基于智慧教室场景下学生课堂姿态行为的检测方法
本发明属于图像处理方法,具体涉及基于智慧教室场景下学生课堂姿态行为的检测方法。
背景技术:
1、智慧教育,带来了教育形式和学习方式的重大变革。在智慧教室场景下,学生课堂姿态智能检测是构建智能化课堂环境的重要环节。尽管当今目标检测方法层出不穷,但现有的目标检测方法并不能精确地检测出教室中学生的位置,对教室中密集的学生姿态的识别更是力不从心。swintransformer的横空出世,改善了密集场所下目标的检测精度。但在智慧教室场景下,学生呈现在图像里通常是密集的小目标,swintransformer网络对这类的小目标的特征提取并不充分,智慧教室场景下学生课堂姿态的误检率和漏检率仍然很高。
技术实现思路
1、本发明的目的是提供基于智慧教室场景下学生课堂姿态行为的检测方法,能够在复杂背景和教室课堂学生密集环境下,实现对学生进行精准定位和对学生抬头和低头行为进行精确分类。
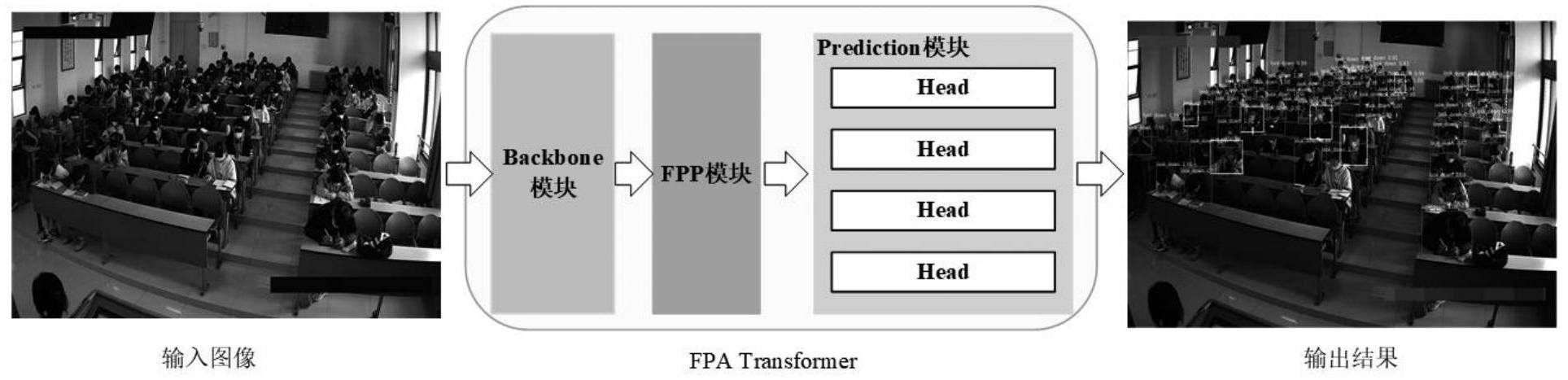
2、本发明所采用的技术方案是,基于智慧教室场景下学生课堂姿态行为的检测方法,该方法使用具有特征感知注意力(feature perception attention,fpa)的transformer(fpatransformer)来对课堂上学生的抬头和低头行为进行检测分类。具体为:步骤1,制作studentclassroombehaviordataset(scb_dataset)数据集;
3、步骤2,构建fpa transformer中的backbone模块,backbone模块通过使用四个特征感知注意力块(feature perception block,fpb)来提取学生听课的抬头和低头行为特征,得到相应的特征图;
4、步骤3,搭建fpa transformer中的特征感知金字塔(featureperceptionpyramid,fpp)模块,对步骤2提取得到的特征图进行特征融合;
5、步骤4,设计fpa transformer中的prediction head模块,在步骤3获取到的特征图上对学生的位置进行定位,并对学生抬头低头行为进行分类;
6、步骤5,使用步骤1的scb_dateset训练集训练由backbone模块、fpp模块和predictionhead模块组成的fpa transformer,将训练生成的权重文件进行保存;
7、步骤6,加载步骤5训练好的权重文件,将教室课堂图像输入到训练好的fpatransformer中,得到最终网络的检测结果。
8、本发明的特征还在于,
9、步骤1具体为:制作scb_dataset训练数据集,具体为:制作6000张640×640×3大小的教室场景图像作为训练样本,对每张图像中学生听课的抬头和低头行为进行标记,将标记后的图像制作为voc格式的scb_dataset训练数据集。
10、步骤2具体按照以下步骤实施:
11、步骤2.1,构建backbone模块,backbone模块包括有一个patch partition层、一个linear embedding层、三个patch merging层、四个fpb块。backbone模块中的patchpartition层对输入图像进行分块,再通过backbone模块中的linear embedding层对每个像素的通道做线性变换,之后使用4个相同的fpb块对学生课堂行为特征进行提取,除第一个fpb块外,剩下的3个fpb块都需要通过patch merging层进行下采样;最后,backbone模块输出是四个不同尺度学生行为信息的特征图。
12、步骤2.2,在backbone模块的patchpartition层,对步骤1的图像x进行分块,每4个相邻的像素为一个patch(xi),然后在通道方向将分块后的输入图像展平,得到图像l1;
13、步骤2.3,将步骤2.2中得到的图像l1,通过fpa transformer的linearembedding层对每个像素的通道做线性变换,得到特征图l2;
14、步骤2.4,构造fpb,每个fpb块结构都包含两个连续的swin transformer block,但将swin transformer block中的窗口多头自注意力(w-msa)用局部特征感知多头注意力(local feature perception attention,lfpa)替换。将步骤2.3中得到的特征图l2输入到第一个fpb块中来对学生听课抬头和低头行为特征进行提取,得到大小为160×160×128的特征图feat1;
