一种基于警烟联动数字化情报研判方法与流程
本发明主要涉及数字化情报研判方法,其具体为一种基于警烟联动数字化情报研判方法。
背景技术:
1、互联网时代,网上购物逐步取代线下交易而成为主流消费模式,涉烟人员也将目光聚焦到广阔的互联网。近年来,“互联网以及物流寄递”的交易模式,增加了对涉烟人员、涉烟人员通联关系、涉烟人员旅居关系、相关人员失规、相关人员活动区域、涉烟车辆、涉烟车辆运输、重点卡口等任务情况进行研判的困难,让传统的烟草专卖管理工作障碍重重。
技术实现思路
1、本发明的目的是为了解决现有技术中存在的无法对涉烟人员、涉烟人员通联关系、涉烟人员旅居关系、涉烟车辆、涉烟车辆运输、重点卡口等任务情况进行研判,而提出的一种基于警烟联动数字化情报研判方法。
2、为了实现上述目的,本发明采用了如下技术方案:一种基于警烟联动数字化情报研判方法,包括:预训练和识别过程,
3、所述预训练是将数据库中的图像和文字进行描述,并进行编码和解码,获得相应的预训练特征,识别过程通过对待研判的图像和/或文字,进行编码和解码,获取相应特征,与预训练数据库中的特征进行识别,判断涉烟相关情报信息,
4、其中预训练包括以下步骤:
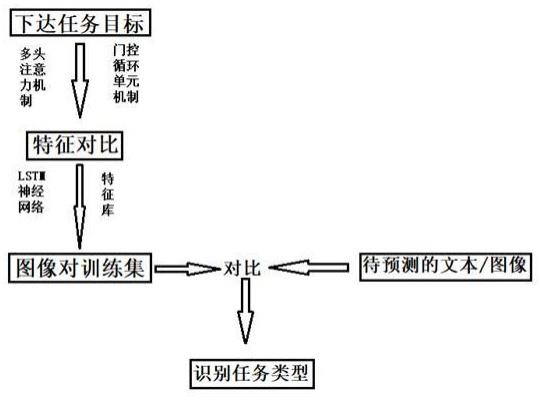
5、步骤s100,给定任务,采用多头注意力机制和门控循环单元机制对文本进行分词处理和关注;
6、步骤s200,给定任务,采用lstm神经网络对图像进行识别,获取特征与特征库的特征进行对比;
7、步骤s300,将预训练后的文本和图像进行关联,形成包含特征的文本-图像对训练集。
8、识别过程包括以下步骤:
9、步骤s400,对输入的待预测的文本和/或图像进行识别,获取相应特征;
10、步骤s500,对待预测获得的特征与预训练得到的包含特征的文本-图像对进行比较,若在阈值范围内,则被识别并得到任务类型。
11、进一步地,步骤s100中,基于深度神经网络的注意力机制会协助网络模型从复杂的输入信息中筛选出与现阶段任务关联度最高的信息。而门控循环单元可以使神经网络不仅能够记忆过去的信息,同时还能选择性的删除不重要的信息。同时为了增加预训练的准确性,采用多头注意力机制对同一文本信息进行比较学习,降低文本不匹配的情形。
12、所述步骤s100中采用注意力机制对分词的文本进行关注的具体过程包括:
13、步骤s101,采用embedding模型对进行处理得到,其中代表文本某个词或短语所对应的向量,为注意力分布, u为文本中单次和短语的数量;
14、步骤s102,获取多图注意力机制中的查询向量、 键向量和值向量
15、
16、
17、
18、其中,、、为u×t的矩阵,,,,t为多头注意力机制所在申请网络通道数;
19、步骤s103,每一个查询向量与所有键向量进行相乘得到对应分数;
20、步骤s104,利用softmax函数获取每一查询向量的注意力概率分布,即权重系数
21、
22、步骤s105,对每一查询向量对应的值向量进行加权求和获得对比学习后的注意力输出
23、
24、步骤s105,对所有查询向量得到的注意力输出进行拼接得到对比学习后的注意力 b
25、。
