特征协同编码,并设计目标奖励函数;
52、基于所述权重向量所在的权重空间进行多状态价值重采样,结合所述权重与状态特征协同编码对应的整体轨迹q值,确定所述权重与状态特征协同编码对应的最优增广元组序列;
53、基于所述最优元组序列分别确定策略网络的损失函数和值网络的总渐进式包络损失函数,基于所述策略网络的损失函数和所述总渐进式包络损失函数,对所述策略网络和所述值网络进行参数更新;
54、基于所述目标奖励函数,利用参数更新后的所述策略网络和所述值网络对权重与状态特征协同编码进行决策解码,输出决策结果。
55、本公开的另一个方面,提供了一种电子设备,包括:
56、至少一个处理器;以及,
57、与至少一个处理器通信连接的存储器;其中,
58、存储器存储有可被至少一个处理器执行的指令,指令被至少一个处理器执行,以使至少一个处理器能够执行前文记载的基于强化学习的多智能体协同对抗决策方法。
59、本公开的另一个方面,提供了一种计算机可读存储介质,存储有计算机程序,计算机程序被处理器执行时实现前文记载的基于强化学习的多智能体协同对抗决策方法。
60、本公开相对于现有技术而言,通过获取当前状态信息,将当前状态信息输入利用预设的强化学习算法训练得到的决策智能体中,得到决策结果,可以使智能体在多智能体协同对抗过程中基于当前状态即时做出相应决策,并有效提高决策结果的准确性。
- 还没有人留言评论。精彩留言会获得点赞!