15、步骤2.5,将步骤2.4中得到的特征图feat1输入到第一个patchmerging层进行下采样,特征图的宽和高减半、深度翻倍后,再输入第二个fpb块中,再对学生听课抬头和低头的特征进行提取,得到大小为80×80×256的特征图feat2;
16、步骤2.6,将步骤2.5中得到的特征图feat2输入到第二个patchmerging层进行下采样,特征图的宽和高减半、深度翻倍后,再输入第三个fpb块中,这里需堆叠3次来提取学生听课抬头和低头行为的特征,得到大小为40×40×512的特征图feat3;
17、步骤2.7,将步骤2.6中得到的特征图feat3输入到第三个patchmerging层进行下采样,特征图的宽和高减半、深度翻倍后,再输入第四个fpb块中,提取学生听课抬头和低头行为的特征,得到大小为20×20×1024的特征图feat4;
18、步骤2.4中,计算局部特征感知多头注意力(lfpa)的方法为:首先,将特征图l2输入感知网络(perceptionnetwork)得到特征图通过得到向量和而向量q由特征图l2获得。最后,将q、和输入到多头自注意力(multi-head attention)中进行计算,最后得到输出特征图z。局部特征感知多头注意力(lfpa)流程如图4所示。
19、其中,感知网络结构如图5所示,它由两个卷积层构成,每个卷积层有h×w×c个卷积核,卷积核大小为3×3,其中h,w,c分别为特征图的高、宽和通道数。第一个卷积层用来获得特征图l2中每个元素的坐标位置偏移量,然后,根据位置偏移量由双线性插值计算出该元素的新像素值,最后,通过第二个卷积层得到特征图
20、步骤3具体按照以下步骤实施:
21、步骤3.1,搭建fpp模块,对步骤2提取的特征图进行特征融合,将步骤2.4-2.7中输出的特征图feat1,feat2,feat3,feat4输送到fpp模块中,fpp模块结构如图2第二列所示,fpp模块包括有三个conv2d卷积层、三个upsampling2d上采样层、六个concat、六个yolov5中的csplayer(cross stage partial layer),以及三个特征感知下采样;fpp模块最终输出四个分辨率不同的学生行为特征图;
22、步骤3.2,对步骤2.7中生成的学生听课状态特征图feat4进行1次1×1卷积conv2d调整通道后获得特征图p4,特征图p4进行上采样upsampling2d后,与步骤2.6中得到的特征图feat3进行concat融合,然后使用csplayer进行特征提取获得大小为40×40×512的特征图p4_upsample;
23、步骤3.3,将步骤3.2中得到的特征图p4_upsample,通过1次1×1卷积conv2d调整通道,获得特征图p3。特征图p3再进行上采样upsampling2d后,与步骤2.5中得到的特征图feat2进行concat融合,然后使用csplayer进行特征提取,得到大小为80×80×256的特征图p3_upsample;
24、步骤3.4,将步骤3.3中得到的特征图p3_upsample,通过1次1×1卷积conv2d调整通道,获得特征图p2。特征图p2再进行上采样upsampling2d后,与步骤2.4中得到的特征图feat1进行concat融合,然后使用csplayer进行特征提取,得到大小为160×160×128的特征图p1_out;
25、步骤3.5,将步骤3.4中得到的特征图p1_out进行特征感知下采样(featureperception down-sampling),特征感知下采样通过感知网络来实现,网络中的卷积层采样步长为2。感知网络的输出结果再与步骤3.4中得到的特征图p2进行concat融合,然后使用csplayer进行特征提取,得到大小为80×80×256的特征图p2_out;
26、步骤3.6,将步骤3.5中得到的特征图p2_out进行特征感知下采样,之后与步骤3.3中得到的特征图p3进行concat融合,然后使用csplayer进行特征提取,得到大小为40×40×512的特征图p3_out;
27、步骤3.7,将步骤3.6中得到的特征图p3_out进行特征感知下采样,之后与步骤3.2中得到的特征图p4进行concat融合,然后使用csplayer进行特征提取,得到大小为20×20×1024的特征图p4_out。