26、进一步地,所述步骤s100中,对于不同的任务,关注的文本也不相同。对于涉烟人员研判任务,关注的文本向量包括{人员基本信息,出行数据,通话数据,快递数据};对于涉烟人员通联关系研判任务,关注的文本向量包括{成员的姓名,性别,年龄,与社会网络中成员之间互动频率,关系密度};涉烟人员旅居关系研判任务,应关注出行记录,关注的文本向量包括{班次,车厢,邻座位,出发地,目的,入住,退房};对于相关人员失规研判任务,关注的文本向量包括{失规行为的类型,频率,时间,地点,通话,相关的人员,环境};对于涉烟人员特定活动研判任务,关注的文本向量包括{人员姓名,身份证号,所在地,旅行信息,接触人员情况,旅行历史,通讯记录,社交网络行为};对于相关人员活动区域研判任务,关注的文本向量包括{人员的历史活动范围,时间节点};对于涉烟车辆研判任务,关注的文本向量包括{车辆基本信息,卡口数据,高速数据,时序数据};对于涉烟车辆运输研判任务,关注的文本向量包括{高速收费站数据,高速卡口数据,货车过板数据,涉烟车辆行驶的行为模式,满载重量,卸货前后重量变化情况}。
27、进一步地,所述步骤s200中,采用lstm神经网络(长短期记忆网络)对图像进行编码获取特征,采用lstm神经网络进行图像编码,首先进行降维,然后再进行建模,
28、基于lstm神经网络,步骤s200中对图像进行训练的具体过程包括:
29、步骤s201,对图像i的描述集合 x进行多层卷积生成连续的编码向量 z
30、
31、其中,是一个 d为的向量, z是一个 m× m× d的向量;
32、步骤s202,采用embedding模型对每个进行临近搜索,获得对应的编码表向量 z q;其中embedding模型包含编码表,通过临近搜索,将 z映射为这 k个向量之一,即
33、
34、步骤s203,采用decoder模型对 z q进行重构,得到图像 i的编码图像
35、
36、步骤s204,设置目标函数对编码图像进行训练
37、
38、其中,、为超参数,且;
39、进一步地,所述步骤s200中,训练后的图像获取特征,并与数据库的特征进行比较判断特征类型。
40、进一步地,所述步骤s400中,对于待预测的文本部分,采用和步骤s100相同的方法进行编码识别获得关注的特征;对于待预测的图像部分,采用和步骤s200相同的方法进行编码识别获得特征,但不进行特征库的对比。
41、进一步地,所述步骤s500中将获得的待预测的文本部分的特征与训练集中的文本特征分别输入lstm神经网络中的两个孪生的支路进行训练。具体过程为:
42、步骤s501,将待预测的特征与训练集的特征分别输入lstm神经网络中的两个孪生的支路进行训练;
43、步骤s502,获取训练后的损失,基于损失确定待预测特征编码的第一隐变量特征以及训练集特征编码的第二隐变量特征;
44、步骤s503,根据待预测特征编码和对应的第一隐变量特征,以及训练集特征编码和对应的第二隐变量特征对神经网络进行迭代训练,直到损失最小时,得到相似度检测模型。
45、进一步地,步骤s502中的损失函数为
46、
47、其中,m为样本数,为训练集特征向量,为待预测特征向量。
48、进一步地,步骤s502中第一隐变量特征为损失函数对求导,第二隐变量特征为损失函数对求导。
49、进一步地,所述步骤s503中,根据待预测特征编码叠加对应的第一隐变量特征,得到更新后的第一特征编码;根据训练集特征编码叠加对应的第二隐变量特征,得到更新后的第二特征编码;采用更新后的第一特征编码和更新后的第二特征编码对神经网络进行迭代训练。
50、本发明与现有技术相比,具有以下优势:(1)在本发明预训练是将数据库中的图像和文字进行描述,并进行编码和解码,获得相应的预训练特征,从而达到更好的信息采集效果,获取相应特征;(2)在本发明识别过程通过对待研判的图像和/或文字,进行编码和解码,获取相应特征,与预训练数据库中的特征进行识别,判断涉烟相关情报信息,从而得到更为准确的信息研判。
51、下面结合说明书附图对本发明做进一步描述。
- 还没有人留言评论。精彩留言会获得点赞!