28、步骤4具体按照以下步骤实施:
29、步骤4.1,设计fpa transformer中的prediction head模块,prediction head模块包括有四个检测头head,将步骤3.4-3.7中输出的特征图p1_out,p2_out,p3_out,p4_out分别输送到prediction head模块的四个检测头head中;每个head检测头包括回归分支、阈值分支和分类分支,每个分支使用四个卷积层进行特征增强,最后每个分支使用不同的卷积层输出卷积后的结果。回归分支对该分辨率下学生位置进行定位,阈值分支对该分辨率下的获得的预测框计算得分score,分类分支计算该分辨率下的学生行为类别即抬头和低头的概率;最后由非极大抑制(nms)得到学生课堂抬头和低头行为的最终检测结果。
30、步骤4.2,将步骤3.4-3.7中获得的特征图p1_out,p2_out,p3_out,p4_out分别输入predictionhead的四个检测头head中,由其回归分支的四个卷积层进行特征增强,再使用一个卷积层来计算出每个学生位置的预测框,输出预测框内的每个像素点到groundtruth的左、上、右、下四个边界的距离,即l,t,r,b;
31、步骤4.3,将步骤4.2中获得的l,t,r,b值输入到检测头head的阈值分支,通过公式(1)来计算预测框中每个像素点的坐标得分score。score值可以用来判断像素点与groundtruth坐标中心的距离,距离groundtruth坐标中心点越近,score值越高。其中score的表达式如下:
32、
33、步骤4.4,计算最终的置信度s:首先,将步骤3.4-3.7中获得的特征图p1_out,p2_out,p3_out,p4_out分别输入predictionhead的四个检测头head的分类分支,分类分支通过四个卷积层进行特征增强,再使用一个卷积层来计算得到每点对应的类别即抬头和低头的概率p;再将步骤4.3得到的每点的score与每点的类别概率p,通过公式(2)来获得置信度s。
34、
35、步骤4.5,将步骤4.4得到的置信度s使用非极大值抑制(nms)来去除多个重复的检测框,用置信度最高的检测框作为最后的检测结果,获得学生课堂姿态行为即抬头和低头的分类。
36、本发明的有益效果是:
37、(1)本发明方法通过使用具有特征感知块注意力(feature perceptionattention,fpa)的transformer(fpa transformer)来对课堂上学生的抬头和低头行为进行检测分类。fpa transformer结构由backbone模块,fpp模块(featureperceptionpyramid,fpp),predictionhead模块三个模块组成:其中,backbone模块通过在fpb中通过加入局部特征感知多头注意力(local feature perception attention,lfpa),从而使backbone模块关注到课堂学生抬头低头行为的更多特征,来提高对学生课堂抬头低头行为特征的提取能力;fpp模块通过引进特征感知下采样(feature perceptiondown-sampling)对提取到的学生课堂行为进行选择性的特征融合,使其获取课堂学生行为更精细特征的能力也得到进一步加强;predictionhead模块通过加入阈值分支,来过滤低质量的检测框,进一步提高了fpa transformer网络对学生课堂抬头低头行为检测和分类的精确度。
38、(2)本发明方法相比较于一些基于深度学习目标检测网络来说,它可以提取更多学生课堂行为的特征信息,不仅可以很好的识别到小目标,而且可以在密度高,重叠严重的场景下对学生进行定位和正确识别学生的行为。
39、(3)本发明方法相较于一般的目标检测算法来说,本发明通过设计fpp模块,使其下采样过程不会丢失太多学生行为信息,这不仅可以保存学生行为的重要信息,还可以对后续的检测提供保障,从而提高检测性能,该方法能够在教室课堂学生密集环境下,实现对学生进行精准定位和对学生听课行为进行精确分类。
40、(4)本发明方法在检测阶段将分类和回归分支设为独立分支,并在回归分支和阈值分支共用一个分支来过滤低质量锚框,可以有效解决后排学生目标较小的问题,不仅提高了对较小目标学生的定位精度,也提高了所有学生的行为检测精度。
- 还没有人留言评论。精彩留言会获得点赞!